



ロードマップでわかる!当世プロセッサー事情 第629回
Intel Architecture Day 2021で発表された11のテーマ インテル CPUロードマップ
2021年08月23日 12時00分更新

Xe HPC&Ponte Vecchio
まずPonte Vecchioの設計目標が下の画像だ。FP64性能、AI性能、メモリー帯域のいずれも、これまでインテルが提供してきた性能(青線)は、業界標準(緑線)に追いついてこなかったが、ここで一気に追いつきたいわけだ。
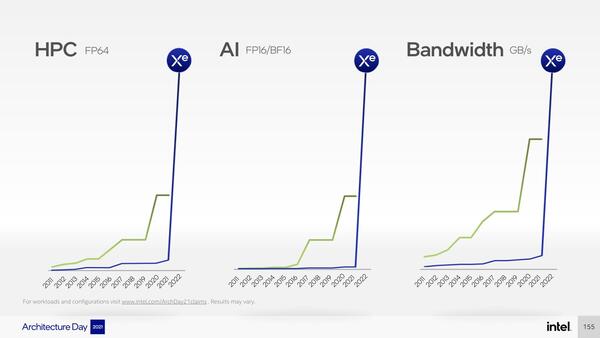
Ponte Vecchioの設計目標。インテルが業界標準に追いつかなかったのはKnights Landingをキャンセルしたからでは? という突っ込みを入れたくなる
さて、これを実現するためのコアであるが、Vector Engine/Matrix Engine共に、Coreあたりの数は8つに減っている。ただし、Vector Engineは512bit、Matrix Engineは4096bitと2倍/4倍に増えている。Xe HPGに比べて、より演算性能を引き上げた格好だ。

エンジンの数を8つに減らしたのは粒度を上げるためだろうか?

Matrix EngineはXe HPG同様、主にAI処理向けと考えられる
この結果、Coreあたりのベクトル演算性能はFP32/64で256 Ops/サイクル、Matrix演算性能はInt 8だと最大8192 Ops/サイクル、FP16/BF16でも4096 Ops/サイクルである。このXe Coreを16個まとめたものをスライスと呼び、さらにスライスを4つ(つまりXe Coreを64個)集積したものがスタックである。

ちなみに、なぜかレイトレーシングユニットまでXe Coreごとに搭載されている理由が良くわからない。汎用サーバー向けのXe HPはまだわかるのだが、HPC向けにレイトレーシングは本当に必要なのだろうか?
Ponte Vecchioは、このスタックを2つ搭載した格好になる。それぞれのスタックには最大8本までリンクが出るXe Linkという、要するにルーターが搭載されており、これで最大8つまでのスタックが密結合で動作する格好になる。

Ponte Vecchioは、スタックを2つ搭載する。物理的にこの2つのスタックは別々のダイ(スライスごとに別ダイ)であり、間はXe Linkで接続される格好になる
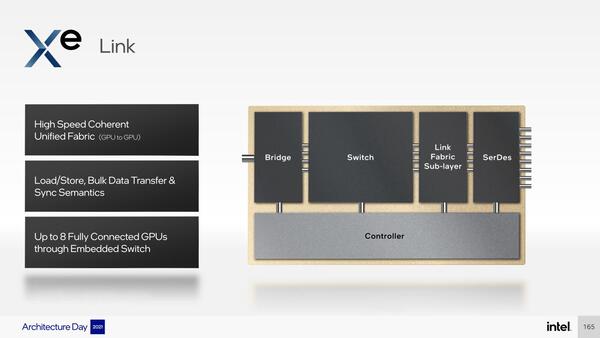
それぞれのスタックにXe Linkを搭載する。この構造そのものは珍しくないし、8本のリンクも他に例がないわけではない。現時点ではリンクの速度や帯域、レイテンシーなどは不明だ

8つのスライスの相互接続ならリンクはスライスあたり7本で十分であり、残る1本の用途が不明である。将来の拡張用だろうか?
さて、Ponte Vecchioの物理実装が下の画像だ。連載627回の最後の写真でも触れたが、合計47タイルからなる。

Ponte Vecchioの物理実装。Compute TileとRambo Cache、Base TileはFoverosで接続され、HBM2やXe LinkはBase TileとEMIBでつながる格好になる
内訳は以下の通り。
- Compute Tile×16
- Rambo Cache×8
- Xe Base Tile×2
- EMIB×11
- Xe Link×2
- HBM2e×8
1スタックあたりに換算すると以下の通り。
- Compute Tile×8
- Rambo Cache×4
- Xe Base Tile×1
- EMIB×5(おそらくHBM2e用×4+Xe Link用×1)
- Xe Link×1
- HBM2e×4
これとは別にスタック同士の接続にEMIB×1が使われる。このPonte Vecchioは1つ(=2スタック)でFP32が45TFlopsとされる。2 Stack=8 Slice=128 Xe Coreだから、処理性能は32768 FP32 Ops/サイクルになる。トータル45TFlops以上、ということは動作周波数はおおよそ1.4GHz程度と推定されることになる。競合製品との違いは、FP32/FP64が同じ性能なことだ。

1.4GHz駆動では実際の処理性能は45.87TFlopsほどになる。ちなみにNVIDIA A100がFP64 9.7TFlops/FP32 19.5TFlopsだから、FP32比で2.4倍弱、FP64だと4.7倍ほど高速という計算になる
ちなみにこれは2スタックでの構成だが、実際のCompute Bladeはこれを4つ組み合わせ、3つ前の画像の構成を取った物が基本ということになる。実際にAuroraに納入予定のモジュールも示された。

Xe LinkはあくまでこのSubsystem上のOAM同士の接続に使われる

Auroraに納入予定のモジュールは、Ponte Vecchio x4 Subsystem+2S Sapphire Rapidsの構成そのままだが、水冷配管がなされている
ということで、これでも随分省いて説明したにも関わらずこの文量である。もう少し深い話を次回以降、順次お届けしたい。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ
















&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")












ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












