



内部データパスはTuringの2倍
GeForce RTX 30-Series Tech SessionsでわかったAmpereが超進化した理由
2020年09月05日 06時00分更新


CUDAコアが前世代に比べ2倍以上の増加し、RTコアもTensorコアも刷新されたGeForce RTX 30シリーズ。GeForce RTX 3080は9月17日より販売解禁となる。なお、写真のFounders Editionの国内正式販売はない
2020年9月2日、NVIDIAのCEO、ジェンスン・ファン氏は先日オンラインで開催した「GeForce Special Event」において、既存のGeForce RTX 20シリーズの性能をはるかに上回る(と主張する)「Ampereアーキテクチャー」と、それを採用した「GeForce RTX 30シリーズ」を発表した。非常に多くの内容を40分程度にまとめた超高濃度かつハイスピードなセッションだった。
今回はそのGeForce Special Eventに続き、プレス向けに開催された「GeForce RTX 30-Series Tech Sessions」の内容の内、Ampereアーキテクチャーやその他注目度の高い機能について解説しよう。
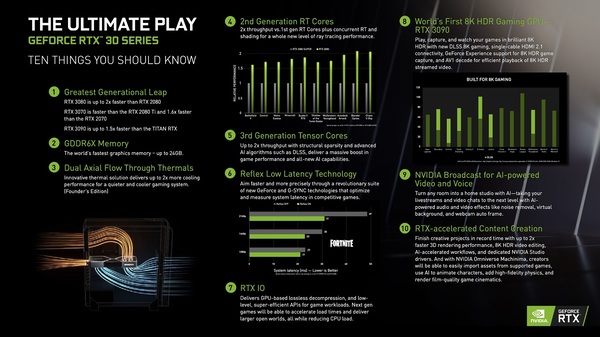
NVIDIAが作成したGeForce RTX 30シリーズの“まとめ”的な画像。(1)性能の大幅向上、(2)GDDR6Xメモリー、(4)第2世代RTコア、(5)第3世代Tensorコア、(6)新たな低遅延機能「NVIDIA Reflex」、(7)ゲームのロード時間短縮が期待できる「RTX IO」、(8)8Kゲーミング向けの「RTX 3090」、(9)AIを利用した配信/ビデオ会議支援「NVIDIA Broadcast」、(10)RTXをクリエイティブ作業にさらに活かす、などが語られている
内部データパスが2倍になった内部構造
まずはAmpereアーキテクチャーの概要から見ていこう。冒頭でも述べた通り、Ampereは前世代のTuringからCUDAコアを2倍以上に増やし、さらにRTコアとTensorコアに改良を加えることで、スループットを向上させている。
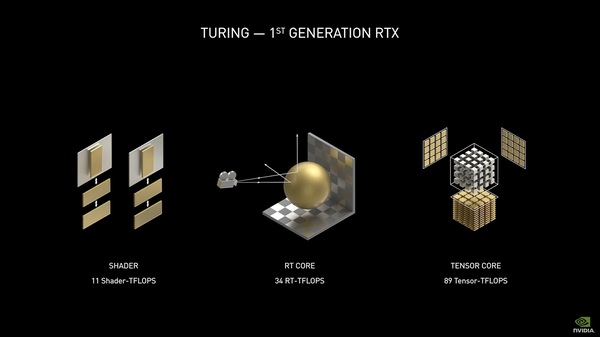
GeForce RTX 20シリーズ(Turing)はCUDAコアのほか、レイトレーシング処理の一部を担当するRTコアに、AI処理を担当するTensorコアの両方を備えているのがトピックだった
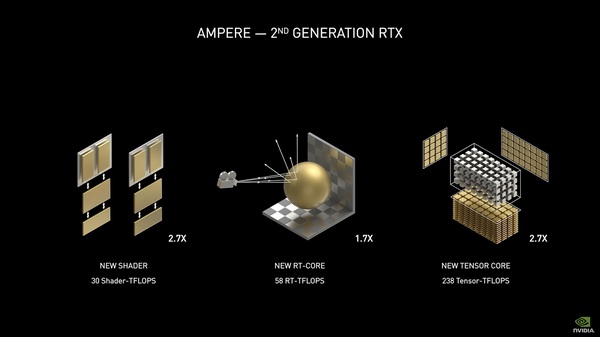
GeForce RTX 30シリーズ(Ampere)ではRTコアとTensorコアの世代を進め、すべての部位においてTuring世代よりも飛躍的な性能向上を果たした、とNVIDIAは謳う
次に、GeForce RTX 3080全体の大構造を眺めてみよう。AmpereではCUDAコアが倍以上に増えているのが特徴だが、大構造(L2キャッシュ〜コアのクラスター〜メモリーコントローラーなど)はTuringから大きく変化していない。GeForce RTX 2080 SUPERとRTX 3080を比べると、メモリーバス幅が256bit→320bitに拡幅されたぶん、メモリーコントローラーが増えているが、大構造は似たようなものだ。

GeForce RTX 2080 SUPERで使われているTU104コアのブロック図(概念的なもの)。48基のSMのそれぞれに64基のCUDAコアが収まっている。メモリーコントローラーは32bit幅のものが8基なので、バス幅は256bitとなる

GeForce RTX 3080に使われている「GA102」コアのブロック図。SMは68基あり、各SMに128基のCUDAコアが格納されている。SMが10基のブロックと12基のブロックがあるので、すべて12基のブロックで構成された“GA102の完全体”(フルスペック)が今後出てくる可能性は十分考えられる
しかし、コアのクラスターを構成するGPC(Graphics Processing Cluster)の内側に入っている小クラスター、すなわちSM(Streaming Multiprocessor)の構造は大きく変化した。SM1基の中に4つのパーティションがあり、その中にCUDAコアが入っているのは同じだが、Turingでは1パーティションあたりCUDAコアが16基だったのが、Ampereでは32基に増えている。
さらにAmpereではこの32基のCUDAコアを2つのグループに分け、2つのデータパス上に並べている。データパスの1つはTuringと同じようにINT32かFP32オペレーションのどちらかを実行できるが、もうひとつのデータパスはFP32オペレーション専用となる。
この構造のおかげでAmpereのSM内にあるパーティションは、32のFP32オペレーションの実行か、16のINT32オペレーション+16のFP32オペレーション同時実行のどちらかを選択できる。ひとつのデータパス内にINT32とFP32を混在させることはできない。つまり、全部INT32オペレーションの場合はCUDAコア数は実質半減してしまうことになるが、現実のゲームではFP32の処理が圧倒的に多いので、FP32専用のデータバスを用意したことは極めて理にかなった改善と言えるだろう。
また、AmpereではSM1基ごとに設置されているL1キャッシュの容量を128KBに増量している。TuringのL1は96KBなので、ざっと33%の増量となる。
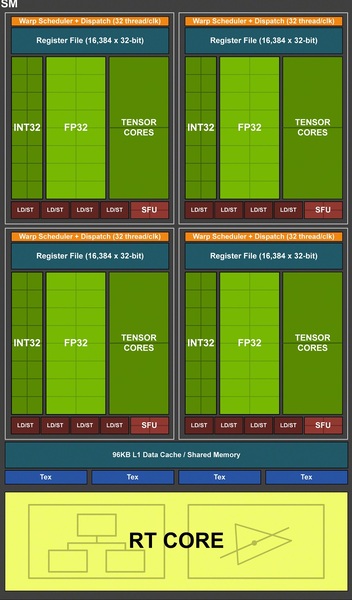
TuringにおけるSMの構造。CUDAコアはINT32とFP32の部分になるが、各々16基ずつあるもののINT32かFP32のどちらかしか同時に使えないため、INT32+FP32でCUDAコア1つとカウントされている

AmpereではFP32専用の部分と、INT32とFP32の共有の部分を別々のデータパスに載せ、同時に処理を走らせられる。ゆえに、CUDAコア数のカウントが単純に倍になっているのだ。L1データキャッシュ(兼共有メモリー)が128KBに拡張されている点にも注目
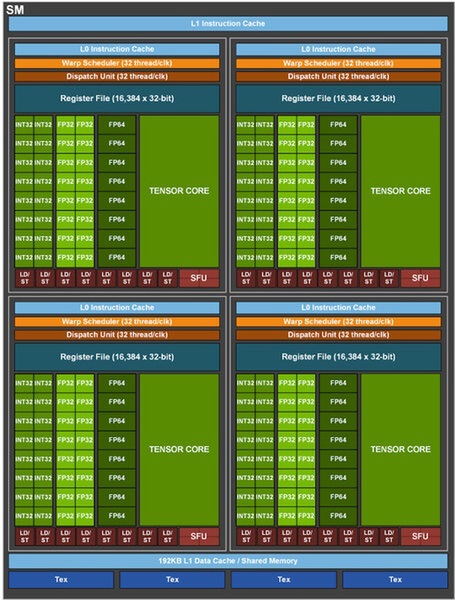
ちなみに、こちらは大原氏の記事にあるHPC向けAmpere「A100」のSM構造図。コンシューマー向けのAmpereにはないFP64が存在し、INT32とFP32でコアが分かれ、L1キャッシュも192KBと多い
本記事はアフィリエイトプログラムによる収益を得ている場合があります





、バッテリー駆動時間は13時間超え。もう欲しくなる要素しか見つからないッ!")








ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")






