



新清士の「メタバース・プレゼンス」 第39回
画像生成AI「DALL·E 3」の性能が凄まじい。これを無料で使わせるマイクロソフトは本気で競合をつぶしに来ている
2023年10月16日 07時00分更新

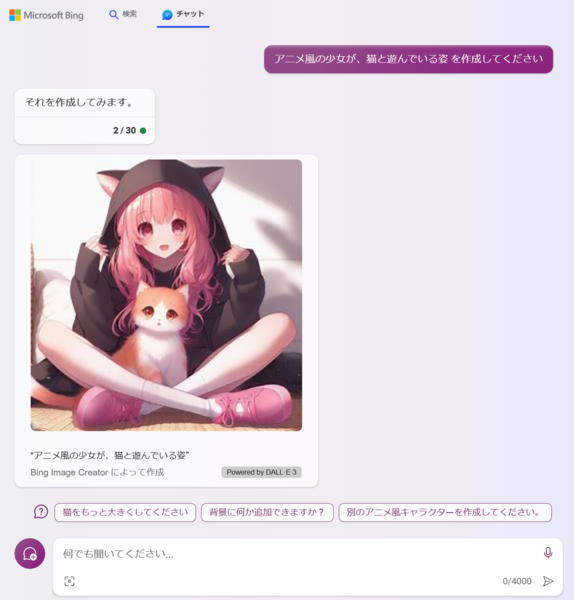
Bingチャットの画面
10月1日頃、OpenAIの新しい画像生成AI「DALL·E 3(ダリ3)」が徐々に使えるようになり、その性能の高さから話題になっています。まずサプライズで使えるようになったのがマイクロソフトのBingチャット。日本語で「猫の画像を作ってください」などと入れるだけでかわいい猫の画像が出てくると。これが無料で使えるのは衝撃的です。マイクロソフトが巨大資本で他の会社をつぶしに来たなという感じですね。どう考えても、今のところはサーバーコストが果てしなくかかる赤字サービスなのは間違いないので……。
「ラーメンを食べる女の子」が描ける!
なにより衝撃的だったのは、「アニメ風の少女と猫が遊んでいる姿を作ってください」というリクエストに対し、一発で完璧な正解を出してきたことです。Stable Diffusionだと苦手とされていた指も適切に描写されています。もうひとつの着目点はオブジェクト間の関係性ですね。Stable Diffusionでは「猫と紐」、「少女と紐」などの関係性が破綻しやすいので、それが破綻なく、バシッと出てきたことに「おおっ!?」と驚きました。

Bingチャットを通じて、マイクロソフトImage Creater(DALL·E 3)で生成した「アニメ風の猫と少女が遊んでいる絵」(以下、画像は筆者作成)
さらにチャットで「これをリアルにしてください」と言うと、それにもすぐに対応してくれました。日本語で指示するだけで、Bingチャット側が適当にプロンプトを作ってくれるわけです。「背景を雨にしてください」「映画風のワンシーンにしてください」「日本風の背景にしてください」など、次々に指示を加えていっても、それに合わせてプロンプトを修正して、新しい画像を作り続けてくれる。チャットという対話で作り込んでいくので、非常に簡単です。

画風をリアルにして、猫だけで背景を雨で映画のワンシーンに、背景を日本風にして傘を指した少女を立たせて、といろいろ注文していくが、それに対応して、画像が作られていく
画像サイズは1024×1024ピクセルで、競合「Stable Diffusion XL」の基本サイズと同じ高解像度。ただし、Bingチャットで生成できるのは今のところ正方形だけです。
SNSでもさっそく様々なユーザーが色々と試している様子が出てきますが、なかでも話題になっていたのは「ラーメンを食べる女の子」ですね。Stable Diffusionなどでは苦手とされていたモチーフですが、DALL·E 3はしっかり食べてくれる。やはり、ラーメンの麺や指といったものの関係性がうまく描写されているようです。

それなら意地悪しようということで女の子をサイボーグにしてみましたが、ちゃんと食べてくれました。さらに体を半透明にして、虹色に光らせてくださいと指示をしても大丈夫。おまけに背景をサイバーパンクにしてくれと言ってもついてきてくれました(笑)。これはすごいなと。

サイボーグにして、猫耳の半透明の体にして、サイバーパンクの背景に……と追加指示していったもの。丼の大きさなど少し不自然な点は出ているが、それでも、ラーメンを食べる姿は維持されている
一方、Stable Diffusion XLはどうかというと、相変わらず麺と箸がぐちゃぐちゃに混ざっている。ラーメンの形状もちょっとあやしい感じで、背景のラーメン屋も破綻しているような気がします。圧倒的な性能差を見せつけられました。画像生成AIではこれまでここまでしっかりとオブジェクト間の関係性を表現できたツールはなったように思います。

Stable Diffusion XLが生成できる「Fooocus」を使って、「ラーメンを食べるねこみみサイボーグがいるサイバーパンク」の同じプロンプトを使って生成した画像。麺と箸の取り違いや、指の混乱など不自然な点が目立つ
DALL·Eが高性能なのは「関係性」を予測するから?
なぜDALL·E 3はこんなに性能が高いのか。その点については、とーふのかけらさんという方が、OpenAIの公開している技術論文を読み解いた解説記事を公開してくれています。
記事によれば、Stable Diffusionのような画像生成AIは基本的に、エンコードのときノイズを増やして、単語に紐付けている。デコードのときは特徴点空間のなかから特徴的なワードを出しているだけなので、関係性が存在していない。そのため、画面に登場する構成物をそのまま描写してしまい、ぶつ切りの状態になってしまうと。
一方、DALL·Eは学習のプロセスは似ているんだけど、画像を生成するときに「コーギー犬が炎を上げるトランペットを演奏している」といったテキストの場合、まず、可能性空間のなかで、文章からオブジェクト同士の関係性がどのようなものなのかを予測をさせて、抽象的な概念図的なものを作らせたうえでデコードをかけて画像にしていく。それによってモノとの関係性が的確に生成できるようになっていると。そのためプロンプトに忠実で、かつ、オブジェクト同士の関係性が整理された最終画像になるという仕組みのようです。
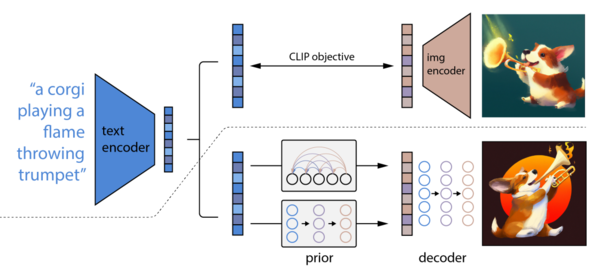
DALL-Eの処理方法の概念図。上が学習のやり方と既存の方法による生成プロセスで、下がDALL·E 3が採用している生成プロセス。上は、単語を分析してそのまま画像にしているが、下は、生成時には、まず言葉を分析して、それぞれの関係性を予測させてから、画像を生成している(OpenAIのDALL-Eの理論的な基礎を解説している論文"Hierarchical Text-Conditional Image Generation with CLIP Latents"より)
ただし、弱点もあり、「(プロンプトを正確に描写する)写実性が向上することで、逆に独創性が低下してしまう恐れがある」という点があるようです。まだ条件ははっきりしないものの、プロンプトが類似している場合には、構図や絵柄なども似たような画像が出る傾向がある可能性があります。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第165回
AI
AIがBlenderを勝手に操作 3D制作のハードルが一気に下がった -
第164回
AI
AIはすでに、私たちの心を内部で再現しているのかもしれない -
第163回
AI
無料の画像生成AI「Krea 2」が話題 実写もアニメもこなす新勢力 -
第162回
AI
ローカルAIで“しゃべる推理ゲーム”を作ったら、思ったよりちゃんとゲームになってきた -
第161回
AI
わずか3日で停止された新AI「Claude Fable 5」は何がすごかったのか -
第160回
AI
寝不足になるほど面白い ローカルAIと音声合成をつないだら、キャラが普通にしゃべり始めた -
第159回
AI
AIを使える人と使えない人で、とんでもない差が出ると実感した理由 -
第158回
AI
SDXLの次はこれ? アニメ特化のローカル画像生成AI、驚きの実力 -
第157回
AI
AIだけでゲームは作れるのか? Codexに7本作らせて見えた実力と限界 -
第156回
AI
ChatGPTの画像生成AIは本当に最強か Nano Bananaと比べて見えた“弱点” -
第155回
AI
非エンジニアが数百万円級のツールを開発 画像&動画生成AIツールがゼロから作れた話 - この連載の一覧へ














&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")


















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")
