



ロードマップでわかる!当世プロセッサー事情 第569回
性能が70%向上するCooper Lakeと200Topsの性能を持つPonte Vecchio インテル CPUロードマップ
2020年06月29日 12時00分更新

アクセラレーター向けの拡張命令が搭載される
Sapphire Rapids
さて、Cooper Lakeの名前が最初に出てきた2018年では、Cooper LakeはIce Lakeベースと共通のプラットフォームになるはずなのが、実際にはそうならなくなった。
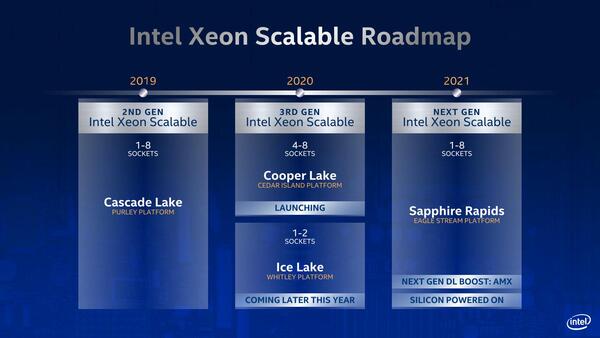
Whitleyの詳細は今のところ公式にはまったく明かされていない。噂では8chのメモリーコントローラーを持つらしいが。なおインテルはIce Lakeの世代からPCIe Gen4に正式対応なので、当然こちらもサポートされるはずだ
Ice Lakeについては今年末に投入されるということで話をおいておくとして(*)、問題は次のSapphire Rapidsだ。これに関して、新しくAMXなる拡張命令が搭載されることが発表された。余談だが、この次のスライドには、明らかにSapphire Rapidsチームではない人間が混じっている。

なぜあなたが混じってる?
このおじさんの話は次でするとして、問題はこのAMX。正式にはAdvanced Matrix eXtensionsという命令セットであるが、6月24日にこれが明らかにされた。
そのAMXであるが、AMXはMMXから始まる一連の拡張命令と異なる、「アクセラレーター向け命令」であることが冒頭で明らかになった。
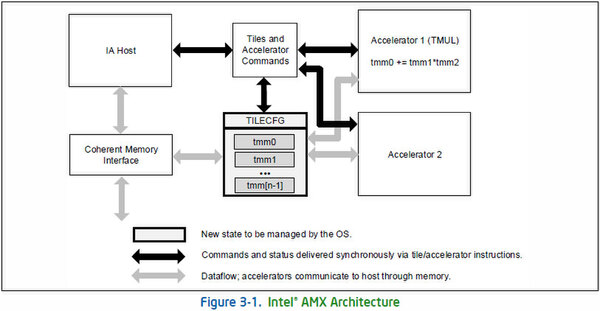
従来のCPUのパイプラインは左上の“IA Host”になる。そしてアクセラレーターは右側。その中間に謎のTILECFGというエリアがあり、この状態をOSが管理すべきものとしていることに注目。要するに拡張レジスターの延長として、TILEを扱わないといけないようだ
つまりCPUコアの外に、TILECFGと呼ばれるメモリー領域(おそらくはSRAMベースだろう)が用意され、ここをCPUとアクセラレーターから自由にアクセスできるようにするという、まったくこれまでと異なるアーキテクチャーである。
一見するとこのTILECFG、AVXレジスターの延長に見えなくもないのだが、上の画像を見ると実は2次元アクセスが可能な領域を構成していることがわかる。ちなみにTILEは複数持てるようで、このTILEの塊をPaletteと呼ぶ。
デフォルトでは16row×64Bytes=1KBのTILEを8つ搭載したTILEが用意されるが、必要ならより大きい、あるいはより多いTILEを利用することも可能になっている。ただこれはハードウェア的に容量が決まる模様だ。
そのTILEをどうアクセスするのか、というのが下の画像だ。
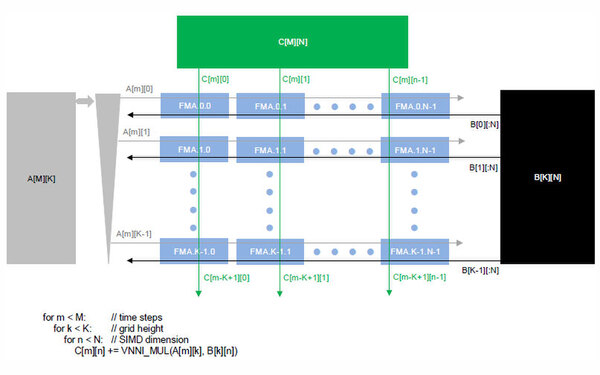
少しわかりにくいが、AとBという2つの配列は、それぞれ灰色と黒色の矢印方向にレジスターを展開する。これを縦方向に串刺しにしてCという出力を得られるのがTILEの特徴だ
以前畳み込み演算を行列演算で行なう仕組みを連載562回で説明したが、ここでA1~A9やB1~B9という値は、まとめてAVXレジスターに格納されている。したがって、単純なケースではA1~A9が格納されたレジスターとB1~B9の格納されたレジスターの掛け算をすればいい。
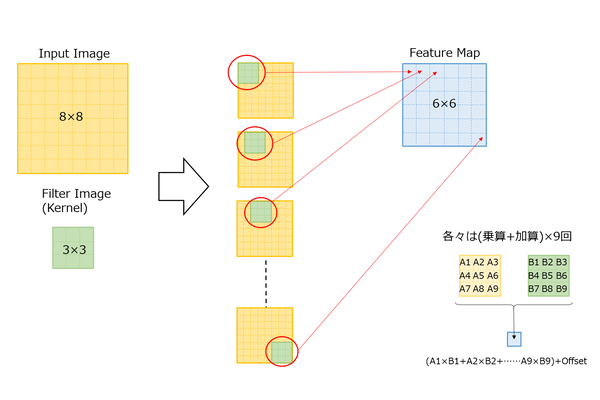
連載562回で説明した畳み込みの仕組み
ところが、時間軸のパラメーターが入ったりすると、計算ごとに対象となるレジスターが変わる。対策としては以下のとおりで、どちらにしてもオーバーヘッドが大きいやり方しかない。
- 計算に使うレジスターは固定し、毎回対象となるレジスターの値を計算に使うレジスターにコピーする
- 対象となるレジスターごとにプログラムを書く
これは従来のアクセスが1次元、2つ前の画像で言えば黒や灰色の横方向の矢印の向きにしかできなかったためだ。ところがAMXでは、複数のレジスターをまとめてアクセスできる。先の画像で言えば緑の矢印だ。
これによって、行列計算が猛烈に簡単になる。下の画像が実際のプログラムの例で、行列の横方向アクセス(A)と縦方向アクセス(B)の演算結果をCに格納するというものだが、おそろしく簡単化されているのがわかる。

TILELOADDはCPU側のレジスターからTILEに値を書き込む。逆にTILESTOREDはTILEからレジスターに値を書き込む命令である
今のところAMXで定義されているのはTILEのConfigurationのLoad/Saveと、TILEの中身のLoad/Save、それとDot Products命令だけで、やや無駄が多い気もしなくはないが、将来的にはもっといろいろ命令が増える可能性がある。
そして肝心なのは、これがAVXと並行して動く、完全にアクセラレーター扱いなことだ。となると実装としては、例えばGPUを使うこともありである。Sapphire Rapidsチームの画像にKoduri氏が顔を出しているというのは、Sapphire RapidsがXeと連携している、ということを意味している可能性もある。
(*) おいといていいのか? という話はあるが、情報がないのでおいておくしかない。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")




































