



ロードマップでわかる!当世プロセッサー事情 第796回
Metaが自社開発したAI推論用アクセラレーターMTIA v2 Hot Chips 2024で注目を浴びたオモシロCPU
2024年11月04日 12時00分更新

2週空いてしまったが再びHot Chips 2024で注目を浴びたオモシロCPUに戻る。第7弾は、MetaのMTIA v2である。初代であるMTIAは連載730回で名前だけ出てきたが、内部についての説明はしていないので、まずはここから話をしたい。
RISC-Vベースだが限りなく専用プロセッサーに近い
AI推論用アクセラレーターMTIA v1
MTIA v1は2023年に発表された。目的は推論処理の高速化であり、特に同社のサービスのRecommendation EngineをGPUベースから置き換えることを目的としていた。

MTIA v1。開発開始は2020年とのこと
製造プロセスはTSMCのN7で、800MHzで動作。INT 8で102.4TOPS、FP16で51.2TFLOPSの性能を持つとされる。
MTIAのダイ。TDPは25Wとのこと。ダイサイズやトランジスタ数は公開されていない
内部構造は下の画像のようになっており、中央に8×8で合計64個のPE(Processor Element)が配される。PEの内部構造そのものは未公開であるが、おのおののPEには2つのRISC-Vベースのコアが搭載され、片方にはVector Engineも搭載されている。
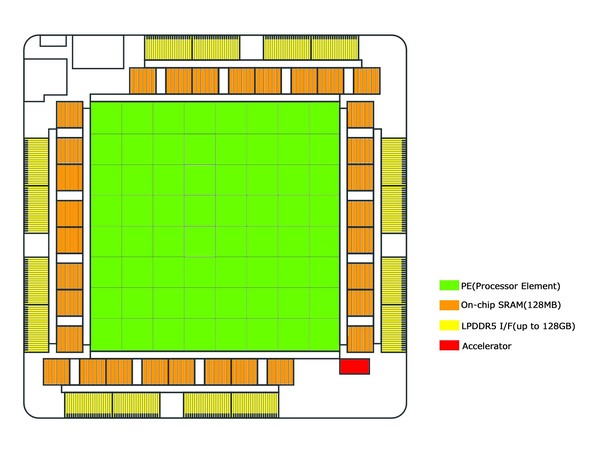
MTIAの内部構造。元の図はMeta提供。着色と脚注は筆者
また行列の乗算と加算、データ移動、非線形関数(アクティベーション用と思われる)のための専用命令が追加されているそうで、RISC-Vベースとは言え限りなく専用プロセッサーに近い。おそらくはVector Engineを搭載しているコアには行列の乗加算や非線形関数のアクセラレーターが搭載され、こちらが演算処理を行なう。
もう一方のコアはデータ移動のアクセラレーターが搭載され、これが処理の制御であったり、ほかのPEとのデータ移動だったりをつかさどるものと思われる。64PEでINT 8で102.4TOPSなので、1PEあたり1638.4GOPS。800MHz駆動だから1サイクルあたり2048 Opsという計算になる。
これをVector Engine(つまりSIMD)だけで実装しようとすると巨大なSIMD(16384bit幅!)が必要となるが、どうもこの102.4TOPSは行列乗算(俗に言うTensor Engine)の結果と思われるので、そこまで大規模な回路でなくてもなんとかなりそうだ。これに加え、各PEには128KBのSRAMが搭載されており、スクラッチパッドのように利用可能なものと思われる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第886回
PC
CFETの足を引っ張るPMOSを救え! imecが提案する新絶縁層と、あえて精度を緩める「Notch Alignment」の妙手 -
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 - この連載の一覧へ











、バッテリー駆動時間は13時間超え。もう欲しくなる要素しか見つからないッ!")








ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")















