




AMDのMilanにNVIDIAの次世代GPUを組み合わせた
Pre-Exascaleシステムの「Perlmutter」
2017年にAuroraの位置付けが変わった結果として、ロードマップがどう変わったのか? というのが下の画像だ。
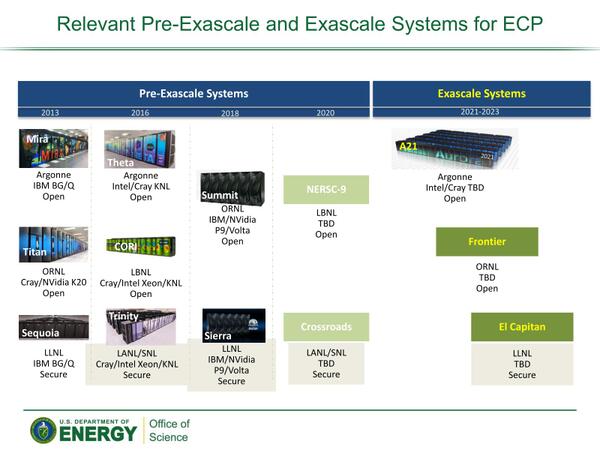
ECPのロードマップ。Pre-ExascaleとExascaleでロードマップが分かれることになった
画像の出典は、2018年5月のBarbara Helland氏によるHigh Energy Physics Advisory Panel向けの“Advanced Scientific Computing Research”
まず2020年までに、Summitの後継システムであるNERSC-9がローレンス・バークレー国立研究所に設置される。こちらはEdisonのアップグレードという話になっており、Edisonが2019年5月13日に退役するのを受けて設置される。
このNERSC-9はPerlmutterという名前のシステムで、2020年末までにインストール、2021年に運用開始を想定している。
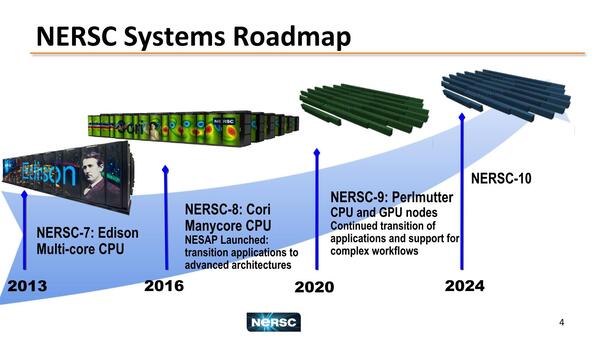
NERSCのロードマップ。2024年にはさらにNERSC-10にアップグレードされる模様
画像の出典は、Katie Antypas, Brian Austin, Brandon Cook氏によるNERSC User Group向けの“NERSC-9”
このPerlmutterがまたおもしろい構成で、AMDのMilan(つまり7nm EPYCの次の世代)にNVIDIAの次世代GPU(Volta-Next)を組み合わせたものになる。
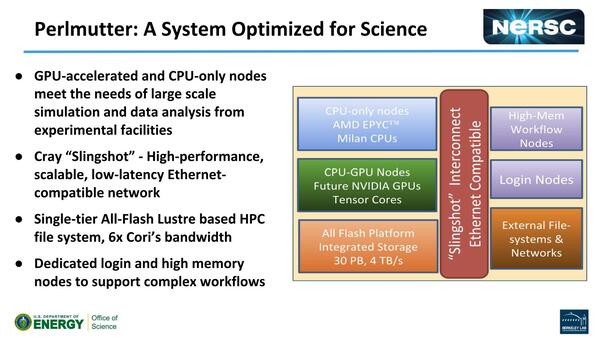
Perlmutterもまた主契約者はCrayで、ShastaアーキテクチャーとSlingshotインターコネクトを核に、MilanとVolta-Nextを組み合わせる形になる。ストレージがAll Flashで容量30PB、帯域4TB/secというのもすごい
画像の出典は、Katie Antypas, Brian Austin, Brandon Cook氏によるNERSC User Group向けの“NERSC-9”
Volta-nexttについての説明はないのだが、今年3月に行なわれたGTCの最終日にPerlmutterの説明が簡単にあった。

GTCでのPerlmutterの説明。これを「Voltaの4倍」と見る向きもあるのだが、実際にはPerlmutterの構成はCPU/GPU混載ノードがCPU 1:GPU 4の構成になるので、こっちの意味ではないかと思われる
画像の出典は、GTC Silicon Valley 2019における“S9809,Perlmutter- A 2020 Pre-Exascale GPU-accelerated System for NERSC: Architecture and Application Performance Optimization”
ただNVIDIAとしてもまだVolta-nextの詳細は秘密にしておきたいようで、現時点では性能がどの程度かさっぱりわからない。
PerlmutterではおそらくVolta-next同士はNVLINK-3を使って接続され、これとMilan CPUやSlingshotとはPCIeでの接続になるものと思われる。NVLINK-3が実はCCIXと互換だといろいろ変わってくるが、そのあたりは今のところ不明だ。
ちなみに使い方もなかなかおもしろい。従来のXeon Phi用のコードはCPUのみのノード(およそ4000ノード)で処理するが、これがCori(30PF)と同程度であるという。

要するにXeon PhiのコードをNVIDIAのGPUに持ってくのは無理ということだ。Xeon Phiそのものがそんな感じなので、これは仕方ないだろう
画像の出典は、Katie Antypas, Brian Austin, Brandon Cook氏によるNERSC User Group向けの“NERSC-9”
一方CPU/GPU混載ノードはおおむねCoriの2倍以上の処理性能となっており、全体としては90~100PF程度の性能になるものと思われる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ











ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")











ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












