




Delayを解消する特殊なメモリー
「ラッチ」
Delay問題を解決し、正常に処理する一番手っ取り早い方法が「ラッチ」である。ラッチというのは一種のメモリー、正確に言えば1bitのSRAMであって、「あるタイミングで、入力された値をずっと保持して出力し続ける」という機能を持つ。
図10はこのラッチの模式図である。ラッチ入力は0と1の間をふらふら変動するわけだが、これとは別にトリガー入力という信号が用意される。このトリガー入力の立ち上がり(0→1に変化するタイミング)で、ラッチ入力の値を取り込んで出力、以後は次のトリガー入力が来るまで保持し続ける。

図10 ラッチの模式図
ではラッチを使うとどんなくあいに問題が解決するのだろうか。図11は図8の先頭にラッチを追加した構図だ。

図11 図8にラッチを加えた回路
この状態でタイミングがどうなるか、を示したのが図12である。

図12 図11のロジック回路が行なう処理
これまでだと、入力は一定期間だけ保持された後変わってしまうが、ラッチを挟むとその入力値がその後ずっと保持されることになる。したがって、Logic A~Hはそれぞれやや遅れて動き始めても十分間に合うことになる。これにより、複雑な大規模ロジック回路であっても、正しく動作できるようになるというわけだ。
ここまで延々といろいろな解説をしてきたのは、このラッチの必要性を理解してもらうためである。一般にデジタル回路は同期回路と非同期回路という2種類に分類できるが、この違いはラッチを挟むか挟まないかの違いである。
図11の場合では、Logic A~Logic Iの間は非同期回路である。ただし全体としては同期回路として動くことになる。実のところ、最近の大規模LSIのほぼ100%が、この同期回路で設計されている。というのは非同期回路の場合、大規模になればなるほどタイミング調整が難しくなるからだ。
実際、商用の製品で非同期回路を実現できた製品としては、シャープが1998年にリリースした「DDMP」(Data Driven Media Processor)くらいしか思いつかない。あとはARMがマンチェスター大学と共同で「Amulet1/2」と呼ばれる非同期ベースのARMコアを開発したり、Philips(現NXP Semiconductor)の子会社であるHandshake SolutionがARM9ベースの非同期プロセッサーを試作したという程度である。
非同期で設計できた製品数は数えられる程度でしかない、というあたりに非同期だけで設計することの難しさが見て取れる。
さて、この同期回路やラッチがどこにつながっていくかというと、最近のCPUのパイプラインにモロにつながる。そもそもラッチの場合、定期的に新しいデータを取り込ませない限り、電源が切れるまでずっと最初のデータを保持している。
そこで定期的にトリガーを入力する必要があるが、このトリガー信号こそが、いわゆるクロック信号である。つまり動作周波数が1GHzの場合、実際はクロック信号が1GHzであるという意味なのだが、これはつまりラッチに対して、1ns毎にトリガー信号が与えられるという意味である。
逆に言えば、ラッチから始まる一連の回路ブロックは1ns以内にすべての処理を完了しないといけない。これがもし間に合わないと、正常に処理ができず、暴走するわけだ。
さらには、最近のCPUのパイプラインは大体が1ステージあたり1サイクルで処理される。つまりパイプラインステージの先頭にはラッチが入り、この後に非同期回路の形で、デコードやALUなどの実際の処理が搭載される。
当然ながら処理が少ないほど、短い時間で処理が終わる=クロック信号の動作周波数を上げやすいという関係にあり、これが理由でパイプライン処理を分割して処理時間を短縮するスーパーパイプラインなどが登場したわけである。
Delayを示す数値「FO4」で
パイプラインの速度がわかる
最後にFO4という指標について少し説明しておこう。FO4(Fan Out 4)というのは、CMOS回路におけるDelayの度合い、つまりパイプライン構成がどの程度高速向けなのかを示すものになっている。
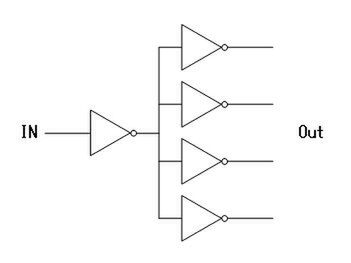
図13 図11のロジック回路が行なう処理
FO4そのものは、図13のように入力を4分割するゲートを考えた場合の、NOT1個分のDelayを示す数値である。図8では出力は1個しか考えてなかったが、実際は図13のように出力を分割する場合が珍しくない。こうした場合、NOT出力の負荷が高まる分、電圧を上げた際の遅れが大きくなることになる。
このFO4は、プロセッサーのパイプラインの各ステージがどの程度のDelayを想定しているかの指標となる。つまりパイプライン1段分の処理は、このNOTが20~25個直列につながったのと同程度のDelayを発生すると想定しているわけだ。例えばQualcommの「Snapdragon」に利用されているKraitというCPUコアは、20~25 FO4程度で設計されている。
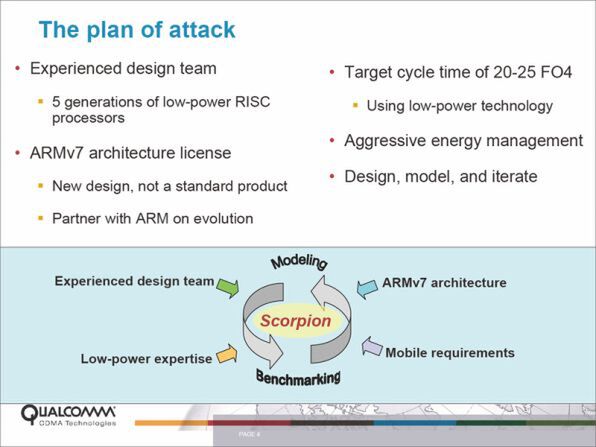
2007年のARM Developer ConferenceにおいてQualcommの発表した資料より。FO4のターゲットが20~25と示されているのがわかる
これが「Pentium 4」では16強、IBMの「Power 6」は13である。数字が小さいほど高速にパイプラインを動かすことを想定しており、これは消費電力が大きくなる。逆にモバイル向けのプロセッサーでは消費電力を下げるために動作周波数の目標を低めに設定しているため、必然的にパイプライン1段分に仕込める処理が増え、結果としてFO4の値が大きくなるわけだ。
この連載の記事
-
第770回
PC
キーボードとマウスをつなぐDINおよびPS/2コネクター 消え去ったI/F史 -
第769回
PC
HDDのコントローラーとI/Fを一体化して爆発的に普及したIDE 消え去ったI/F史 -
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ - この連載の一覧へ












が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")











