




今回はフランスKalray社のMPPA(Massively Parallel Processor Array)を紹介したい。フランスのプロセッサー会社というのはそれほど数が多くはないが、Kalray以外にも独自プロセッサーIPから最近はRISC-Vに鞍替えしたCortus S.A.S.などがあるし、2014年に同じフランスのAtoSに買収されたが、Bullというコンピュータメーカーもあった。
古い話ではACRIなどもあるため、フランスの会社がすごく珍しいわけでもない。そしてKalrayは意外にも老舗であり、実は日本でもけっこうがんばって販売しようとしていた。

KalrayはもともとCEA(Le Commissariat à l' énergie atomique et aux énergies alternatives:フランス原子力・代替エネルギー庁)のFrench Labから独立する形で2008年に創業したメーカーである。
当初のCEOはJoel Monnier氏で、当時STMicroelectronicsのCorporate Vice Presidentからの転職で、2018年の株式上場にともない現在のEric Baissus氏にバトンタッチするまでCEO職を務めていた。
リアルタイムで処理ができて
プログラミングが容易なプロセッサーを開発
Kalrayは当初、データプロセシング向けのスペシャル・プロセッサーを開発していた。もともとCEAのラボの時代から、どうも大量のデータをリアルタイムで処理できるようなプロセッサーを研究していたようで、2015年のHot Chipsでは同社のMPPAの目的を「Time-Critical Computing(実時間処理)が可能ながらプログラミングが容易なプロセッサー」としている。

time-critical computingとHigh Level Languageでのプログラミングが、既存の製品では両立しないのが問題という話。それは良いが、一番下にIntel MICが出ているあたりが2015年という時期を感じさせる
当時のことなので、まだFPGAはVerilogなどの専用言語が必要で、DSPもまだCなどの高級言語で記述というのは難しく、その一方でGPUやメニーコアプロセッサーではTime-critical Computingは難しいというわけで、この境目を狙った格好である。
ここで言うTime-Critical Computingというのは、要するに「ある一定の処理が、一定の時間で処理可能であることを保証できる」仕組みである。

Time-Critical Computingの説明。下に出ている「軍需航空や自動運転、金融取引、物理制御、ロボットや設備制御」などが主な用途だが、元はCEAということを考えると最初のターゲットは発電所のシステム管理などを狙ったのではないかという気もする
この「一定の時間」というのが難しいところで、例えば「1分以内の制御」なら、GPUやIntel MICなどでも間に合うはずだ。ところが「1秒以内」と言われると「たぶん大丈夫だけど、たまに怪しいことがある」となり、「ミリ秒以内」になると「保証はできない」ということになる。
どのあたりに狙いを定めるかだが、“Execution timing issues”で投機実行や分岐予測、あるいはコア間のリソース(キャッシュ/バス/デバイス)の競合、Cache turbulenceなんていう項目まで出てくるあたり、MPPAはミリ秒~マイクロ秒以内のTime-Critical Computingを狙ったものに見える。
この結果としてMPPAは、DSP風の演算ユニットを、C/C++などの高位言語でプログラム可能で、しかも多数のコアを同時に動かすという構成を取ることになった、としている。

MPPAの概要。このあたりはわりと良く見かける話である。実装がうまくいくかはまた別の問題だが
こうしてできあがったのが、同社の第2世代のMPPAであるBostanプロセッサーことMPPA-256である。VILWにすることでIn-Orderのまま命令を同時に多数実行できるし、Out-of-Order実装にともなう不確実性(実行までの時間が不定になる)は避けられるし、メカニズムそのものも簡単になるので、多数のコアを集積する際にダイサイズの肥大化を抑えられる。
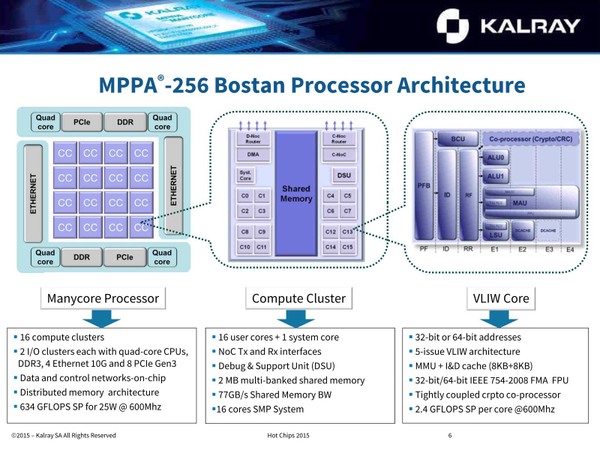
BostanことMPPA-256の概要。ベースのコアはVILWで、このコアを16個集積したクラスターをさらに16個集め、それぞれをNoC(Network on Chip)でつないだのがMPPA-256となる。ちなみにBCUは命令数には入っていない
コアそのものは8KB L1 I+Dキャッシュしか搭載しないが、これを16コア集めたクラスターでは2MBの共有メモリーが搭載されている。コアあたり128KBという計算になるから、L2キャッシュ代わりとして利用するには十分だろう。外部I/FはDDR3とPCIe Gen3、10Gイーサネットであるが、2015年という(Bostonのテープアウトは2013年だった)ことを考えれば妥当な構成である。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ


























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






























