




1990年台後半~2000年台前半というのは、新しいアーキテクチャーのプロセッサーが雨後の竹の子のように現れ、消えていった時代である。そうした時代に出現したものの中には、超マルチコアやDataflow、Processor In Memoryなど、これまでAI向けプロセッサーとして紹介してきた諸々のアーキテクチャーを採用したものが少なくなかった。
今回ご紹介するSambaNovaのCardinal SN10も、そんな特異なアーキテクチャーを継承している。Cardinal SN10は、Reconfigurable Dataflow Unit(RDU)を搭載したプロセッサーである。
ほぼ1サイクルで回路構成を変更できる
Reconfigurable Processor
まず最初にReconfigurableの定義を説明しておく。Reconfigurable Processorはおおむね「ほぼ1サイクル(場合によっては数サイクル掛かる場合もある)で回路構成を変更できるプロセッサー」だ。と言ってもイメージできない方も多いだろう。
例えば処理A~Dの4つの処理を行なうことを考える。すると従来のプロセッサーの場合、「Aを処理するユニット」~「Dを処理するユニット」まで専用のユニットを用意し、間を受け渡し用バッファでつなぐ格好(下図上側)になる。
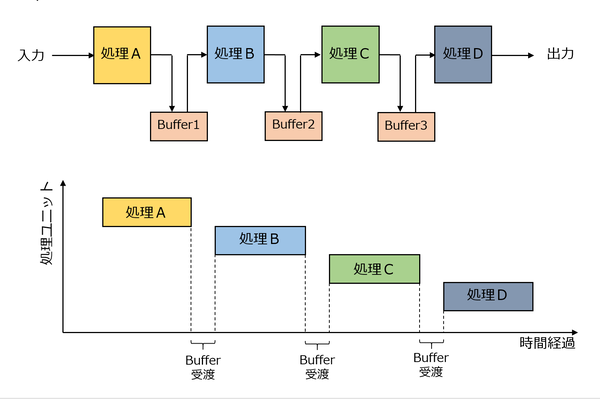
従来のプロセッサーでの処理
この場合、それぞれのユニットが時間軸方向でどう動くのか、というのが上図下側である。まずAが動き、終わると(バッファ経由でのデータ受け渡し時間を挟んで)Bが動き、……といってDまで動き終わると完了となる。
マルチコアプロセッサであればA~Dにそれぞれのコアを割り当てるとか、アクセラレーターならそれぞれの専用回路を搭載するといった格好だ。
これがReconfigure Processorだとどうなるか?というのが下図である。処理A~Dまでが、同一のユニットで処理可能になる。
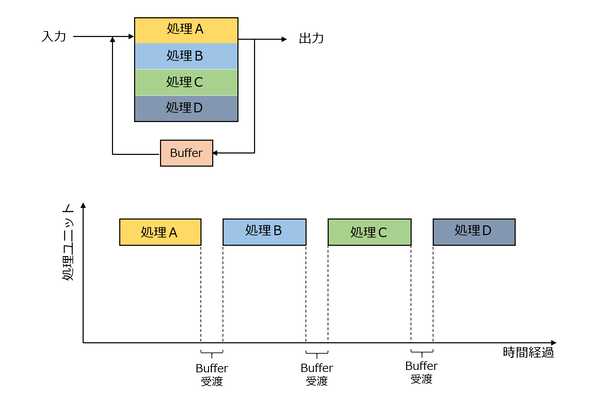
Reconfigure Processorでの処理
この場合、まず処理Aに併せて処理ユニットを構成。ここで処理が終わったら数サイクルで処理B用の構造に作り替え、バッファからデータを読み込んで処理Bを行ない、終わったら処理C用に……とすることで、回路規模を大幅に小さくできることだ。
もっとも「パイプライン動作ができないじゃないか」という突っ込みは当然入るかと思う。実際上図の構造では、実態としての処理ユニットは1つなので、パイプライン動作はできないことになる。ただ逆に言えば従来のプロセッサー処理の図と同じように4つのユニットを使ってよければ、動作を4並列で実行できるので、実効スループットそのものは変わらないことになる。
こんな面倒な構成のなにがうれしいのか? というと、実はそのパイプライン動作にある。パイプライン動作をスムーズに行なうためには、パイプラインを構成する各ステージの処理時間をなるべく一緒にしないといけない。
各ステージが均一の処理時間だと、下図の上側のように綺麗にパイプラインが構成されることになる。

各ステージの処理時間の違いによるパイプライン速度
もし仮に処理Bの処理時間が短く、処理Cが長いとどうなるかというと、上図下側のようにパイプライン全体の速度は一番長い処理Cに併せることになり、かつ処理Bのユニットは遊びまくることになり、効率が悪い。
ところがReconfigurable Processorでは個々の処理時間が変化してもある意味シーケンシャルに実施できるため、効率は変わらないことになる。
もっと大きなメリットは、複雑な回路であっても小さく収められることだ。ASICにしろFPGAにしろ、構成できる回路には物理的な上限というものがあるから、例えばA~Dまで全部の処理を入れたら入らなくなった、なんてことが現実には起き得る(そういう場合、チップを分割してA・Bを処理するチップとC・Dを処理するチップに分けるなどになる)。
ところがReconfigurable Processorなら処理A~Dを一度に動かす必要がなく、チップ上にはある瞬間には処理A、次の瞬間には処理B、という具合に切り替えられるので、処理A~Dの中で一番大きな処理が収まればいいことになる(それでも入らなければ、さらにその処理を分割すればいい)。
また副次的なメリットとして、従来のプロセッサーでの処理の図では中間バッファが複数必要になるが、Reconfigure Processorでの処理の図なら1個の中間バッファで済むので、メモリーの利用効率がいいことも挙げられる。うまくいけば非常に優れた専用プロセッサーが構築できるわけだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ












とBTO PCならではの特注PCパーツに大興奮")




















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












