
Instinct MI300Aは
Genoaと同じZen 4ダイを3つ搭載
次にInstinct MI300Aであるが、こちらはGPUのダイが3つになり、その代わりにZen 4のダイが3つ搭載される。このZen 4のダイは「Genoaのものとまったく一緒(Exact same)」だそうで、見事なまでの再利用ぶりである。

Instinct MI300Aのものだ、とAMDが主張するCGであるが、肝心のダイのところが見えない

会場で展示されたInstinct MI300Aはこの通りヒートスプレッダーが被さった状態のもののみ(しかもボケている)
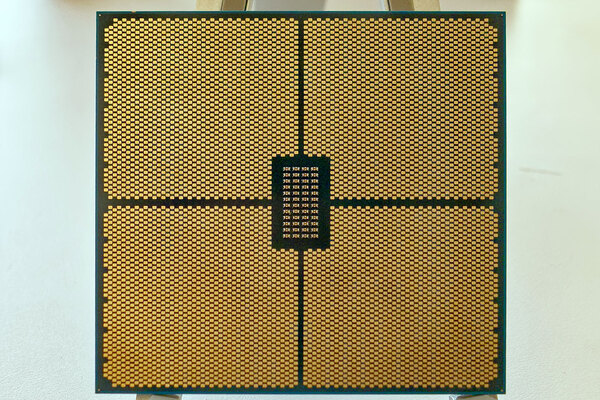
裏面。ごらんのLand数である
さすがにI/Oダイに関しては別ということになるが、その構造の推定図が下図である。GPU用との最大の違いは、キャッシュを持たないことだ。もともとGenoaの場合、追加のキャッシュ(3D V-Cache)はCPUのダイの上に積層される。一方で今回のI/OダイはCPUの下に位置するわけで、キャッシュ拡張用の信号がそもそも出ていないことになる。
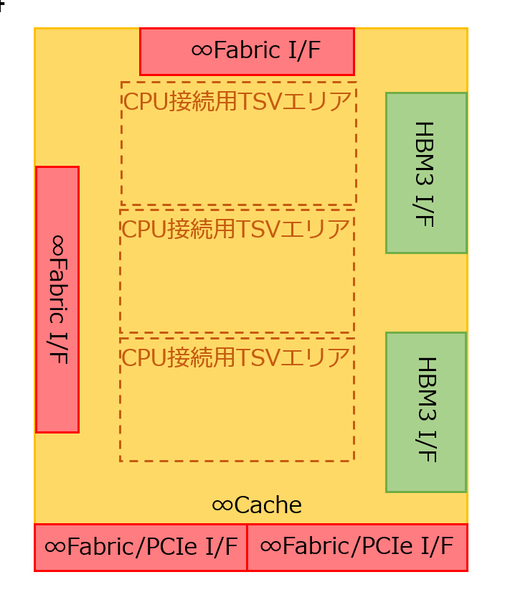
Instinct MI300Aの構造推定図
もしキャッシュの増量が必要なら、3D V-Cache付きのZen 4のダイを搭載すれば済むわけだし、そもそも用途が計算用というよりはGPUの制御とか通信向けということを考えると、3次キャッシュを増量する必要は薄いだろう。
さて問題はこのInstinct MI300Aの性能だ。先ほどのInstinct MI300Xの試算がそのまま通用するとすると、Instinct MI300AのGPU部分の性能は下表となる。
| MI300XのGPU性能 | ||||||
|---|---|---|---|---|---|---|
| 演算 | 性能 | |||||
| PF64 Vector | 144TFlops | |||||
| FP64 Matrix | 288TFlops | |||||
| BF16 Matrix | 1152TFlops | |||||
| FP8 Matrix | 2304TFlops | |||||
| 消費電力 | 672W | |||||
CPUの方は、EPYC 9654の数値(Base 2.4GHz/Max Boost 3.7GHz、TDP 360W)をそのまま3分の1にするとして、FP64 Vectorの演算性能は最大710.4GFlops。TDP 120Wといったところ。これをそのまま合算すると、FP64の演算性能は145TFlops、消費電力792Wあたりになる。おおむね800Wというあたりか。Grace Hopper GH100の4PFlops/1000Wとどちらが性能が上か? というのは微妙なところで、カタログ数値だけで言えばGH100に軍配が上がるものの、以下のような結果になるはずだ。
- 72コアNeoverse N1 vs 24コアZen 4のどちらが早いかは微妙。ひょっとするとZen 4の方が高速かもしれない
- GH100はGPU用とCPU用が別のメモリーになっており、結局CPUとGPUの間でのデータ転送が発生する。Instinct MI300Aは完全にメモリーが共用になっており、データ移動が原理的に不要
- メモリー帯域そのものもGH100よりもInstinct MI300Aの方が上。おそらくキャッシュ容量もインフィニティ・キャッシュが実装されるInstinct MI300Aの方が上
- GH100はCPU同士の通信とGPU同士の通信が完全に別リンクになっている。このあたりもシームレスに利用できるInstinct MI300Aの方が効果的
構造に起因する弱点がGH100には多く、実際のところどちらが高速か? はベンチマークをやってみないとわからないという感じではある。
それはともかくとして、このMI300Aはローレンス・リバモア国立研究所のEl Capitanに利用される。このEl Capitanの構成だが、ぼちぼち資料が出てくるようになった。下の画像は今年5月の“Rabbit Storage for El Capitan”というプレゼンテーションのものだ。
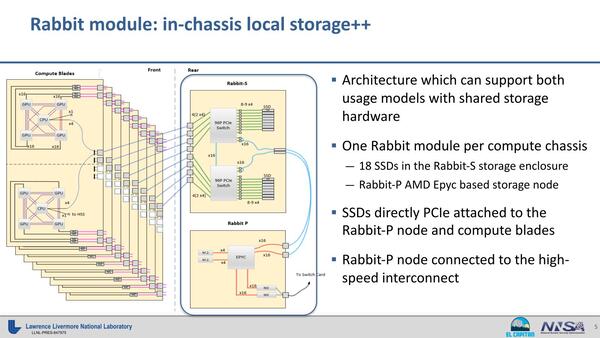
RabbitではCompute Nodeから直接使えるような形でNVMeストレージが用意されるらしい
これによれば以下のことが読み取れる。
- 1つのノードには4つのInstinct MI300Aと、1つのEPYCが搭載される
- 2つのノードで1枚のCompute Bladeを構成する
Instinct MI300Aとは別にEPYCを搭載する理由は、PCIe Switch経由でRabbit-sというStorage Nodeと直接接続するためらしい。仮にこのEPYCをEPYC 9654と仮定すると、以下のようになる。
- ブレードあたりの性能は理論値で1166TFlops(FP64 Vector)、消費電力7120W
要するにブレード1枚でFP64 Vectorの性能が1PFlopsを超えているわけで、El Capitanの目標である2EFlopsを実現するためにはブレードが2000枚、ノード数が4000で足りる計算である。もっともこれはピーク性能での話で、もう少しマージンを持たせる必要がある。
また消費電力もブレードだけで14MWを超える計算で、もちろん2EFlops/14MWならば十分に効率は高いが、Frontierの時と同じく、もう少し動作周波数と消費電力を下げた構成になりそうな気がする。仮にInstinct MI300AのGPUを2.1GHz動作まで落とし、CPUも3.5GHzあたりまで下げれば、性能は125TFlops(FP64 Vector)まで下がるが消費電力も700Wくらいに収まるだろう。
EPYCもcTDPの最低限である320Wまで下げて運用した場合、ノードあたりの性能は500TFlops、消費電力3120W。ブレードあたり1PFlops/6240Wというところ。少し余裕をみて5000ノード(ブレード2500枚)に増量したとして、Compute Nodeでのピーク性能2.5EFlops、Compute Nodeの消費電力は15.6MW。ストレージやネットワークの分を加味しても30MW程度で収まる計算だ。ノード数がFrontierに比べても少ないから、実効性能で2EFlopsを超えるのも難しくはないように思える。
Instinct MI300Aは6月13日よりサンプル出荷開始、Instinct MI300Xは今年第3四半期中にサンプル出荷開始予定とされる。ちなみにインテルは6月22日、Auroraのインストールが完了したことを発表した。今年11月のTOP500の結果が楽しみである。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ













