人工知能の開発に破壊的イノベーションはあるか
国内の”知の最前線”から、変革の先の起こり得る未来を伝えるアスキーエキスパート。KDDI研究所の帆足啓一郎氏による人工知能についての最新動向をお届けします。
昨今の人工知能の発展を支える大きな要素として、「ビッグデータ」が挙げられる。現在でも、ソーシャルメディアに日々アップされる行動データだけでなく、Web検索の履歴、スマートフォンの利用状況など、ユーザーに関する多くの情報が集められており、各社が実現する「人工知能」に入力されている。
このようなビッグデータの集積・解析は、今後も対象を広げながら進んでいくことは間違いないが、その一方、あまりにも多くのデータが特定企業によって集められていることに対する懸念も高まっている。今回は、もはや不可避ともいえるビッグデータの拡大と、それがもたらすユーザーの懸念に対応するための破壊的イノベーションの可能性を示す。
テクノロジーがもたらす「不可避」な未来
筆者が寄稿したアスキーエキスパートの第2回記事にて、Kevin Kelly氏によるSXSW Interactiveでのキーノート講演について触れた。本講演のタイトルは「12 Inevitable Tech Forces That Will Shape Our Future」だったが、講演の中では12個の「Tech Forces」のうち、特に重要な3つのみに言及し、残りについては「近日中(注:講演当時)に発売される著書を買うように」と紹介するにとどめた。講演自体は非常に興味深く、筆者としても残りが気になったので、後日その著書を購入した(Kelly氏の思うツボではあるが…)。
| Image from Amazon.co.jp |
 |
|---|
| The Inevitable: Understanding the 12 Technological Forces That Will Shape Our Future |
なお、本年7月には邦訳版も発売されている。
| Image from Amazon.co.jp |
 |
|---|
| 〈インターネット〉の次に来るもの―未来を決める12の法則 |
(注:以降の説明は、筆者が読んだ原著の内容に基づくものであり、細かい表現は邦訳版と異なっている可能性がある)
本書のタイトルからは、一見、12個の技術的なトレンド(たとえば「人工知能」「バーチャル・リアリティ」など)を紹介する内容を想起するかもしれない。しかし、本書ではこうした個別の技術紹介ではなく、技術によってもたらされる現象が主題であり、それぞれを動詞として表している点が特徴的である。
第1章から順に書くと「Becoming」「Cognifying」「Flowing」……といった具合である。そして、これらの現象はテクノロジーの発展によってもたらされる不可避(Inevitable)かつ現在進行形の変化である……というのが著者の主張である。(筆者は不勉強のためSXSWにて初めて知ったが……)Kevin Kelly氏はさすがにWIREDの創刊編集長だけあり、30年くらい先という想像しにくい世界観が、具体的なイメージとして描写されており、数多ある未来予測の本の中でも読みやすく、かつ大いに考えさせられる内容であった。
「人工知能」の発展がもたらす未来と懸念
当然ながら、本書で紹介されている未来予想に影響を与える技術トレンドとして、人工知能が大きく取り上げられている。特に、人工知能との関連性が強い現象は以下の3つ(本書での掲載順)。
●Cognifying:あらゆるモノが認知・認識能力を持つこと
●Filtering:膨大な情報の中から必要・適切なものが選別されること
●Tracking:あらゆるモノ・ヒト・現象がデータとして記録・解析されること
複数の章にわたって丁寧に書かれた内容を大雑把にまとめてしまうのは乱暴だが……一言でいうと、人工知能があらゆるモノやサービスに浸透し、世の中にばらまかれたあらゆるモノによって記録される超・膨大なデータが解析され、個々のユーザーの嗜好や状況に応じた形で選別・加工されたうえで提供されるというのが、上記の各章で描かれている未来像である。
本書でKelly氏が描いている未来像は、概して楽観的である。しかし、Trackingの章では、あらゆる事象がデータ化される未来の実現のためにクリアしなければならない2つの課題について言及。一つは、日々の行動などがトラッキングされることに対する社会の許容、もう一つは、蓄積された膨大なデータを分析できる技術の出現である。
これらの課題のうち、後者の技術的な課題は遅かれ早かれ解決されると、筆者(私)は考えている。一方、前者については、少なくとも現時点ではまだクリアされているとは言いがたい。今、ソーシャルメディアやスマホアプリを利用している人は多いが、こうしたサービス・アプリを経由して、自分に対するあらゆるデータが集められることについては漠然とした不安を抱いている人が多いだろう。また、こうした複数のサービスの利用履歴が、特定の個人を表すIDによって仮に突き合わせられることが可能になった場合、自分自身に関するあらゆる行動の記録が取られ、想定していない目的で活用されることを懸念する人も少なくない。
この問題を解決するためのポイントとして、Kelly氏はデータ利用の透明性と対称性をあげている。
透明性とは、各個人が提供している自身のデータの内容、および誰がどのような目的でデータを活用しているのかを把握しコントロールできること、対称性とは、個人データを提供している先の組織等がほかにどのようなデータを持っているのかを掌握できることである。つまり、データを取られる個人と、データを集める相手との間で可能な限り公平な条件下での相互監視(本書では”coveillance”という造語で表現)を前提とすれば、いずれは個人データ利用に対する懸念がなくなり、ユーザーが安心してTrackingを受け入れると主張している。
上記のポイントのうち、透明性はすでに数多くのサービスで実現されている。Facebookでは細かいレベルで自身の情報の開示範囲を設定することが可能になっている。また、Android 6.0以降のスマートフォンではアプリごとにアクセスできる情報をユーザが選択できる機能が標準搭載されている(参考:Google Playヘルプ「Android 6.0以降のアプリの権限の管理」)。
一方、対称性については、その実現性に疑問が持たれるところだろう。現実問題として、GoogleやFacebookなどの巨大IT企業は日々膨大な情報を集め続けており、その全貌を1ユーザーとして把握することは不可能である。この点については、さすがのKelly氏も懐疑の念を示しているが、ユーザーが求める情報開示への対応を必須とすることが真の対象性を実現する一歩としている。
そして、これらの分析を根拠に、自身が描く「不可避」な未来が来ることを主張している。
「データ至上主義」の人工知能に対する、一つのアンチテーゼ
筆者はKelly氏ほどの先見性や多岐にわたる知見がないため、上記のような未来の訪れを断言するのは正直難しい。ただ、人工知能に関連する研究者・技術者としては、「透明性と対称性を前提としたTracking」という考え方は大変興味深い。なぜなら、現在の「データ至上主義」の人工知能に対する、一つのアンチテーゼになりえるからである。
現在のWebサービスにおいては、いかにデータを集められるかが争われている。ユーザーの数、およびそれらのユーザーが提供する情報の質と量が、そのサービスの価値および将来性を決めるからである。そして、今は各事業領域における少数の勝者(Google, Facebookなど)が、圧倒的なユーザー数および情報を集めている構図になっている。
技術としての人工知能(機械学習など)の実現に必要な両輪はアルゴリズムとデータだが、より重要度が高いのはデータである。
研究の世界では、公正に性能評価を行うためのベンチマークとしてのデータコレクションが整備されていることが多く、アルゴリズムの優劣を競うことができる。しかし、実世界ではデータをいかに集めるかが勝負である。多少粗いアルゴリズムであっても、入力されるデータの量が多ければ、そのぶん高い性能を持つ人工知能が実現されているのが現実である。そして、今はGoogleやFacebookといった数少ない勝者が圧倒的な量のデータを有しているため、人工知能の世界でも他の追随を許さないポジションを築きつつある。
こうした、少数の勝者が持つ圧倒的なデータ量によって実現される人工知能は、将来的に人類のすべての行動履歴と叡智を元に学習する「全知全能」な存在となる可能性がある。全知全能の人工知能には、ユーザーにとって多くのメリットをもたらす期待がある。ただ、ユーザーとサービス提供者との間で持つ情報量のバランスがあまりにもいびつなため、「人工知能によって支配されるのでは?」といった漠然とした不安も呼び起こしているという側面もある。ユーザーが気持ちよく自身の情報を提供する(Trackingされる)ための重要なポイントである、透明性と対象性が不足しているからである。
スモールデータに基づく人工知能の実現
Kelly 氏の著書を読んだあと、筆者はこの不安を解消するための一つの方法として、完全な透明性と対称性のもとで実現される人工知能があるのではないかと考えた。
学習データとして用意されるデータの量が人工知能の性能に貢献するという一般常識とは相反しているが、一人のユーザーの情報に閉じた形でそのユーザーの行動や嗜好を学習し、その情報のみに基づいたメリットが与えられる人工知能が実現できれば、全知全能の人工知能による支配という懸念を払拭できるのではないか?……という発想である。
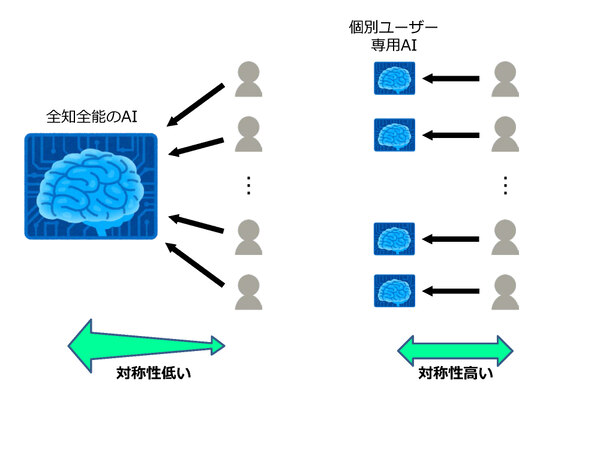
全知全能の人工知能と個別ユーザー専用の人工知能の比較(筆者作成)
ここで大きな課題になるのは、少ないデータから有用な情報を抽出する技術の実現である。これまでの人工知能では、多数のユーザーから集められたデータから得られる知見を元に、個々のユーザーに合わせた情報提供を行っていた。具体的には、全体平均に対する差、類似ユーザーの行動の傾向などから、一人ひとりのユーザーに合った情報を抽出する技術である(要素技術でいえばクラスタリング、協調フィルタリングなど)。しかし、分析の対象が1ユーザーからのデータのみという前提に立った場合、これまで取られていた方式の適用は難しい。ビッグデータがスモールデータになってしまうため、従来のような統計的手法が効果を発揮しないからである。
このアイデアについては、Trackingに対するユーザーの不安解消のみを考慮した、絵に描いた餅のような印象を抱いてしまうかもしれない。しかし、筆者は技術的にも実現の可能性とメリットがある方法と考えている。そのポイントは2つある。
一つ目のポイントは、今や一人のユーザーから取得できる情報が決して「スモール」ではないという事実である。スマートフォンを利用していく中でユーザーが出している情報の量は、実はかなり大きい。もちろん、多数のユーザーからの情報を全部合わせたビッグデータにはかなわないが、ユーザー一人分の情報を丁寧に解析することによっても、有用な情報が得られる可能性は否定できない。
もう一つのポイントは、計算機リソースの効率化である。前回の記事で「深層学習(Deep Learning)」について触れたが、この深層学習を筆頭とした現在の人工知能のアルゴリズムでは、膨大な学習データを処理するための計算機リソースを準備する必要がある。現実的には、多くのデータを集めている少数の勝者のみが、そのデータを処理することができる規模の計算機リソースを確保できており、圧倒的優位なポジションの礎となっている。
しかし、スモールデータを前提とした人工知能の実現には、当然ながら膨大な計算機リソースは必要ない。たとえば、ユーザーのスマートフォンの中のみで人工知能の学習処理を完結させることも十分可能である。そうなると、巨大組織に自身の情報を吸い取られる必要もなくなり、対象性に対する不安が払拭できる。
人工知能における破壊的イノベーション
以上のアイデアは、現時点ではKelly氏の著書に着想を得た筆者の思いつきであり、具体的な実現性に対する検討も正直浅い。ただ、筆者の発想の根本にあるのは「破壊的イノベーション」のモデルである。
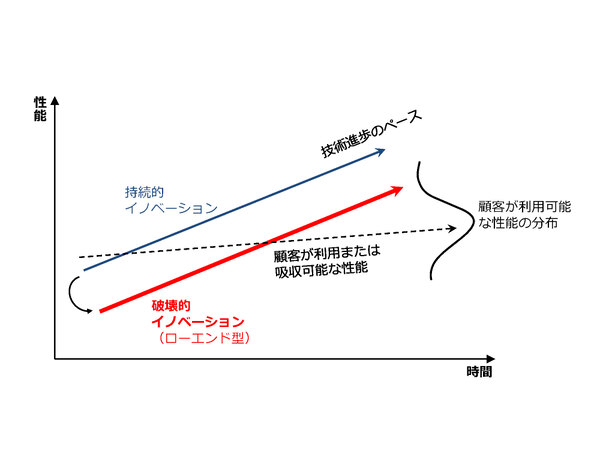
今の人工知能におけるイノベーションは急速なペースで進んでいるが、大規模なデータを集めて解析するというフレームワークは変わっていない。そのため、現在のイノベーションは持続的なものとみなせる(上図の青い線)。持続的イノベーションがこのまま続くと、ユーザーが受け入れられる性能を超える人工知能が実現されるが、その過程のどこかで、スモールデータに基づいて作られた、ユーザー一人ひとりに寄り添う小さなローエンド型の人工知能(上図の赤い線)が出現する可能性はあると考える。
現時点において、個々のユーザーは人工知能に対し金銭的な対価をほとんど支払っていないため、「性能」と価格が連動することを前提としたイノベーションのモデルを直接適用するのは不適切かもしれない。ただ、将来的には、Kelly氏が主張する透明性と対称性をユーザーが今以上に強く求めるようになる可能性はある。こうした展開に備え、今チャレンジャーの立場にいる技術者としては、今の勝者との真っ向勝負以外のアプローチを模索していかなければならないだろう。
アスキーエキスパート筆者紹介─帆足啓一郎(ほあしけいいちろう)

1997年早稲田大学大学院修了。同年国際電信電話株式会社(現KDDI株式会社)入社。以来、音楽・画像・動画などマルチメディアコンテンツ検索の研究に従事。2011年、KDDI研究所のシリコンバレー拠点を立ち上げるため渡米し、現地スタートアップとの協業を推進。現在は株式会社KDDI研究所・知能メディアグループ・グループリーダーとして、自然言語解析技術を中心とした研究開発を進めるとともに、研究シーズを活用した新規事業創出に取り組んでいる。電子情報通信学会、情報処理学会、ACM各会員。経済産業省「始動Next Innovator 2015」選抜メンバー。
本記事はアフィリエイトプログラムによる収益を得ている場合があります