



ロードマップでわかる!当世プロセッサー事情 第563回
Ampere採用GPU「A100」発表、Titan Aが発売される可能性も NVIDIA GPUロードマップ
2020年05月18日 12時00分更新

製造プロセスはTSMCのN7
もう少し特徴を細かく説明したい。まずプロセス。以前はSamsungの7LPPであろう、という状況証拠を説明してきたわけだが、これを全部裏切ってなんとTSMCのN7での製造となった。そしてダイサイズは826mm2という、やや信じられないサイズである。
Samsungが7LPPプロセスで量産に入っているのは間違いない。というのは、同社のGalaxy S20に搭載されているExynos 990がこの7LPPを使って製造されており、実際TechInsightがこれを解析、確かに7nmのEUVプロセスを利用して製造していることを確認している。
TechInsightの分析によれば、TSMCのN7と比較してトランジスタ/配線密度が高くなっていることが確認されており、その意味では素性はよさげである。ではなぜTSMCに切り替えたか?
可能性としてあるのは、100mm2程度のモバイル向けSoCはともかく、800mm2オーバーの巨大ダイが作れなかった(いや作れはするが、歩留まりが十分上がらなかった)というのが一番考えやすい。
本当は8GPC、64TPC、128SMで12ch(2chで1つ)のメモリーコントローラーを利用可能なのにも関わらず、実際に出荷されるA100は7GPC、54TPC、108SMに減らされ、メモリーも10chというのは、要するにそれだけ欠陥が多く、フルスペックでの出荷ができないという話である。わりと熟成が進んでいるTSMCのN7ですらこれだから、Samsungの7LPPはさらに厳しかったのだろう。
NVIDIAがDual Fab Strategy、つまりSamsungとTSMCの両方を使うという話は聞こえていたが、てっきり筆者は少なくとも最初の段階ではハイエンドをSamsung、バリュー向けをTSMCとすると考えていた。
理由は簡単でTSMCはすでに生産能力が逼迫しており、NVIDIAが希望する量の生産が難しいからだ。ところが実際には、おそらくGA100自身がSamsung版とTSMC版の両方の開発をほぼ同時に行ない、その結果としてSamsungが落とされるという結果になったようだ。なかなか壮絶な話ではある。
しかしこうなると、続くゲーミング向け、つまりTuringの後継になるGeForce RTX 3000シリーズもやはりTSMCの将来プロセス(N7P、あるいはN6あたり?)か、もしくはTSMCのN5になりそうである。
7nm世代の投入でAMDに大幅に遅れを取ったことを受けてか、NVIDIAはTSMCのN5に関して膨大な量の生産予約をすでに入れたという話も聞こえてきている(非公式な話なので正直どの程度かは不明だが)。
逆に言えば、N7を使う限り初期の生産量はかなり厳しく抑えられることになりそうで、このあたりNVIDIAがどういう方策を取ってくるのか興味あるところだが、いずれにせよ後継製品の投入は今年末~2021年あたりになりそうに思える。
スループットがVoltaより
FP16で5倍、FP32で20倍に高速化
次は演算性能の話だ。下の画像が示すように、SMの中のINT32/FP32/FP64ユニットの数そのものはVoltaと変わらない。したがって、性能差はSMの数×動作周波数ということになる。
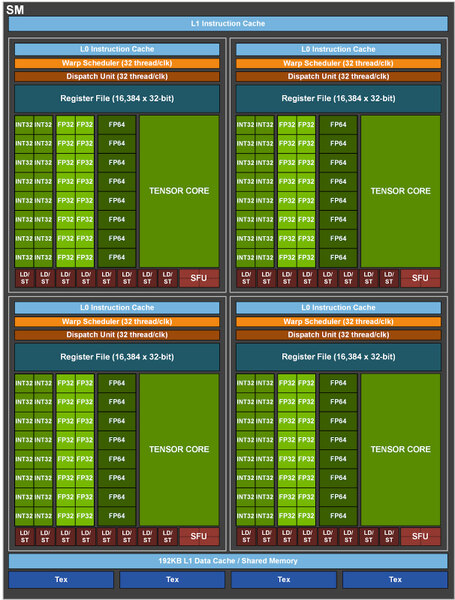
前ページでも示したSMの内部構造
大きく変わったのはTensor Coreである。Tensor Coreは端的に言えばSIMD演算エンジンのようなもので、扱える演算そのものはほぼ乗算と加算のみに限られる代わりに、高速かつ行列演算を簡単に扱える特徴がある。
GV100の場合は扱えるデータ型がFP16(16bit浮動小数点)とFP32(32bit浮動小数点)のみだったが、GA100ではこれに加えてBP16(BFloat16:塩田紳二氏の記事がわかりやすい)やFP64(64bit浮動小数点演算)、INT 4(4bit整数)/INT 8(8bit整数)/Binary(1bit整数)を取り扱えるようになったほか、スループットがFP16で5倍、FP32で20倍に高速化された。

VoltaとAmpereの比較。FP64やINT8はTensor Coreで扱えないが、Ampereではこれも扱えるようになった。また、数字はあくまでもSparsityが有効な場合の理論値で、これが無効だと半減する(それでもFP32とかINT8では10倍だが)
ちなみにここに出てくるSparsityであるが、疎行列への対応である。疎行列というのは行列の成分のほとんどが0というケースである。例えば2行2列の行列の掛け算は下式のようになっている。

2行2列の行列の掛け算
ここで、成分の半分が0の場合を考えると、下式のようになる。
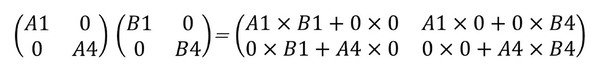
疎行列の掛け算
さて、Sparsityをサポートしていない場合、律義に0×0やA1×0などの計算をするので、トータル8回の掛け算と4回の加算が必要で、しかもこのほとんどが0の掛け算や足し算である。
ところが0の掛け算と足し算はやるまでもなく0なので、これの計算を省くと必要なのはA1×B1とA4×B4の2つの掛け算のみで済む。この「要素が0の場合には計算を省く」というのがSparsityで、これにより大幅に高速化が可能になったというものだ。
加えると、AIのトレーニング向けにはそれなりに精度が必要とされるが、推論の方はそうでもない(この話は次週)こともあり、データの精度を落とした4bit Integerや、中にはBinary(1bit)のネットワークも使われるようになっている。
ただ従来のVoltaはこうしたものに対応していなかったので、FPGAなどが使われていたが、Ampereではこうしたものにも対応できるようになった、という話である。
これによってAI性能は、学習で3~6倍、推論で7倍に達していると説明されており、またHPC関連アプリケーションも1.5~2倍に高速化されるとする。

AI性能は、学習で3~6倍、推論で7倍に達している。MIGの話は次週で説明する
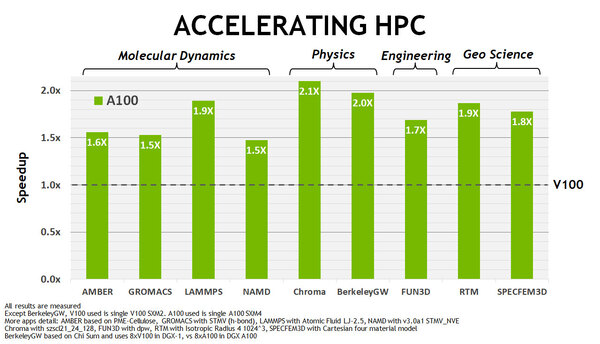
HPC関連アプリケーションも1.5~2倍に高速化。 この発表に先立ちAMDはRadeon Pro VIIを発表したが、こちらはDP(FP64)で6.5TFlopsほどで、V100にも及ばない程度(ただし桁違いに安い)である。ただAmpereはかなり廉価に設定されており、絶対価格はともかく価格性能比でRadeon Pro VIIにかなり迫っているようにも思われる。このあたりはAMDの次のCDNAがどういった性能/価格で投入されるか次第ではある
Ampereが、まずはPerlmutter向けに投入されることを考えると、これは重要なポイントである。
もう1つ、Volta世代から大きな進化を遂げたのがMIG(Multi-Instance GPU)である。特にデータセンターでの利用の場合、複数ユーザーでGPUを使うことも珍しくないのだが、従来ハードウェア的には1枚のGPUは1ユーザーでの占有という形になっていた。
これに対し、GA100ではGPC単位で異なるユーザーに割り当て、別のアプリケーションを走らせることが可能になっている。
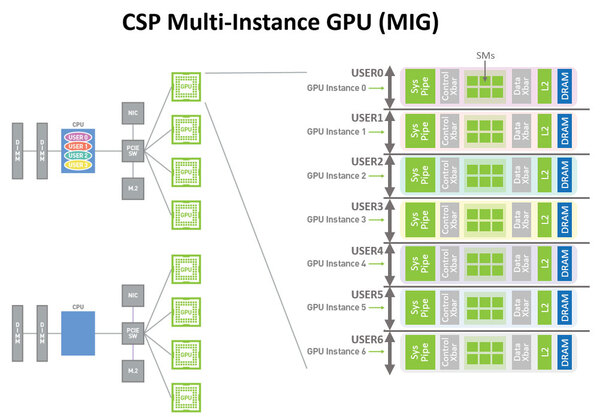
これも本当は8つまで可能ながら、GA100が実際には7GPCの構成で出荷されているので、インスタンスも7つまでに制限されていると思われる
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ


















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





































