




























ストックマーク、日本語ドキュメント読解に強みを持つマルチモーダル基盤モデル「Stockmark-2-VL-100B」公開
ストックマーク株式会社は、複雑なビジネス文書でもハルシネーションを抑止した読解が可能というドキュメント読解基盤モデル「Stockmark-2-VL-100B」を公開した。

「Stockmark-2-VL-100B」は、経済産業省とNEDO(国立研究開発法人 新エネルギー・産業技術総合開発機構)が実施する国内の生成AI開発力強化を目的としたプロジェクト「GENIAC」第2期に開発された。同モデルは、同じく「GENIAC」第2期に開発・公開した日本語特化LLM「Stockmark-2-100B-Instruct-beta」に、図表や画像を含む複雑なビジネス文書を多数学習させたマルチモーダル基盤モデルで、日本語のドキュメント読解に高い性能を有しているとのこと。
また、生成AIが複雑な質問に回答する際に、すぐに最終的な回答を出すのではなく、回答に至るまでの中間的な思考過程を段階的に生成する「チェーンオブソート(Chain of Thought、CoT)」を実現することで、ビジネスシーンでも信頼して活用することが可能だとしている。
日本語ドキュメントの読解能力について、同社では比較による性能評価を実施。一般的なマルチモーダル基盤モデルの性能評価で用いられる「Chart-QA-val」から100問をランダムに抽出し、日本語翻訳を行った「JChartQA」と、同社が独自に開発した日本語およびビジネス領域におけるドキュメント読解性能を評価する「BusinessSlideVQA」を用いて性能を比較したところ、双方の評価でGPT-4oを上回る結果となったそうだ。
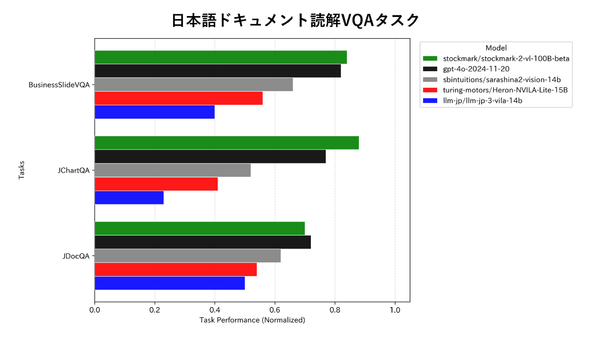
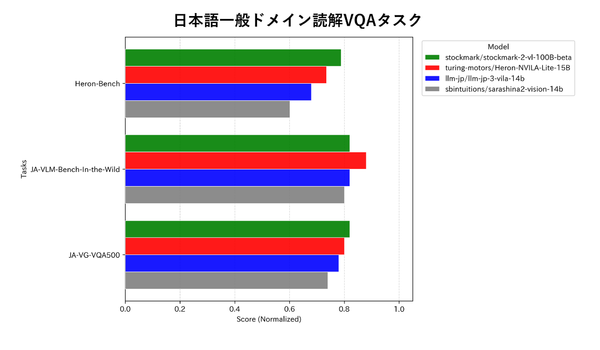
同社によると、一般的な画像読解能力においても国産モデルの中では最高クラスの性能を有しているとしており、ドキュメント読解に限らず多方面で活用できることを示唆しているとのこと。

本記事はアフィリエイトプログラムによる収益を得ている場合があります
