




前回までのHot Chips 2025レポートは、純粋なCPUを紹介してきたが、今回からいろいろ変化球的なものを取り上げていく。まずはインテルのIPU「E2200」である。

写真はIntel IPU Adapter E2100。今回説明するのは後継機種のE2200だ
IPU(Intelligence Processing Unit)そのものの説明は、インテルの初代IPUであるMount Evansの説明を連載634回でしているので今回は割愛したい。要するにインフラ向けプロセッサーである。
データセンター向けのインフラ処理専用プロセッサー
Intel IPU Adapter E2200
Mount EvansはIntel IPU Adapter E2100という名称で2024年から出荷を開始しているが、今回紹介するE2200はその後継機種となる。後継機種なので、当然同様の機能を提供することになる。下の画像が全体のブロック図であるが、これはE2100のブロック図と非常によく似た構造である。ただし性能が大幅に向上している。

E2200の構造。E2100と構造が一緒なのは、基本構成を変える必要はなかった、ということなのだろう。Mount EvansはTSMCのN7での製造だったはずだが、さてE2200はどうなのだろう? 順当に考えればTSMC N5あたりだろう
上の画像を見ても、E2200はE2100の倍のスループットを処理できる性能を持ち合わせているらしいことは容易に想像できる。理由は以下のとおり。
- PCIeのSerDesが、E2100はPCIe Gen4×16なのが、E2200はPCIe Gen5×32に強化されている。
- イーサネットは、E2100が200G MAC/56G SerDesなのに対し、E2200では400G MAC/112G SerDesに速度が倍増している。E2100が50G×4構成の200Gイーサ対応なのに対し、E2200は100G×4の400Gイーサ対応になっている。
- Compute Complexは、E2100が最大16コアのNeoverse N1コア(最大2.5GHz駆動)なのに対し、E2200は最大24コアのNeoverse N2コアに強化されている(動作周波数は未公開)。
- 外部メモリーはE2100が3chのLPDDR4(最大48GB)なのに対し、E2200はLPDDR5-6400×4chに強化されている。
残念ながら今回具体的な性能に迫る数字は公開されなかった。その代わりといってはなんだが、E2100のときにはあまり説明されなかった細かい実装内容の説明があった。
IPUを利用する目的は、単なるイーサネットカードの枠を超えて、さまざまなネットワーク構成を自由に構成できるようにするためのものである。
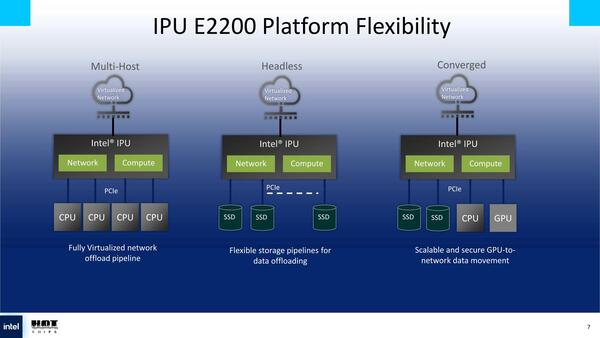
IPUならば、さまざまなネットワーク構成を自由に構成できる。Multi-HostはPCIe x32では2×16構成なので、2つのノードへの接続が精一杯だろう。そのノードがコア数144や288の2ソケットのXeonなら、インスタンス数としては十分ということかもしれない
Multi-Hostは、それこそクラウドサービスのCPUインスタンスに相当するもので、HeadlessはSAN(Storage Area Network)のようなネットワーク・ストレージの構成を可能にする。Convergedが一番スタンダードな使い方だが、要するにコンバージド・ネットワークをIPUを使って簡単に構築できるわけだ。
ここからはもう少し細分化していこう。まずは、記事冒頭の画像で左側に位置するNetwork Subsystemについてだ。Network Subsystemの最上位はPCI Expressで、その下にRDMA/NVMe/LANを処理する専用ブロックが置かれているのはE2100と同じ(もっとも個々のユニットの処理能力は倍増しているだろう)。
その下にあるPacket Processorの構造が下の画像だ。このPacket Processorが、E2100とE2200の核となる部分である。

Packet Processorの構造。インテルにとってPacket Processorはこれが最初ではなく、1998年にDECとの特許訴訟の結果として買収したIXPというNetwork Packet Processorが存在する。ただこれも結局インテルは放棄しており、IXPシリーズはNetronomeという企業がその資産をすべて買収した
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ











、バッテリー駆動時間は13時間超え。もう欲しくなる要素しか見つからないッ!")








ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")
















