




学習分野における精度改善を狙う
はたしてGPUを駆逐できるか?
さてここまでの話であれば「実現したらすごいね」で終わるわけだが、同社はすでにTSMCの7nmを利用してCrddinal SN10というチップを製造している。

内部の配線の総延長が50kmというのもあれだが、7nmで400億トランジスタというのは、NVIDIAのA100(520億トランジスタ)よりはやや少ないあたり、ダイサイズはおおむね600平方mm台と想像する
現時点でもまだ正確なスペックは未公開(演算性能数百TFLOPSや内蔵SRAM数百MB、外部に1TBクラスのメモリーを接続可能など)であるが、その性能はなかなか目覚ましい。12月9日に出したリリースによれば以下とされている。
- NVIDIAのDGX A100と比較してDLRM(Deep-Learning Recommendation Model)の推論は7倍のスループットとレイテンシー改善を実現しており、これは世界最高記録。またBERT-Large(Googleが2018年に発表した自然言語処理モデル。BASEとLARGEの2種類のモデルがあり、LARGEは24層+隠れ層1024、総パラメータ3億4000万個)の学習ではDGX A100と比較して1.4倍高速だった。
- NVIDIAのA100 GPUベースでのDLRMの精度は80.46%だったが、SN10ベースは90.23%となった。
もう少し細かい数字が12月14日のEETimesに掲載されているが、こちらによれば以下のような数字が並んでいる。
- SN10を64個搭載したシステムは、BERT-Largeの28800 Samples/secの学習速度を記録して、これは世界記録
- またSN10を8個搭載したシステムでは、DLRMで8632 Samples/secの推論速度を達成し、こちらも世界記録
- 1000億個のパラメーターを持つ自然言語処理モデルのネットワークの学習を、SN10が8個のノード(合計メモリー12TB)で実現できる。同じことをGPUで処理するためには412個の最新GPUが必要で、こちらの合計メモリーは32TBに達する。
実はもう1つ数字がある。ここまでの話はML処理に使った場合の話であるが、データ分析のアクセラレーターとしても利用できるという話である。

サンプルコード。tBというテーブルから条件付きでデータを引っ張ってくる、ほぼSQL的な処理である。ただ物理的にはオンメモリーデータベースであろう
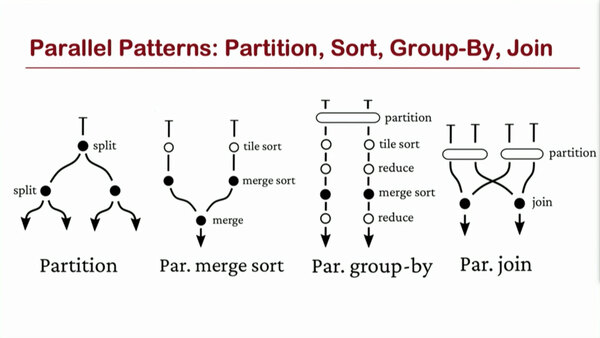
上の画像の処理を行なうにあたっての「パターン」4種類
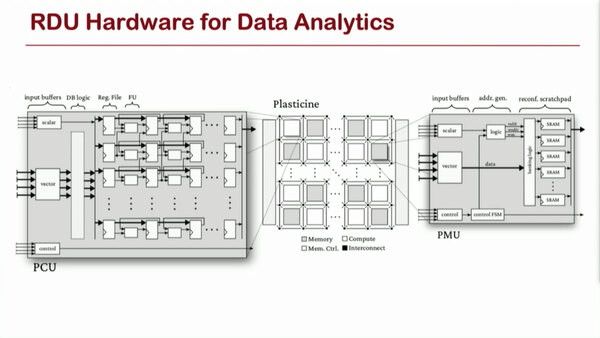
RDUにおける実装例。PCUとCMUで処理を分割して実施する
これを実装したGorgonというソフトウェアフレームワークを、Xeon E7-8890上で同様の処理ができるApache MADlibを走らせた場合と比較すると、絶対性能および性能/消費電力比が200~2000倍向上するとしてる。
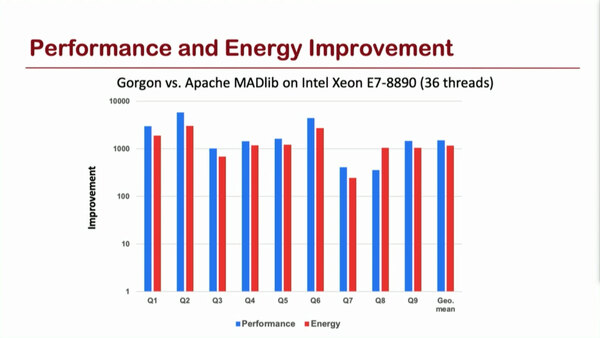
Apache MADlibとの絶対性能および性能/消費電力比。縦軸は改善率であるが、対数軸になっていることに注意
SambaNovaはすでにシステムの提供も開始している。先にSN10が8個、という数字を示したが、下の画像の左側、2Uラック×5段積みのものが8ソケットの構成、1ラック(42U)にはこれが4つ、つまりラック当たりSN10が32個収まる格好だ。

10Uのユニットというよりは、2Uのユニットを5つ重ねているように見える。上下に2つづつSN10を搭載したユニットを重ね、中央に他のノードとつなぐためのスイッチなどを収めたサービスユニットが挟まるものと思われる
システム的にはこれを4つ並べたSN10が128個という構成が最大になる模様だ。

複数のSN10がどういう風に動くのかに関する説明は今のところない。単に別ノードとして動作するのか、それとも連携して動くのか、そのあたりも興味あるところだ。BERT-Largeのベンチマークではラック2本分のSN10が連携して動いているような記述があるあたり、おそらく連携できるのだと思うが、だとするとSN10間のインターコネクトをどうするのかも興味あるところである
実はこのシステム、すでにアルゴンヌ/ローレンス・リバモア/ロスアラモスの3つの国立研究所に納入されて初期の運用が始まっているようだ。また同社はシステム売り以外に、DaaS(Dataflow as a Service)という月単位で計算能力を貸し出すサービスなどもラインナップしているのが特徴的である。
創業からわずか3年でシステム納入まで漕ぎつけた同社のSN10が今後広く採用されるかどうかはまだ見えない部分が多い。
ただGPUがしばしば演算性能を上げるために精度の切り捨て(FP32→FP16あるいはBFloat16)をしているなか、SN10はFP32を保つことで、特に学習分野における精度改善を狙っているのが大きな差別化要因である。はたしてこれでGPUを駆逐できるのか、今後の展開が楽しみではある。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























