



ロードマップでわかる!当世プロセッサー事情 第633回
Ponte VecchioとIntel Arcに関する疑問をRaja Koduri氏が回答 インテル GPUロードマップ
2021年09月20日 12時00分更新

前回に引き続きインテルのGPUシリーズを解説する。17日、先日のArchitecture Dayに関するラウンドテーブルがあり、インテルのRaja Koduri氏ほかに直接質問をする機会に恵まれた。もちろん質問はGPUに関するものだけであるが、Ponte Vecchioに加えてIntel Arcに関しても質問できたので、これらの情報をアップデートの形でお届けしよう。

おなじみKoduri氏。他にRoger Chandler氏(VP&GM, Client Graphics Products and Solutions)とJeff McVeigh氏(VP&GM, Data Center XPU Products & Solutions)も参加した
Ponte Vecchioは行列演算が可能
まずPonte Vecchioに関して。連載632回で、「Matrix EngineはDP4A命令に代表されるAI/ML命令のみの処理が可能なのかも」と書いたが、実際には汎用的な行列演算が可能という話であった。
これはoneAPIや業界標準の、例えばマイクロソフトの提供する開発ツール経由で利用可能とのことで、AMXと互換性はない。oneAPI経由で見れば、AMXもXMXも同じように扱えるが、AMX命令がそのまま利用できるわけではない、との話であった。
おそらくスループットそのものはAMXの方が大きいと思われるが、その代わり演算ユニットの数はXMXの方が多いわけで、XMXを利用して大規模な行列演算などは現実的に可能と思われる。
実はすでにインテルのMKL(Math Kernel Library:算術演算ライブラリー)はoneAPI対応のoneAPI MKLがリリースされており、Ponte Vecchioを利用する場合にはこのoneAPI MKLを利用すればBLAS(Basic Linear Algebra Subprograms:と行列基本線型代数演算ライブラリー)はXMXを利用して処理可能になるわけだ。
NVIDIAのTensor Coreももともと行列演算が可能になっていたが、初代/第2世代は混合精度で、いわゆるFP32/64は未サポートなので、AI/ML処理には使えても科学技術演算にはかなり厳しく、精度が十分に取れないという制約があった。
ところがAmpereに搭載された第3世代のTensor Coreでは倍精度演算(DMMA:Double-precision Matrix Multiply-Add)がサポートされたことで、科学技術演算にも十分利用できるようになった。Ponte Vecchioもこれに匹敵する利用が可能かどうか現時点でははっきりしないが、少なくとも方向性は同じであることがわかった。
HPCにもレイトレーシングは必要
次にレイトレーシング・ユニット。連載629回で「HPC向けにレイトレーシングは本当に必要なのだろうか?」と書いたが、これについてはJeff McVeigh氏がはっきり「必要だ。例えば大規模なシミュレーションの結果の可視化などで利用される。レイトレーシングの技術も進化しており、単に高速でというだけでなく、超高精画質を得る方向性もある。単に可視化のみならずコンテンツ制作やAI/MLなどでも利用される可能性がある」とした。

Xe Coreごとにレイトレーシング・ユニットが搭載されている。シミュレーション結果の可視化や超高精画質などに利用するため、HPCにもレイトレーシングは必要とJeff McVeigh氏は語る
また連載632回で書いた“PVC 2T”についても「われわれは異なるパワーエンベローブに対応するために、1タイルのPonte Vecchioを提供する予定がある」との返事をもらった。
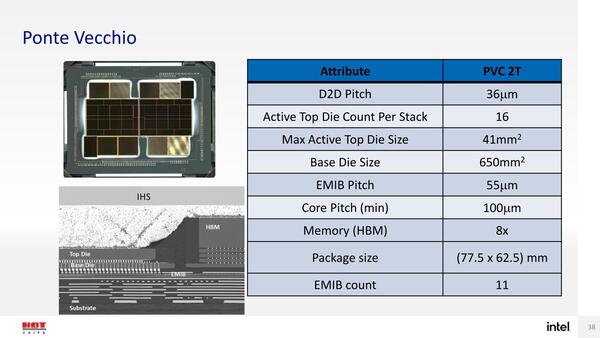
表に“PVC 2T”と書かれている。“2T”ということは、“1T”や“4T”があっても不思議ではないが、それが明言されたことになる。実際、Ponte VecchioのPVC 1Tを作るのはかなり容易だ
まだPonte Vecchioは細かなスペックが出ていないが、一説にはPonte Vecchio OAMは1個で消費電力が400Wを超えるという。これは実際載っているモジュールと性能を考えれば納得できる数字である。

左端のモジュールがPonte Vecchio OAM。これ1個で消費電力が400Wを超えるらしい
下の画像を基にすれば、1タイルでも22TFlopsを超える性能を持ち、しかも300W未満の消費電力なので、そうしたニーズは多くありそうに思える。

1.4GHz駆動では実際の処理性能は45.87TFlopsほどになる。1タイルでは22TFlopsを超える性能ということになる
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ















の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















