




ここまで16回かけて、プロセスの過去から現在、未来までを解説してきた。このシリーズの最後として今回から数回にかけて、近未来のプロセスの展望について説明したい。その1回目は、DRAMだ。

微細化ではなく高密度化で進化した
DRAMの構造
なぜDRAMかというと、以下の理由により現在のプロセスの限界をより明確に示せると思うからだ。
- DRAMの場合、市場からのコスト削減と容量増加の両方の要求が強く、この結果Logic Processにも増して早いタイミングでプロセス微細化に取り組んできた。この結果、Logicより先に壁にブチあたった。
- 次回紹介するNAND Flashは3Dに向けて突き進んでいるが、DRAMはまだ足踏みしている状態。
- 10nm未満の展望が全然見えない。
この連載では基本的にLogic Processをメインに取り上げてきたので、DRAMの構造はほとんど説明していない。ということで、非常に簡単にDRAMの構造をまずは紹介しよう。
図1が、DRAMの基本的な構造である。Bit LineとWord Lineという交差するアドレス信号線があり、その交点にFETが1つ配され、そのFETにはコンデンサーが直列でつながるという構造である。
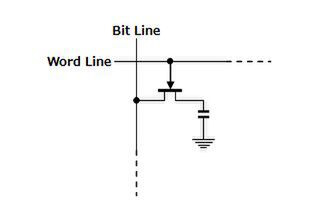
図1 DRAMの基本的な構造
まずは読み出しだ。コンデンサーに電荷が蓄えられている(値=1)状態では、Word線に電圧がかけられると、コンデンサーから電荷がFETを経由してBit Lineに移動するので、電圧変動が発生する。
これにより、値が1なら読み出せる。逆にコンデンーサが空(値=0)だと、Word Lineに電圧をかけても電荷が移動しないため、Bit Lineの電圧変動がない。これにより値が0と判断できることになる。
書き込みは逆で、Word Lineに電圧をかけた状態でさらにBit Lineに電圧をかけると、電荷がFETを経由してコンデンサーに流れ込み、電荷がチャージ(値=1)され、Bit Lineに電圧をかけないと、電荷が移動しないためコンデンサーは空のまま(値=0)となる。
これでわかる通り、DRAMは一度読み出しをすると、中身が空になってしまう。そこで一度読み出しを書けたら、同じ値を書き戻す作業(プリチャージ)が必ず必要になる。
また、コンデンサーの容量は非常に小さいので、時間が経つと電荷が勝手に流れ出してしまい、コンデンサーの中が0になってしまう(揮発する)。これを補うために、定期的にDRAMの中身を読み出して、また書き戻す作業(リフレッシュ)が必要になる。
それでは微細化の話をしよう。図2は、DRAMの構造を横から見たものだ。DRAMの構造には、スタック型とトレンチ型という2種類があり、図2はトレンチ型を示したものだ。もっとも構造はスタック型とトレンチ型は上下がひっくり返っているだけなので、ここではトレンチ型を説明しよう。
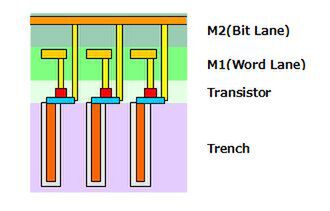
図2 DRAMの構造を横から見たもの
図2の一番下にあるのがトレンチ(溝)である。これはSi(シリコン)の中に溝、というより井戸のようなものを掘り、そこに絶縁層のカバーをつけた状態で金属を流し込み、これをコンデンサーとして利用する。
そのトレンチの上にトランジスタ(FET)を積層し、そこから配線を2つ引っ張り出す。ひとつがWord Line用で、もう1つがBit Lane用だ。
最近はほとんどがスタック型である。というのは、微細化が進んだことにより「細い溝を深く掘る」のが難しくなっており、むしろ先に配線とトランジスタを積層した上に、Trench状の構造を積層する方が楽という事情によるものである。
さて、この状態でプロセスの微細化が進むとどうなるだろうか。当然ながら図2ではトランジスタ同士の間隔が狭まることになるため、トレンチの幅は狭まる。
ところがTrenchはコンデンサーの役割を果たしており、コンデンサーがまともな仕事をするためにはある程度の体積が必要である。例えば100ns程度で揮発してしまうと、DRAMとして使い物にならないため、もっと長時間保持できないといけないからだ。
幅が狭ければ高さを増すしかなく、要するにトレンチの深堀りが必要になる。これがある程度まで行くと猛烈に難しくなるため、トレンチ型が廃れてスタック型が普及するようになったわけである。
そうは言っても高さを引き上げるのは限界がある。最近では幅と高さの比が1:20を超えており、これはこれで色々と難しい問題が出てくるようになった。そこで、プロセスの微細化をしなくても高密度化を行うという方策が考え出されるようになった。
従来のDRAMの場合、セル(1bit分の記憶領域)のサイズは俗に8F2という構成だった。図3がこの模式図である。先ほどの図2はDRAMセルを横から見たものだが、今度は上から見たものだ。
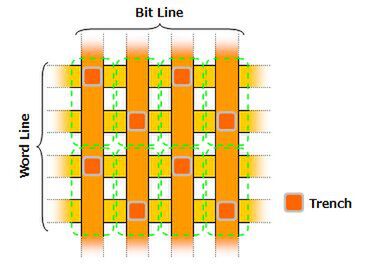
図3 セルの模式図
この図で緑色の破線で囲った部分がセルに該当する。セルの寸法は、配線(Bit Line/Word Line)の幅を2Fとした場合、2F×4F=8F2になることから、この名称がついている。
では、これを高密度化するにはどうすべきか、ということで次に投入されたのが、Word Lineの方向を若干詰めた6F2の構成(図4)である。これにより、33%ほどセルサイズが縮小された。つまり同一のダイサイズなら、より記憶容量を引き上げられるようになったわけだ。現在は、この6F2の構造が主流である。
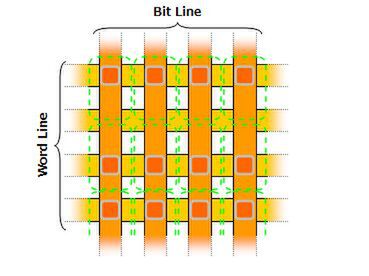
図4 Word Lineの方向を若干詰めたセル構成
これに続きDRAM業界は、さらに高密度化した4F2(図5)の構造を現在検討中である。この構造だと、8F2と比較して倍の密度が提供できるため、プロセスの微細化が鈍化した状況では非常に魅力的である。
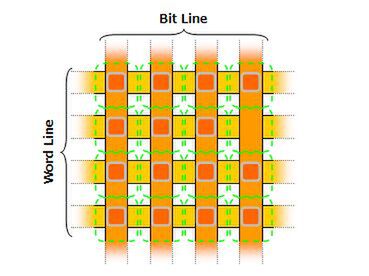
図5 DRAM業界は、さらに高密度化した構造を検討中
ここまでが前提知識である。では実際にはどうかという話を次のページで説明しよう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 -
第872回
PC
NVIDIAのRubin UltraとKyber Rackの深層 プロトタイプから露見した設計刷新とNVLinkの物理的限界 -
第871回
PC
GTC 2026激震! 突如現れたGroq 3と消えたRubin CPX。NVIDIAの推論戦略を激変させたTSMCの逼迫とメモリー高騰 -
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 - この連載の一覧へ






















ディスプレーが3万円台! 超高解像度な3:2画面で仕事がはかどりまくること間違いなし")



















