




学習分野における精度改善を狙う
はたしてGPUを駆逐できるか?
さてここまでの話であれば「実現したらすごいね」で終わるわけだが、同社はすでにTSMCの7nmを利用してCrddinal SN10というチップを製造している。

内部の配線の総延長が50kmというのもあれだが、7nmで400億トランジスタというのは、NVIDIAのA100(520億トランジスタ)よりはやや少ないあたり、ダイサイズはおおむね600平方mm台と想像する
現時点でもまだ正確なスペックは未公開(演算性能数百TFLOPSや内蔵SRAM数百MB、外部に1TBクラスのメモリーを接続可能など)であるが、その性能はなかなか目覚ましい。12月9日に出したリリースによれば以下とされている。
- NVIDIAのDGX A100と比較してDLRM(Deep-Learning Recommendation Model)の推論は7倍のスループットとレイテンシー改善を実現しており、これは世界最高記録。またBERT-Large(Googleが2018年に発表した自然言語処理モデル。BASEとLARGEの2種類のモデルがあり、LARGEは24層+隠れ層1024、総パラメータ3億4000万個)の学習ではDGX A100と比較して1.4倍高速だった。
- NVIDIAのA100 GPUベースでのDLRMの精度は80.46%だったが、SN10ベースは90.23%となった。
もう少し細かい数字が12月14日のEETimesに掲載されているが、こちらによれば以下のような数字が並んでいる。
- SN10を64個搭載したシステムは、BERT-Largeの28800 Samples/secの学習速度を記録して、これは世界記録
- またSN10を8個搭載したシステムでは、DLRMで8632 Samples/secの推論速度を達成し、こちらも世界記録
- 1000億個のパラメーターを持つ自然言語処理モデルのネットワークの学習を、SN10が8個のノード(合計メモリー12TB)で実現できる。同じことをGPUで処理するためには412個の最新GPUが必要で、こちらの合計メモリーは32TBに達する。
実はもう1つ数字がある。ここまでの話はML処理に使った場合の話であるが、データ分析のアクセラレーターとしても利用できるという話である。

サンプルコード。tBというテーブルから条件付きでデータを引っ張ってくる、ほぼSQL的な処理である。ただ物理的にはオンメモリーデータベースであろう
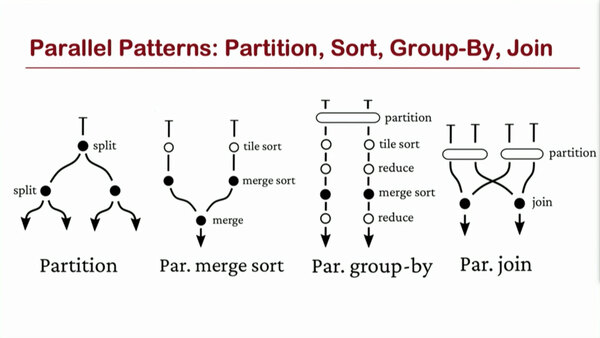
上の画像の処理を行なうにあたっての「パターン」4種類
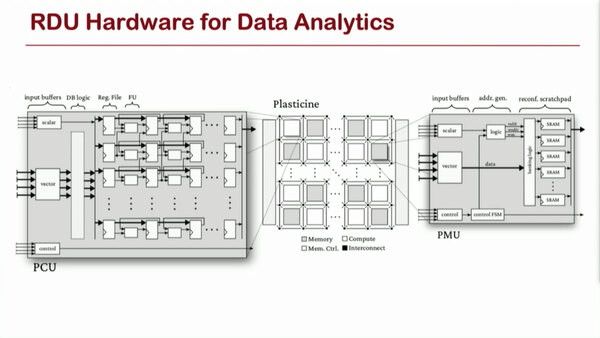
RDUにおける実装例。PCUとCMUで処理を分割して実施する
これを実装したGorgonというソフトウェアフレームワークを、Xeon E7-8890上で同様の処理ができるApache MADlibを走らせた場合と比較すると、絶対性能および性能/消費電力比が200~2000倍向上するとしてる。
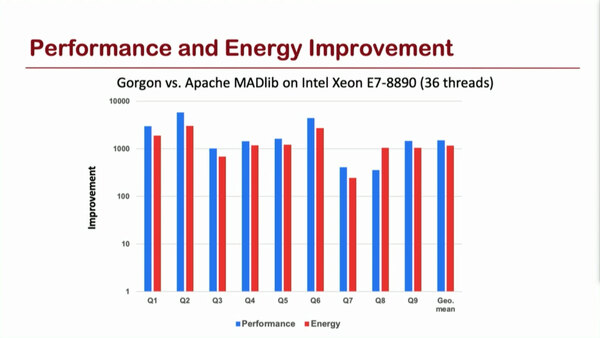
Apache MADlibとの絶対性能および性能/消費電力比。縦軸は改善率であるが、対数軸になっていることに注意
SambaNovaはすでにシステムの提供も開始している。先にSN10が8個、という数字を示したが、下の画像の左側、2Uラック×5段積みのものが8ソケットの構成、1ラック(42U)にはこれが4つ、つまりラック当たりSN10が32個収まる格好だ。

10Uのユニットというよりは、2Uのユニットを5つ重ねているように見える。上下に2つづつSN10を搭載したユニットを重ね、中央に他のノードとつなぐためのスイッチなどを収めたサービスユニットが挟まるものと思われる
システム的にはこれを4つ並べたSN10が128個という構成が最大になる模様だ。

複数のSN10がどういう風に動くのかに関する説明は今のところない。単に別ノードとして動作するのか、それとも連携して動くのか、そのあたりも興味あるところだ。BERT-Largeのベンチマークではラック2本分のSN10が連携して動いているような記述があるあたり、おそらく連携できるのだと思うが、だとするとSN10間のインターコネクトをどうするのかも興味あるところである
実はこのシステム、すでにアルゴンヌ/ローレンス・リバモア/ロスアラモスの3つの国立研究所に納入されて初期の運用が始まっているようだ。また同社はシステム売り以外に、DaaS(Dataflow as a Service)という月単位で計算能力を貸し出すサービスなどもラインナップしているのが特徴的である。
創業からわずか3年でシステム納入まで漕ぎつけた同社のSN10が今後広く採用されるかどうかはまだ見えない部分が多い。
ただGPUがしばしば演算性能を上げるために精度の切り捨て(FP32→FP16あるいはBFloat16)をしているなか、SN10はFP32を保つことで、特に学習分野における精度改善を狙っているのが大きな差別化要因である。はたしてこれでGPUを駆逐できるのか、今後の展開が楽しみではある。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ











&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")




















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












