




Dataflowにすることで
生産性が大幅に改善
もう1つ厄介なのは、MLではしばしば疎行列(要素の値が0の項目)が非常に多いことで、これをうまく計算から省ければ、実効パラメーターの数を減らして性能を高められるという話である。
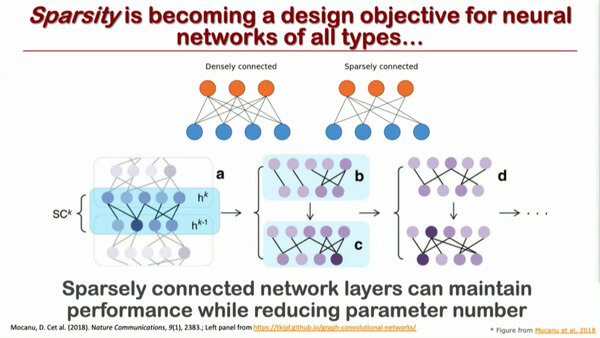
この話はこれまでも何度か触れたことがある。DataFlowを利用する動機の1つが、この疎行列(というかパラメータの値が0の場合)の扱いである。もっともDataFlow「だけ」ではうまく扱えないのだが
一般的な解決策はグラフをきちんと認識して処理することという話であって、前回紹介したGSPもこうしたことに着目したプロセッサーである。
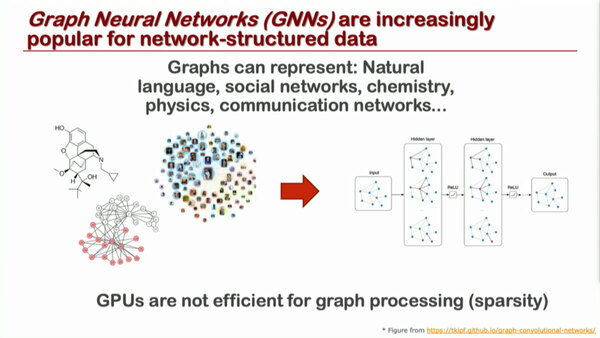
さりげなくGPUを侮辱しているが、そもそもGPUはグラフ処理をするような構造になっていないから仕方ないといえば仕方ない
ではRDUはこれをどうやって解決するか。まず先ほども出てきたSoftware 2.0なる話。Olukotun博士によれば、Dataflowにすることで、生産性が大幅に改善するとする。
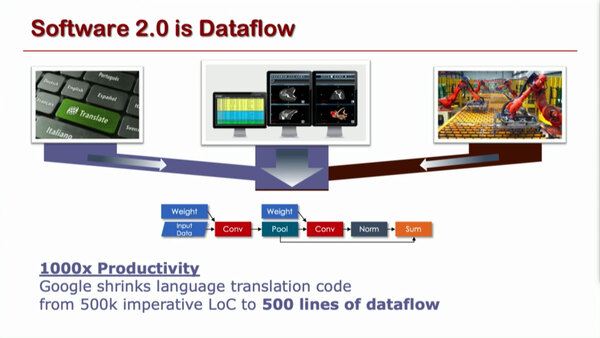
Googleの50万行のコードがDataflowだと500行になった、というのはTensorFlowをDataflowで書き換えたら500行で収まったという話だそうだ。もっともこれ、Googleの元文献が見つけられなかったので、これだけではなんとも言えない
これは前提として、さらに内部構造をDomain Specific Languageで記述できるようにすることで効率をさらに上げよう、というのが基本的な発想である。
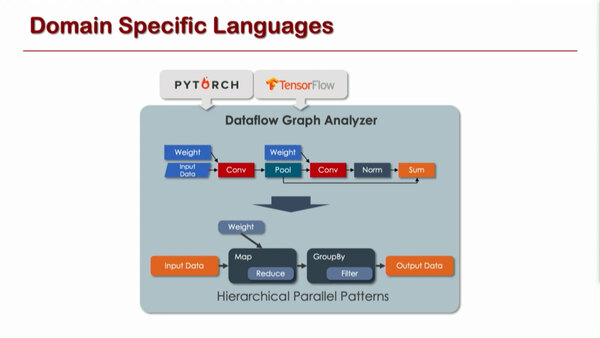
ここで言えば汎用のロジックを組み合わせて畳み込みを実行するのではなく、それぞれの用途に適した処理ロジックを使うことで効率を上げるわけだが、専用ユニットを実装するのは実装効率に劣る。だったらReconfigure Processorを入れてしまえ、というのはあまりにも無茶な気がする
このDomain Specific Languageの実装がRDAにつながるというところが、RDUのブッ飛んだところである。
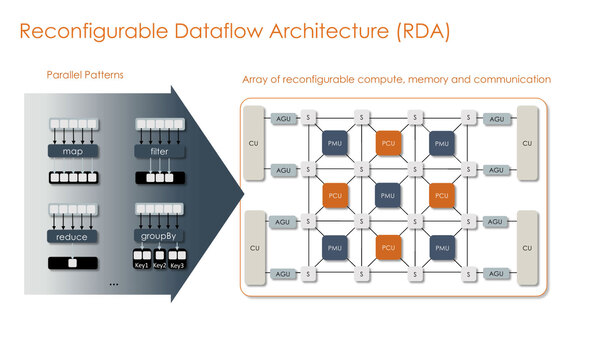
演算ユニット(PCU)とメモリーユニット(PMU)が格子状に配され、間にスイッチが入るというすさまじい構造。別にこの3×3で終わりではない模様
PCUの内部はSIMDのフローティングユニットと中間レジスター(PR)を挟む多重構造になっており、このPRで処理内容を柔軟に変更できる。
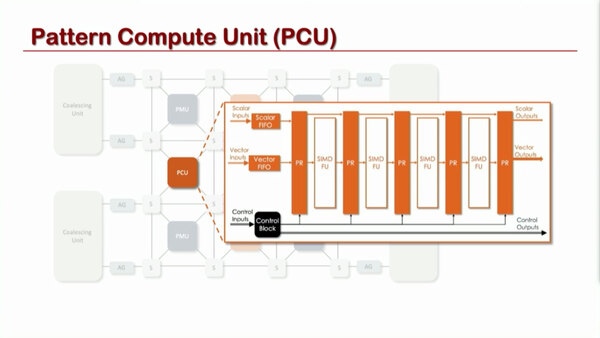
ここで言うパターンとは、上の画像の左側に出てくるさまざまな処理のパターンを意味する。要するにPRの内容を細かく変化させることで処理の内容を変更できるというもので、構造は違うが基本的な発想はGF11のMemphis Switchを思い出すものがある
一方のPMUの方だが、こちらはPRUに似ているものの、最終出力をScratchpadに書き込める点が異なる。
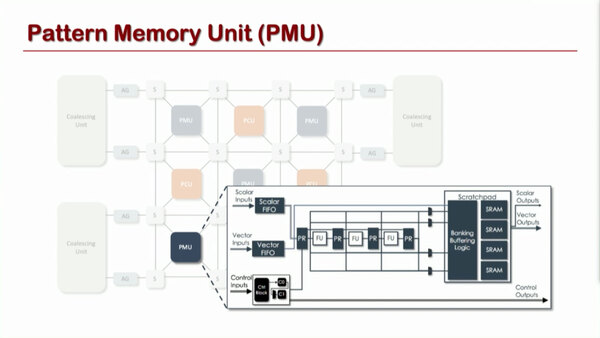
PCUは処理結果をそのままスイッチ経由で(バッファリングせずに)次のユニットに流し込むだけ。一方PMUは処理結果を保持できる点が異なる
ただ純粋にメモリーユニットではなくフローティングユニットも内蔵しているあたりがやや毛色の変わったところだ。
例えば畳み込みで言えば、最後に総和を求めるところでは一時的にバッファがどうしても欲しいところで、そうしたケースはPMUを、その前段階の掛け算はPCUを使うといった使い分けを想定していると思われる。これらを利用して、例えば単純な畳み込み2層の処理なら下の画像のように実行できるわけだ。

畳み込み2層の処理。Weightデータをどこで保持するのか? という疑問はあるが、例えばもう1つPMUを使って、そこにWeightを保持することもできるだろう
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























