



ロードマップでわかる!当世プロセッサー事情 第629回
Intel Architecture Day 2021で発表された11のテーマ インテル CPUロードマップ
2021年08月23日 12時00分更新

Intel Thread Director
Alder LakeはP-CoreとE-CoreのMixになる関係で、big.LITTLE構成になる。したがって適切なスケジューラーを用意しないと、省電力にさせたい場面でP-Coreが動いたり、演算パワーが必要なシーンでE-Coreが動いたりと都合が悪い。このためOSのスケジューラーに手を入れていろいろ工夫を凝らす必要があるのだが、インテルはAlder LakeでこれをサポートするThread Directorを実装した。
Thread DirectorはハードウェアとOSのスケジューラーの中間に位置するが、Thread Directorに対応しないOSの場合、Thread Directorは透過的に機能するためOSはThread Directorがあることそのものを意識しない。

その代わり、Thread Directorの提供する機能そのものは利用できなくなるので、スケジューリングの精度は落ちることになる
特徴的なのは従来のbig.LITTLEのスケジューラーがおおむねそのプロセッサーの負荷を見るのに対し、Thread Directorでは実行される命令なども同時に監視することで、これはソフトウェアベースのOSのスケジューラーでは真似できない。
具体的に言えば、優先的なタスクやAI関連命令はP-Coreに、バックグラウンドのTaskはE-Coreに割り当てるほか、Spin Lock(スレッド間同期を取るために、CPUを空回りさせる命令)があったらE-Coreに割り当てる(単に待っているだけならP-Coreである必要はない)といった工夫がなされている。

Spin Lockはしばしばドライバーで使われることもあるので、これドライバーの動作中に煩雑にP-CoreとE-Coreのスイッチが発生しそうな気もする。もっともSpin Lock命令が発生したら直ちに、というよりはある程度Spin Lock状態が続いたら移行といった実装になっていそうだが
Alder Lake
さて、P-CoreとE-Core、Thread Director、それとXe GPUを組み合わせたのがクライアント向けのAlder Lakeである。このAlder LakeはIPによるビルディングブロック構造になっており、デスクトップ/モバイル/ウルトラモバイル向けの、最低限3種類のSKUが用意されることが明らかにされた。
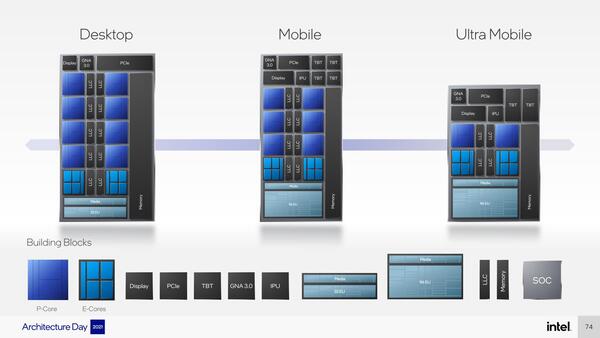
デスクトップはE-Core×8+P-Core×8だが、IPU(Image Processing Unit:カメラ用I/F)やTBT(ThunderBolt Technology)は未搭載で、GPUも32EUのみ。モバイル/ウルトラモバイルはP-Coreの数が減って、その分GPUが強化され、TBTやIPUが搭載される
このうちデスクトップ向けについては従来レポートしてきたがLGA1700パッケージで提供され、最大消費電力は125W。他に、モバイル向けにBGAパッケージ2種類も用意される。またメモリーはDDR4/DDR5の両対応となる。さらにデスクトップ版は、PCIe Gen5 x16レーンとPCIe Gen4 x4レーンの構成になるとする。

Alder LakeでもPCHの統合は先送りの模様
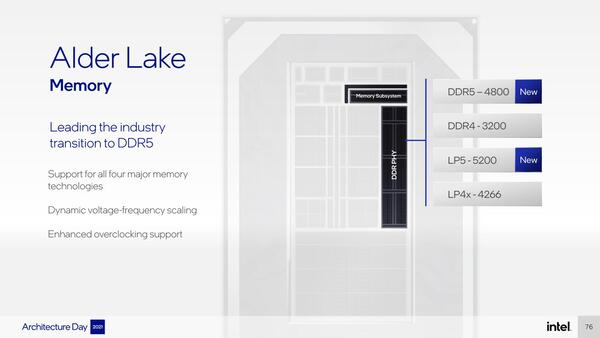
LPDDR4x-4266やLP5-5200はモバイル向けのみと思われる。ちなみに同じLGA1700でDDR4とDDR5の両対応だが、マザーボードの側はDDR4版とDDR5版で異なるものが必要になる形だ(両方のメモリースロットを用意する変態マザーボードもありそうだが)
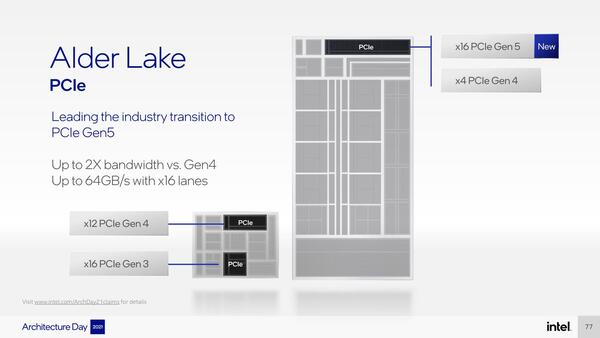
SSD向けのx4レーンがPCIe Gen4据え置きなのは少し残念(すでにMarvellはPCIe Gen5対応コントローラーをリリースしている)。
AMX
次はXeon向けのAMX。AMXそのものは昨年6月に命令セットのリファレンスドキュメントが公開されており、これをベースに昨年連載569回で紹介したわけだが、今回正式に発表になったところでは、例えばVNNIを利用した場合に比べて8倍に高速化される、としている。

ちなみに先の記事では、あるいはXe Coreを利用するのでは? と書いたが、少なくともSapphire Rapidsでは独立したアクセラレーターとしての実装になる
理屈は以前説明した通りで、行列を丸ごと格納できるタイルというレジスターを用意すると、このタイル同士での演算を行ない、結果をまたタイルに突っ込んで返してくれるという仕組みだ。このタイルを利用した別のアクセラレーターを利用することも可能な実装になっているという話であった。

タイル同士で演算を行ない、結果をまたタイルに返してくれる。タイルとの煩雑なデータのやり取りが発生するが、これを高速に処理するための命令も実装される
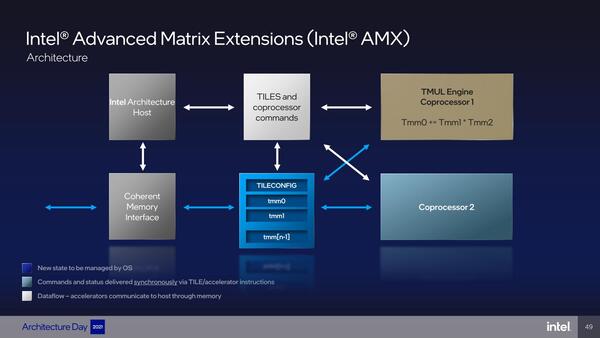
これは今すぐなにか計画があるというわけではなく、タイルとコプロセッサーの間が論理的には分割されており、別種のアクセラレーターを組み込むことも可能という話。将来的にはGNAがこれに統合されそうな気もする
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























