




東芝とサムスンが、3D積層で容量問題を解決
課題はやはりコスト面
ということで長い前置きが終わって、やっと本題である。下の画像は2013年に東芝が示したロードマップである。NANDフラッシュの場合、東芝とサムスンが2強の存在にあり、両社で全世界の過半数(年度によってばらつきはあるが、合わせておおむね60%強)のシェアを占めている。
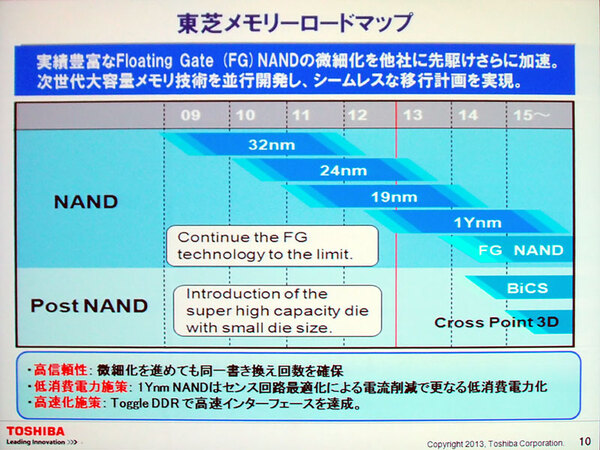
東芝が示した2009年以降のロードマップ。2014年くらいまではフローティング・ゲートでいくが、その後はBiCS(Bit Cost Scalable)という3D構造が並行して出てくる予定である
両社はほぼ同じタイミングで同じようなテクノロジーを導入しつつあり、そんなわけで東芝かサムスンのどちらかのロードマップを見れば、ほぼ業界全体のトレンドを代表していると見て間違いではないのだが、その東芝は以前から10nm世代でがんばるという話をしていた。
具体的には1X・1Y・1Zという3つのプロセスノードを10nm世代で提供するという。その最初のもの(1X)が19nm世代で、これに続き現在1Y(16~17nm)世代に取り組んでおり、さらにその後には1Z(14~15nm)程度まで微細化することを以前から表明している。
ただ、例えば19nmのものを17nmに微細化したところで、面積比では20%程度の削減にしかならない。15nmまで削減してやっと40%といったところで、同じダイサイズで2倍の容量というのは結構厳しい。
というのは微細化をした分、ECCやLDPCに利用する分や、代替ブロック領域に利用する分も増えるため、カタログ上では容量倍とかいいつつ、実際には1.5倍にもならない、なんてことがしばしば発生するためだ。
またDRAMと同じく、こちらも微細化するとフローティング・ゲートの体積が段々厳しくなってゆくため、これ以上微細化するのが困難とみなされつつある。
TLCまでは実現したものの、これを超える多値化(4bit/Cell以上)は現実問題として困難であり、これもあってロードマップにすら出てこない。
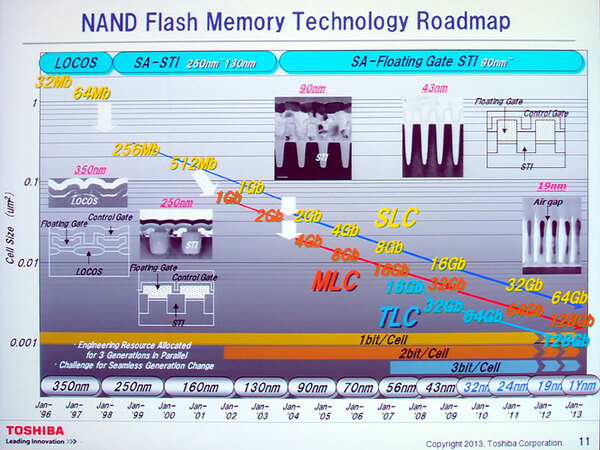
こちらはもうすこし長期のロードマップ。MLCが登場したのは2002年頃、TLCが導入されたのは2007年頃になる。さすがに4bit/Cellは論外とされている
その一方で、より大容量のNANDフラッシュを求める声は常に出てきている。これに対して2012年頃から東芝とサムスンが示しているのが3D積層である。前回紹介したDRAMの積層とは異なり、こちらはあらかじめ3次元にフラッシュセルを積層してからパッケージングするというものである。
この3D積層そのものはサムスンがやや先行しているが、サムスンの第1世代の3D積層製品は1Y/1Z世代のフラッシュで競合できると東芝は見なしている。
とは言ってもサムスンの第2世代以降は、東芝もBiCSという3D積層が必要という考え方だ。実際に東芝は2014年5月のプレスリリースで、3D積層メモリー専用工場の建設を発表している。
3D積層によって解決するのは、容量の問題である。例えば1Xとは言わなくても24nm世代のフラッシュを4層以上積層すれば、それだけで256~512Gbitのフラッシュメモリーが作れることになる。

3D積層によって容量問題が解決する。ただし3D積層はすべてに利用できるわけではない
東芝が2008年に発表した論文(PDF)ですら、すでに4層の試作に成功しており、2009年の論文(PDF)と2011年の論文(PDF)では16層のテストチップの試作とその評価をすでに公表している。もちろん試作と量産ではいろいろ違いはあるが、DRAMのTSV積層よりも量産の可能性は高いとされる。
東芝の資料ばかりでは偏ってしまうので、今度はサムスンの資料を見てみよう。204年にサムスンが発表したV-NAND(Photo04)を見ると、こちらは26層(NANDセルが24層で、前後に制御層が1層づつ)を積層し、128Gbitを実現している。
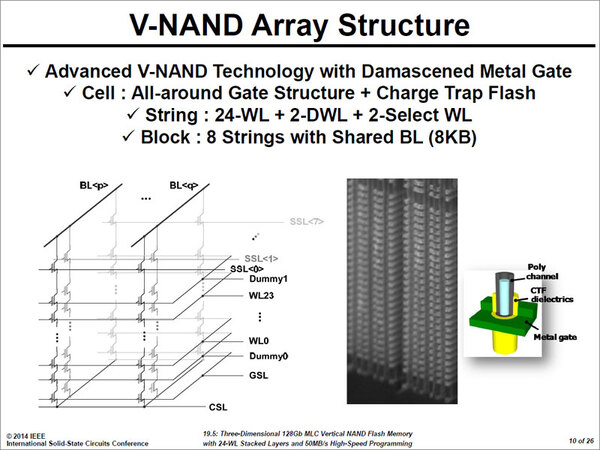
サムスンが発表したV-NANDの仕組み。2014年2月にISSCCでサムスンが発表した資料より
こちらは量産製品を使っての発表であり、容量が控えめなのは最初の製品だからと考えれば納得できる。ただ技術的にはもっと容量を引き上げることは難しくなく、サムスン自体もこれで1Tbit NANDまでのロードマップは見えたとしている。
そんなわけで、ますます高まるNANDフラッシュの大容量化への筋道は立ったのだが、問題は価格である。3D積層の場合、見かけ上のダイサイズは変わらないまま大容量化できているように見えるが、実際は積み重ねているので、製造に必要になるダイ全部の面積は容量に比例して増える。
当然コストは面積に比例するため、大容量化しても価格が下がらない。DRAMほどではないにしても、積層化するためのコストが追加されるわけで、容量単価は今後下がる見通しがあまり立っていない。
それもあって、現在NANDに代わる新しい不揮発性メモリーを各社ともあれこれ検討している。これは「長期的に」フラッシュよりも低価格で大容量なメモリーの需要が高まるからであり、短期的にはこれを満たす解がないことをすでに業界は理解し、受け入れつつある。
今後もNANDの開発は進むが、それはもっぱら3D構造に関わる部分であり、プロセスの微細化そののものはすでに止まっている。したがって価格低減は別のところ、例えばプロセスを大型化したり、TLCからMLCにすることで寿命を延ばしたり、エラー頻度を下げるなどして代替ブロックやエラー処理機構を減らすかたちで原価を抑える方向になりつつある。
ロジックより先に、微細化の限界にたどり着いたNANDフラッシュの動向は、当然ロジックにも影響をおよぼしつつある、というのが現在の状況である。そんなわけで、次回はロジックの話である。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ










が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")

















