
Instinct MI300Xは
8ダイで合計320 XCU
さて、話を戻そう。AMDから提供されたInstinct MI300Xの写真が下の画像だ。

これは斜めになっているものをPhotoshop Workで修正したもの。したがって縦横の比率は正確ではない。ダイのほとんどはXCUで、あとは制御部だけである
8つのGPUのダイに、それぞれ40個のXCUが搭載されているように見える。ということは、8ダイで合計320 XCUである。これはMI250Xの220 XCU(112 XCU/ダイながら2つ無効なので、110 XCU/ダイ)と比べると、わずかに1.45倍の増加に過ぎない。
先に書いたAI性能が8倍というのは、実際にはデータ型の変更(FP16/BF16のサポートに加え、おそらくFP8をサポート)を加味しての数字と思われるので、演算器そのもので言えば4倍になると考えられるのだが、いくらなんでも1.45倍は差がありすぎる。
ただもしここでRDNA 3の時と同様に、1つのXCUあたりの演算性能が2倍に変更されたと考えると、実質640 XCU相当になって演算器の数は2.91倍に増えた計算となる。これならわりとありそうな話である。もちろんこれではまだ4倍に達しないわけだが、Instinct MI250XはPeak Engine Clockが1.7GHzとわりと控えめである。なのでPeak Engine Clockを2.34GHzあたりまで引き上げると考えると、ほぼピーク性能は4倍になる計算だ。この場合、MI300Xの性能は下表の数字になると想像される。
| MI300Xの性能 | ||||||
|---|---|---|---|---|---|---|
| 演算 | 性能 | |||||
| PF64 Vector | 192TFlops | |||||
| FP64 Matrix | 384TFlops | |||||
| BF16 Matrix | 1536TFlops | |||||
| FP8 Matrix | 3072TFlops | |||||
ただし、電力効率が5倍でしかないので消費電力は1.6倍に増える計算だ。Instinct MI250Xがピーク560WとされていたのでInstinct MI300Xは896W、ほぼ900Wというあたりだろうか。

「フォームファクターそのものはOCP(Open Compute Project)のOAM(OCP Accelerator Module)に互換だ」というので「では消費電力もMAX700W?」(OAMは48V供給で最大700W、12V供給で600Wが定格の上限)と聞いたら、笑って誤魔化された
このFP8のMatrixで3PFlopsという値は、NVIDIAのH100の4PFlopsにはややおよばないように見える。ただこれはピーク性能で比較して、という話である。実際には容量は不明ながら、少なからぬであろうインフィニティ・キャッシュと、さらにHBM 3が8ch(H100は6ch)というあたり、実際には互角の性能である公算が高い。もっとも性能が互角だからと言っても、CUDAがそのまま動かないあたりがH100に対する大きなネックであることに変わりはないのだが。
I/Oダイの構造の推定図を下図に示す。これはInstinct MI300Xを上から見た構造図で言えば左下のI/Oダイに相当する(左右対称のI/Oダイもあるはずだ)。インフィニティ・ファブリックのI/Fが4つあるが、上辺と右辺のものはI/Oダイ同士の接続用、そして下辺のものは外部接続用である。と言うのは、Instinct MI300Xを8つ搭載するソリューションが今回も展示されており、この8つのInstinct MI300Xを相互接続するのに7本のインフィニティ・ファブリックが必要である。
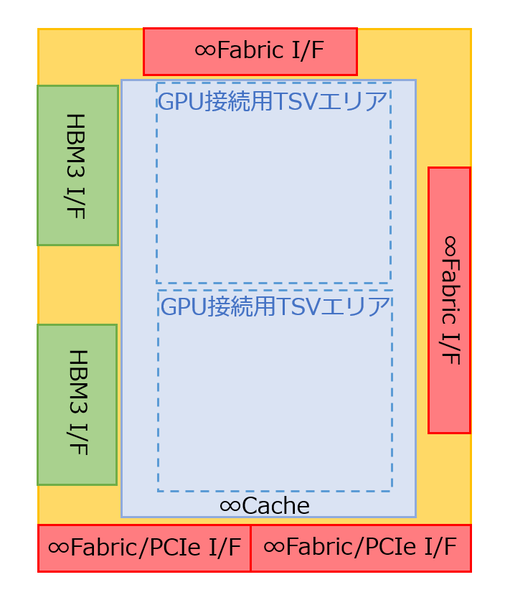
I/Oダイの推定図
ただ7本だけでは相互接続して終わり(外部へのI/Fがない)なので、外部接続にも1本必要になる。4つのI/O ダイからそれぞれ2本づつ外部接続用のインフィニティ・ファブリックが出れば、ちょうど8本というわけだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ













