




























日本のAIビジネスの成長を促す知財と契約のあり方とは
NoMaps2019セッション「AI開発における知財の取り扱い~Win-Winの関係構築に向けて~」レポート
セキュリティー、自動制御、マーケティング分析、自動翻訳などなど、あらゆる用途での活用が高まるAI技術だが、開発における知的財産権の取り扱いは未整備の状況だ。日本のAIビジネスを発展させるためには、知財をどのように扱うべきなのか。NoMaps2019ビジネスカンファレンスでは、特許庁とASCII STARTUP協力によるセッション「AI開発における知財の取り扱い~Win-Winの関係構築に向けて~」を開催。AI関連技術開発の現状と、知財の帰属や利用条件の定め方についてディスカッションした。

パネリストとして、AWL株式会社CTO 兼 AI HOKKAIDO LAB所長 土田 安紘氏と、佐川慎悟国際特許事務所 所長弁理士/日本弁理士会北海道会 副会長の佐川 慎悟氏が登壇。司会は、特許庁企画調査課 スタートアップ支援チーム 課長補佐 進士千尋氏が務めた。

進士千尋氏 特許庁企画調査課 スタートアップ支援チーム 課長補佐

土田 安紘氏 AWL株式会社 取締役CTO 兼 AI HOKKAIDO LAB所長

佐川 慎悟氏 佐川慎悟国際特許事務所 所長弁理士/日本弁理士会北海道会 副会長
冒頭では、特許庁の進士氏がスタートップの知財戦略と特許庁の支援施策を紹介。スタートアップにとって、企業価値≒知的財産。知財はスタートアップにとって必須であり、独占だけでなく、大企業との連携や資金調達時の信用のツールにもなる。特許庁では、1)知財アクセラレーションプログラム(IPAS)、2)スタートアップのスピード感に対応したスーパー早期審査、3)特許に関する手数料を3分の1に減額、4)スタートアップ向けの知財ポータルサイト「IP BASE」の開設、5)イベントやセミナーを全国で実施している。
続いて、土田氏が機械学習×知財の状況を解説。現在主流の機械学習系AIは、「フレームワーク」、「基礎技術」、「応用技術」の3層に分けられる。
フレームワークは、AI開発に用いるライブラリ群。AIエンジニアは、既存のフレームワークを使ってAIを開発している。基礎技術は学習方法で、アメリカ、カナダ、中国が先行。日本のAIビジネスの多くは、応用技術に当たるアプリ開発に特化している。なお、フレームワークに関する多くの特許はGAFAが持っているが、オープンソースライセンスなので、誰でも無償で利用可能だ。

機械学習関連技術は、フレームワーク、基礎技術、応用技術の3層構造
AIアプリの開発は、ラベル付けされたたくさんのデータ(データセット)を学習させることで学習済モデルを作成し、この学習済モデルをアプリに搭載している。
だがここで、頭に入れておいたほうがいい3つの知財上の問題も語られた。
1つは、データセットの著作権の問題。データセットを作るには、大量のデータが必要だが、インターネットからデータを集める場合、著作権者が存在する。これについては、日本の法律上ではネット上のデータを機械学習に使う場合は、著作権侵害には当たらず、自由に使えるとのこと。収集したデータセットの販売も可能だ。
2つ目は、AIが創作したものの著作権は誰に帰属するのか。過去には、絵画の巨匠レンブラントの絵画を学習したAIが創作した絵の著作権は誰に帰属するのか? と話題になったが、この問題はいまだに未決着だ。
3つ目は、学習済モデルの知財権。学習済みファイルは単なる数字の羅列なので、特許化したとしても侵害立証はほぼ不可能と言われている。
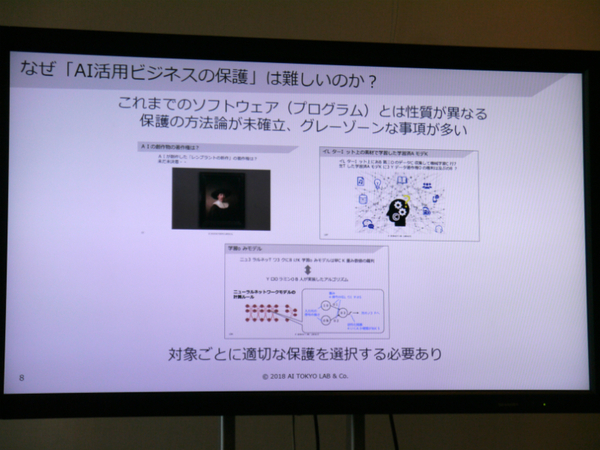
AIはこれまでの一般的なソフトウェアとは性質が大きく異なるため、保護の方法論が確立していない
では、どのようにAI技術を知財で保護するのか。土田氏は、学習済モデルではなく、データセット化する部分に着目し、特徴的なデータの集め方やラベルの付け方について権利化することを勧めている。特許にこだわらず、著作権法や実用新案権などさまざまな法律で権利化して、自社の知財を守っていくことが大事だ。
AI開発の委託元と委託先がともにWin-Winになれる2つのパターン
土田氏と佐川氏によるパネルディスカッションでは、「AI開発成果物の知的財産権は誰に帰属する? 誰が利用できる?」をテーマに議論した。

AIを委託開発する場合、データセット化や機械学習のノウハウをもつのは委託先のベンダーであり、これらの知的財産権は委託先にある。学習済モデルをアプリ化するのは委託元なので、アプリの権利は委託元にあるといえる。
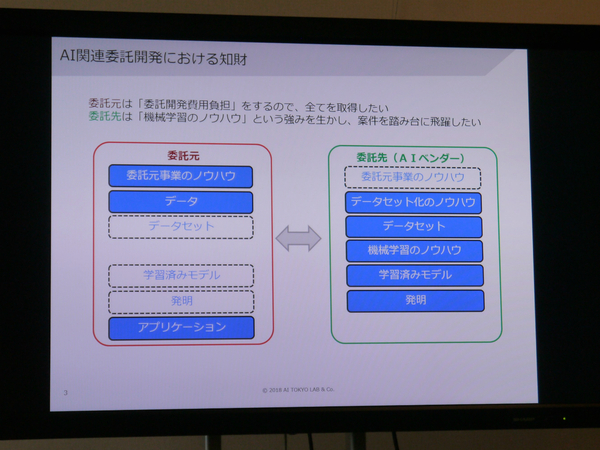
とはいえ、委託元は、開発費を負担しているのだから、すべての権利を取得したい。他方で委託先であるAIベンダーはベンチャーが多く、開発で得られたノウハウを横展開して成長したいという気持ちをもっている。両社がWin-Winの関係を構築するためにはどのような契約形態が考えられるのだろうか。その例として土田氏、佐川氏がそれぞれのアイデアを紹介した。
土田氏の提案は、学習モデルの知財権は委託先ベンダーが所有し、委託元のA社の同業他社のB社、C社などに対しても学習済モデルを提供できる、とするもの。ベンダーは、B社、C社からも学習に使うデータと使用ライセンス料を得て、データセットをアップデートできる。
委託元のA社は、委託開発費を支払うため初期コストはかかるが、B社やC社から得たデータを加えた最新の学習済モデルが使え、ベンダーが他社から得たライセンス収入の一部も得らえるのがメリット。委託先ベンダーは、複数の会社からデータとライセンス料を得ることによって、継続して開発を続けられ、学習済モデルの精度も高められる。
A社としては、競合他社にはライセンスしたくないかもしれないが、制限によってAI技術の発展やベンチャーの成長機会が妨げられるのは好ましくない。「A社と委託先のベンチャーが連携しながら、技術をライセンスし、ともにビジネスとして発展する形をとるべき」と土田氏。
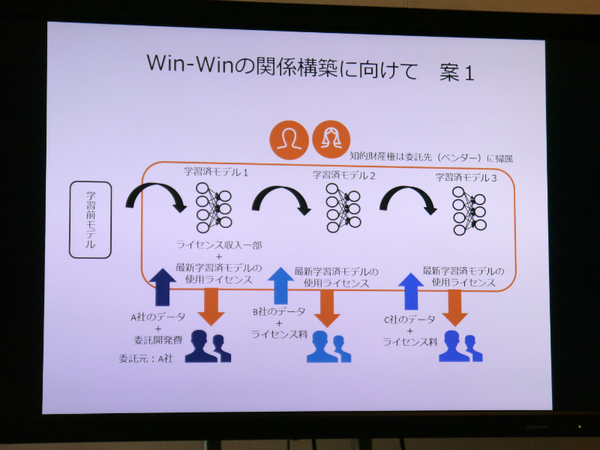
知財権は委託先ベンダーが所有し、委託元はライセンス収入の一部を得る
土田氏の案は理想的だが、現実には委託元が大手企業であることが多く、権利が持てないことによって起こるリスクを嫌う傾向がある。そこで委託先ベンダー側が委託元A社に配慮したものが佐川氏の案だ。
佐川氏の案は、学習済モデルの知財権はベンダーが所有するが、一定の期間は委託元A社の独占ライセンスとし、同業他社に対しては学習済モデルをライセンスしない、という契約にするものだ。なお、他業種の企業向けには、期限を設けずに利用可能とする。委託先のベンチャーにとっては他業種向けに展開する発想をもつことで、受託型から提案型へとシフトするチャンスになる。
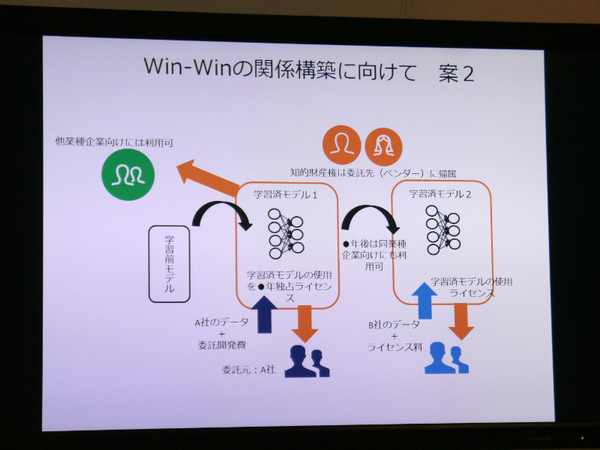
委託元は、一定期間は独占的にライセンスを使用できる
土田氏によると、AIベンチャーが大手企業から受託でAI開発をする場合、大手側からはAIでの知財も含めた包括的な契約内容を提案されることが多いという。
委託元としては、一般的なシステム開発とAI開発が違うという認識はないため、AI開発もシステム開発の延長上にあると考えている。そのため、契約内容も従来のシステム開発と同じ形式になってしまっている。
ユーザーにとってのAI開発のメリットは、競合他社よりも優れたAIを使うことによって生まれる優位性にあるが、より良いAIのほうが作業効率やサービスの質は向上する。であれば、1社独占にするよりも、土田氏の提案のように業界全体のデータを集めたほうが、より精度の高いAIになるはずだ。
また、依頼元が知財を所有したがる意味を考えた場合、AIを開発しない企業が権利を持っていても使い道がない。それよりもベンチャー側に知財をもたせたほうがAI技術を発展させることができる。権利を共有するという手もあるが、横展開したいときに、必ず共有者の同意を得なくてはならず、AIベンチャーにとって足かせになってしまう。共有することで相手の同意を得やすく、所有コストも半分で済む、というメリットもあるが、その後の展開のためには、できるだけ単独所有にしたほうがいいだろう。
将来的には、地域特有の課題解決にもAIの活用が期待される。しかし、都心や海外のAI企業が地域の課題に寄り添った製品やサービスを開発してくれるかどうかは疑問だ。地域の大企業や公的機関は、地域のAIベンチャーが生まれ、成長しやすい環境をつくっていくことが大事だとセッションでは締めくくられた。
本記事はアフィリエイトプログラムによる収益を得ている場合があります




