




商用向けは成功例がほとんどない
ということで理屈では優れているはずのReconfigurable Processorであるが、商用向けはいばらの道が延々と続いた。筆者が知る範囲で言えば、米Stretchは2004年頃からReconfigurable ProcessorとしてS5000シリーズを提供開始、2006年には第2世代のS6000シリーズを発表したものの、その後業績不振もあって経営陣が交代した。
DVR(Digital Video Recoder)向けに活路を見出し、2010年にはS7000シリーズをリリースするものの、2014年にExarに買収されて消えている。
同じ時期に日本でReconfiguration ProcessorをリリースしたのがIPFlexで、DAPDNAと呼ばれるReconfiguration Processorを発表。複写機向けなどに採用されたものの同社は2009年7月に破産。
同社が保有していた関連特許を始めとする知的財産は丸ごと、富士ゼロックスが買収した。これはDAPDNAをベースに製品を開発しており、そうした開発に支障がないように、ということであった。
もう少し後には、2010年にTabluraという企業がReconfigurable FPGAをリリースしている。これはどういう話かというと、通常FPGAは数百MHzで動作するが、Tabulaの製品は1.6GHzで動作し、ただしユーザーから見ると1つのFPGAのセルが200MHzで動作する8つのセルに見える、という仕組みである。
これにより、実際のFPGAセル数の8倍(このあたりはもっと速度を上げればもっと増える)の容量のFPGAを安価に提供できるというものだった。こちらは2014年に最新製品を発表するものの、2015年に会社が破綻している。
もちろん成功した例がないわけではない。例えば英XMOSはxCOREと呼ばれる独特なMCUを提供している。これは高速動作するMCUを時分割で利用することで、見かけ上マルチコアMCUとして動作するというもので、広義にはReconfigura Processorに含まれる。
狭義で言えば、ユーザーが自分で好きなようにカスタマイズできるわけではないので、その意味では単なる時分割プロセッサーと言えなくもないが、利用されている技術要素はReconfigurable Processorと共通である。
あるいはルネサスエレクトロニクスは長らくDRP(Dynamically Reconfigurable Processor)を開発してきており、これを搭載したRZ/A2MというCortex-A9ベースのアプリケーションプロセッサー(DRPはアクセラレーターとして搭載)を出荷している。したがって、全滅したわけではないが、広範に使われているとはさすがに言いにくい。
すさまじい数字を叩きだして有名になった
SambaNovahaのCardinal SN10
前置きだけでだいぶ長くなってしまったが、いよいよ本題に入る。SambaNovahaは2017年、パロアルトで創業された比較的若い会社である。創業後3年ほどはステルスモードで推移したが、すでにベンチャーキャピタルから合計で4億5600万ドルを集めており、企業評価価値は25億ドルに達するとされている、典型的なユニコーン企業(*1)である。
(*1) ユニコーン企業の大まかな定義は 1:創業後それほど時間が経っていない(おおむね10年未満) 2:企業価値評価価値が10億ドル以上 3:未上場企業 の3つを満たす企業のこと。
そのSambaNova、12月9日にプレスリリースを発表し、同社のCardinal SN10を利用したシステムですさまじい数字を叩きだしたことで一躍有名になった。
この数字の話はあとで紹介するとして、まずはRDUの話をしよう。今年2月に開催されたScaled ML 2020において同社はRDU内部の説明をしたので、まずはこの資料をベースに紹介したい。
説明したのは、同社の創業者の一人で、Chief Techologistのポジションであり、かつスタンフォード大教授(Electrical Engineering and Computer Science)のKunle Olukotun博士である。
Olukotun博士の講演は、まず現状NL(Non-local neural networks)やNN(neural networks)の計算量が急激に増大しており、特に最近の自然言語処理においては、ネットワークのサイズが3ヵ月ごとに倍増するという恐ろしい伸びを示していることを問題として取り上げている。
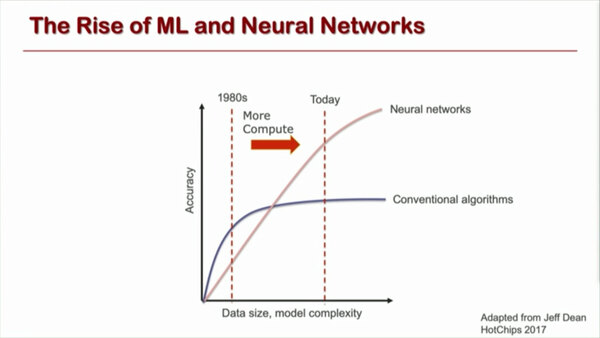
ニューラルネットワークの計算量が急激に増大しているというのは、良く言われる話でいまさらという感はある
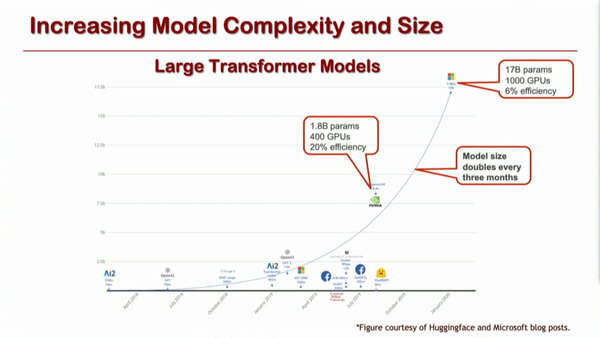
自然言語処理においては、ネットワークのサイズが3ヵ月ごとに倍増する。マイクロソフトが2020年10月に自然言語生成モデルであるGPT-3の独占ライセンスを取得したが、このGPT-3は170億個のパラメーターを持つというお化けで、Azure上で動作している(クラウドでないと動かしきれない)
こうした巨大モデルの場合、今はGPUを使って動作させていることが多いが、その効率が非常に悪いのも問題となっている。こうした問題の解決案としてSoftware 2.0をもっと推進していこう、というのが基本的なコンセプトである。

「ASIC並みの効率とプロセッサー的な柔軟性が必要」というか、いやみんなそれを目指してるんですが……ちなみにFPGAはASICより一桁落ちる効率と、高い柔軟性はあるもののプログラミングの難しさが課題となっている
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ











&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")




















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












