




DNAにある2つの演算ユニット
Convolution EngineとVector Engine
では、もう少し細かい話をしていこう。下の画像がConvolution Engineの内部である。要するに畳み込み演算のみに特化した演算ユニットであり、中は複数のノードから構成される。

DataFlowとあるが、単に入力データが来なければ動かないという以上のものではないようにも思える。で、そこに入力データを入れる/入れないはソフトウェア側での作業となる模様だ
このノードは要するに乗加算を行なう形になっており、Configuration(つまりいくつのノードを物理的に実装するか)は変更可能であるが、例えば32×32なら800MHz駆動で1.6TOPSだし、これを64×64にすれば6.4TOPS。そのエンジンを8つ並べれば52.4TOPS相当になるわけだ。
その個々のConvolution Engineの中身が下の画像だ。こちらの構成も、実はいろいろ構成可能であって、この図では6ライン分の3-wide Pipelineが2つある格好だが、このライン数やエンジンの数なども細かく変更できるのはIPベースだからで、このあたりはアプリケーション要件に応じて変更できる。
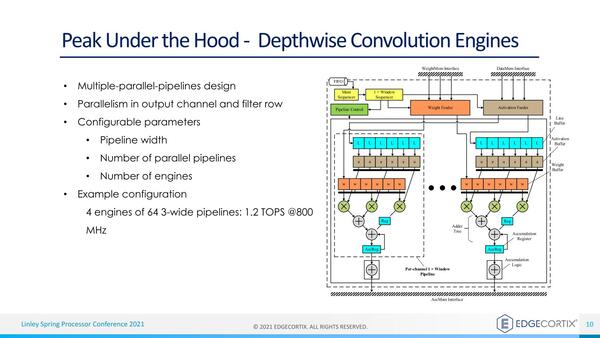
ただこれもよく見るとそんなに特異な構造ではない
もちろん「では一番汎用的に使えるのはどんな構成?」という疑問はあるわけだが、それはEdgeCortixとご相談という話になるのだろう。
これともう1つあるのがVector Engineである。これはプーリングとアクティベーション、スケーリング(クォンタイゼーション)の機能を搭載したもので、いわゆるベクトル演算的なSIMDエンジンを想像するとやや外れることになる。

ネットワークは段々収束していくわけで、最初の層にあわせてインターコネクトを設計すると、後の層ではインターコネクトが余るし、逆に後ろの層にあわせて設計すると前の層ではインターコネクトがボトルネックになる。なのでここをReconfigurableにするのは合理的ではある
それよりおもしろいのは、ここにシーケンサーが搭載されることだ。通常こうしたアクセラレーターの場合、それほど高速でない汎用CPUを搭載することが多い。Armで言えばCortex-A55クラスの「性能は高くないが省電力のインオーダー」プロセッサーである。
前回のEspelantoのET-SoC-1ならET-Minionベースと思われるRISC-V CPUが搭載されていた。要するに、処理に応じて処理データなりWeightデータなりをそれぞれロードしたり、あるいは演算結果をホストに返すといった処理がメインであり、こうした処理のために汎用プロセッサーが利用されるというわけだ。
これに対してシーケンサーは、処理だけ見ているとCPUに近いものではあるが「あらかじめ決められたことを、決められた順番で実施する」だけの機能しかないあたりがCPUとは異なる。
要するに、パラメーターに応じて内部で条件分岐をしながら処理する、というようなことはシーケンサーには不可能である。その代わり、CPUよりも小さな規模で実装が可能であり、また処理性能そのものはCPUよりもずっと高速に行なえる。
したがって、それこそConvolution Engineから渡されたデータをPooling Engineに渡して実行を待ち、その結果をホストに送り出すという処理はCPUよりも効率的にできる。ただ逆に言えば柔軟性はまったくないので、もう少し凝ったことをしたければ別にCPUが必要になるのだが、どうもDNAコアではそうした作業は全部ホスト側に渡すつもりらしい。
DNA IPの概要を示す記事冒頭の画像を見たときに“Instruction-DMA Engine”という表記を見て、キャッシュも持たずにDMA Engineだけが配されていることに違和感を感じたのだが、これはホスト側からAXI経由でシーケンサー用の処理コードをDMAで流し込むという動作を想定していたようだ。なかなか激しい割り切り方である。
チップの消費電力やコストの削減に効果的な
Reconfigurabilityという手法
演算ユニットはConvlution EngineなりVector Engineなりを大量に搭載すればとりあえずピーク性能は上がるわけだが、実効性能をどうやって引き上げるか? というのが次の話だ。
ここで登場するのがReconfigurabilityである。プロセッサーの演算ユニットそのものをダイナミックかつ短時間(1~数サイクル)で切り替えることで実効性能を引き上げよう、という試みはいわゆるReconfigure Processorとして知られており、連載595回でも少し触れたが、この方向性は茨の道というのも事実であり、過去多くのベンチャー企業がこれに挑戦して消えていったという話も595回で触れたとおり。
SambaNovaはまだ頑張っているので、ここがうまくいけば初めて商用的に成功したReconfigure Processorになる(ルネサスのDRPはまだ単独で成功したとは言い難いように思える)わけだが、EdgeCortixはここまでチャレンジはしなかった。
EdgeCortixがチャレンジしたのは、「配線へのReconfigure技術の適用」である。

何と何をどうつなぐかはプログラミングの際に静的に決定し、実際にどのタイミングでどの接続を有効にするかはダイナミックに切り替えるという仕組み。これを同社はReconfigurabilityと称している
例えばネットワークの最初の方の層を処理しているときは、すべてのエンジンを並列動作させることで処理を高速化させたいが、後ろの層になるほどデータ量が減っていくから、すべてのエンジンを同時に動かしても無駄が多い。
であれば、例えば半分あるいは4分の1のエンジンだけを後ろの層の処理に充て、残ったエンジンは次のデータの最初の層の処理に充てる、ということにすれば効率が上がり、性能向上につながる。
ただしこの場合、エンジンごと/処理ごとに「どこからデータを入力し、どこに出力するか」が変わることになる。1つのアイディアは、大容量のメモリーをどこかに置き、すべてのエンジンはそのSRAMからデータやWeightなどを取り込み、結果をまたSRAMに返すというやり方だが、これだととにかく大量のメモリーが必要になる。
SRAMだとそのエリアサイズが莫大になるからチップコストが大幅に上がるし、外部のDRAMにすると今度はそのDRAMの帯域が問題になる。
もちろんDNAコアにもある程度のSRAMが搭載されるし、外部にはLPDDR4などのメモリーをつなぐこともできるが、基本的にはすべてのエンジンとデータメモリー、ラインバッファ、出力バッファなどを相互につなぎ、あとは処理の進行に応じてどの接続をそのタイミングで有効にするか、をダイナミックに切り替えるという形でこれに対応することにしたという。

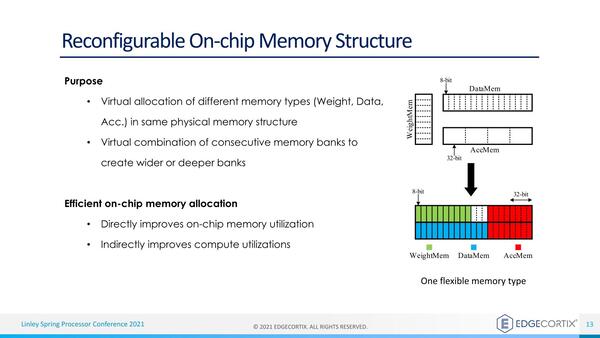
DNAコアの内部メモリは8bitパーティションで自由に再配分可能としている
ちなみにこの再構成というか動的な変更が可能なのはインターコネクトだけでなく、メモリー自体もそうなるそうだ。
当然ながらTensorFlowLiteやPyTourch、ONNXなどに対応している。TensorFlowではなくTensorFlow Liteというあたりがエッジ向けではある
一般論としてこうした仕組みはプログラミングの難易度は上がるが、メモリー利用効率の向上は無駄に大容量メモリーを搭載することを避ける意味で効果的であり、チップの消費電力やコストの削減に効果的なだけに、このあたりは消費電力やコストの削減に舵を切ったというべきか。プログラミングに関しては、後述のMERAでカバーできる、と踏んだのだろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































