




記憶密度が上がると
速度と寿命が低下する
では記憶の読み込みはどうかというと、コントロール・ゲートに5V程度の電圧をかけてやればいい。もしフローティング・ゲートに電子が蓄えられている状態だと、ここでソース→ドレインの間に電流は流れない(図5)。
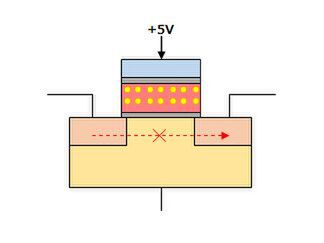
図5 読み込み時はコントロール・ゲートにわずかな電圧をかける。フローティング・ゲートに電子が蓄えられていると、ソース→ドレインの間に電流は流れないため、値は0になる
ところがフローティング・ゲートに電子がない状態だと、ソース→ドレインの間で電流が流れることになる(図6)。これにより、値が0か1かを読み出すことが可能になったというわけだ。
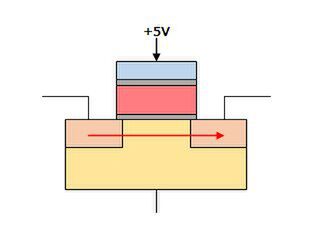
図6 フローティング・ゲートに電子がないと、ソース→ドレインの間に電流が流れるため、値は1になる
この構造がSLC(Single Level Cell)と呼ばれる方法だが、より記憶容量を引き上げるため、多値化を図ることになった。
具体的には、電子をフローティング・ゲートに入れる際に、0か1の2段階ではなく0~3の4段階にすることで、2ビット分のデータを保持できるようにするMLC(Multi Level Cell)、さらに0~7の8段階にすることで3ビット分のデータを保持できるようにしたTLC(Tri Level Cell)という技術が導入される。
これによって記憶密度は飛躍的に引きあがるようになったのだが、反面速度と寿命が急速に劣化することになった。もともとフラッシュメモリーの場合、SLCであっても寿命がある。これは、本来トンネル酸化膜に電圧をかけて電子を注入したり引き抜いたりしているわけだが、これを繰り返すとトンネル酸化膜に格子欠陥と呼ばれる絶縁不良の箇所が発生し始める。
この欠陥がトンネル酸化膜を貫通してしまうと、フローティング・ゲートの中の電荷が駄々漏れ状態になり、これ以上記憶状態を保持できなくなる。SLCの場合、この書き込み寿命は数万回~数十万回とされる。
MLC/TLCではなにが問題かというと、いきなり目的の量の電荷をきちんとロードするのは難しいので、例えばMLCで3という値を保持させるなら、まず2を保持させ、そこに1を足す形になる。つまり書き込みの回数が2倍になる。TLCなら4/2/1という3回に分けて書き込み(電荷の継ぎ足し)を行なうことになる。これには次の問題がある。
- 書き込みの時間が原理的に2倍(MLC)あるいは3倍(TLC)かかる。実際には、もうすこし遅くなる。
- 書き込み寿命の減少。MLC/TLCの場合、短期間に複数回の書き込むので、トンネル酸化膜の劣化が加速化する。回数だけで比較すれば、MLCはSLCの2倍、TCLは3倍の書き込み頻度になるので、その分書き込み寿命が2分の1/3分の1になる計算だが、実際にはMLCはSLCに比べて1桁、TCLは2桁書き込み寿命が減少する。
特にこの寿命の問題はMLC/TLCの構造的なものに起因するため、根本的な解決は難しく、結果としてMLC/TLCを利用するときには代替領域、あるブロックが使えなくなった時に、そのブロックを代替する目的で最初から用意されているブロックを多めに準備するなど、ウェアレベリングを強化して特定の領域への書き込みの集中を避けるといった程度の対策しかない。
フラッシュメモリーは微細化すればするほど
エラーの頻度が増加する
さて、話をもうすこし微細化に進めてゆく。先ほどNANDとNORでは配線が異なるという話をしたが、例えばセルの等価回路を図7のように表記した場合、NANDの回路構造は図8のように示される。
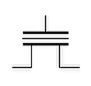
図7 セルの等価回路図
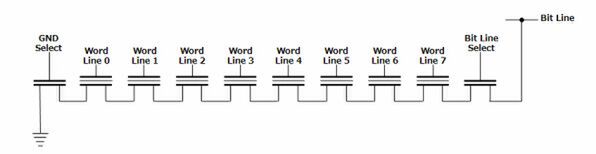
図8 NANDの回路構造
NORフラッシュの場合は、セルの1個ごとにGND/Bit Line向けの配線が用意されるが、NANDフラッシュはある程度まとめた状態で構成される。これによりセル同士を隣接して構築できるので、NORに比べて高密度に実装しやすいという話である。
ではこのまま、さらなる容量増加を求めて微細化するとどうなるか、というのが次の話だ。例えば図8で、Word Line 1に電荷を継ぎ足ししようとすると、隣接するWord Line 0/2のセルにも影響を及ぼしやすい。
それでもSLCでは、値が0か1しかないためまだマシだが、MLC/TLCになると継ぎ足す電荷量が小さいため、隣接するセルの電荷量が変化してしまうことになる。
これは以前から問題になっていたことだが、プロセスを微細化するとセル同士の間隔が物理的に短くなるから、より影響を受けやすくなっている。この結果として、高密度化するNANDフラッシュには強力なエラー訂正が必要になった。
このあたりはSSDの動向を見ているとわかるが、最初はパリティー程度だったのがすぐにECCを搭載するようになり、そのECCのビット数がどんどん増えていった。最近はついにLDPC(Low Density Parity Code:恐ろしく計算に手間がかかる代わりに強力無比なエラー訂正手法)を搭載するとかしないとかの話になりつつあるのは、微細化にともなうエラー頻度の高さを物語っている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ














&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")


















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












