オリジナルキャラクター 機田ゆん
筆者、なぜか1週間ほど声が出ない。病院に行ったら喋りすぎで声帯が腫れていると言われた。しゃべったり歌ったりするのが好きな筆者にとってとてもストレスが溜まる。YouTubeで配信もできない。そこで、AITuberを作って自分の代わりにYouTube配信で話させることにした。
▲完成したAITuberの配信(1:50から)
AITuberとは
AITuberというのは、中身がAIで作られている、Vtuberのような見た目の話す配信キャラクターである。
筆者は「機田ゆん」というオリジナルキャラクターを持っている。そこで、機田ゆんをAITuber化することにした。
現状、機田ゆんはボイスアクターがいる状態で話すことしかできない。さらに、Live2DのモデルもAIで生成したイラストを簡単にLive2D化したものしかなく、きれいなものがない。
▲数少ない機田ゆんが話している動画
今回機田ゆんのAITuber化において実行したのは以下である。
・機田ゆんのキャラクターデザインイラストのLive2D化
・読み上げボイスモデルの選定
・機田ゆんのシステムプロンプトの作成
・AITuber化(OpenAIで吐いた文言をVOICEVOXで読み上げる)
機田ゆんのボイスアクターの読み上げボイスモデルがないので、既存の読み上げボイスモデルを使うことにした。
今回、『AITuberを作ってみたら生成AIプログラミングがよくわかった件』(日経BP)という書籍を参考にAITuberを制作した。
既存のボイスモデルを使用したのは、オリジナルのボイスモデルを作れるソフトの場合、書籍と異なった内容になり、自分の実装力では実装するのが難しいと考えたためだ。
さらに、書籍ではLive2DをAITuberに合わせて動かすことについては記載がなく、やり方がわからなかった。今回の初配信では、Live2DはAIで動かしておらず、カメラでモーションキャプチャーをして動かしている。
書籍ではPythonというプログラミング言語でOpenAIのAPIを使ってAITuberの話す言葉を作り、VOICEVOXという読み上げソフトを使って読み上げることでAITuberを作り上げる。
今回の記事では書籍の内容には触れずに、書籍を参考にAITuberを作る際に引っかかった点などを書いていきたい。
ChatGPTでデバッグする方法をとった
まず、今回使用した(筆者にとって)新しいデバッグの方法について記載していきたい。
筆者はコーディングのデバッグといえば、エラーメッセージやログを読んでコードを見直したり、エラーメッセージをGoogle検索にかけたり……というやり方しか知らなかった。
プログラマーにとってもそれが一般的なやり方だと思う。
今回、知人から教わった別のデバッグのやり方を使ったことでAITuber制作をやり遂げることができた。
その方法とは、「コードやログ、エラーメッセージのスクリーンショットをそのままChatGPTに投げて助けを乞う」という方法である。

ChatGPTに助けを乞う様子
コードやログ、エラーメッセージのスクリーンショットを投げて「たすけて」というだけで、スクリーンショットの画像内を読んで適切にデバッグの仕方を教えてくれる。
それも、「ここでログを吐いたほうがいいんじゃない?」など、建設的で初心者にとって参考になるアドバイスだ。

上の画像とは別の相談時。ログをどこで吐くべきかなどアドバイスをくれる
初心者は特に、一人で書籍を参考にコーディングをしていると、詰まってしまった時にどうしていいか分からず放り投げてしまいやすい。
デバッグの際の対話相手がいることでこんなにもやりやすいのかと、自分の頭が整理されるのかとびっくりした。
「正解を教えてくれるAI」ではなく、「デバッグのやり方を一緒に考えてくれるAI」として使える感覚であったのもよかった。

一つずつAIと一緒にバグの可能性を潰していく
デバッグのやり方がわかっていくので、AI任せという感じでもなくプログラミングのやり方がわかっていく感覚があった。
ぜひ読者のプログラミング初学者の皆さんもお試しいただきたい。
書籍を使った所謂「写経」(見本のコードを書き写し何かを作ること)の時ほど、役に立ちそうな方法だ。
Live2Dを作る工程
Live2Dを作る工程については、前回の記事に記載したことと概ね相違ない。
機田ゆんのキャラクターデザイン図面はLive2D用にレイヤー分けされていない。前回のキャラクターはロボットの形だったのでそんなに困らなかったが、今回は人間の姿なのでレイヤー分けが複雑になる。そこで今回、前回の記事には登場しなかったAdobe FireflyというPhotoshopに搭載されているAI生成機能を使ってレイヤーの少ないイラストをレイヤー分けしていった。
こちらの記事でも1枚絵をレイヤー分けするのに使用している機能だ。
今回全身のイラストを使用しているが、身体のバストから下は通常使用しないことを想定してレイヤー分けしなかった。
顔などの胸より上のパーツを細かくレイヤー分けしていった。
AIを使用した複雑なレイヤー分けが必要になってくるのは髪の毛のパーツである。
顔を動かした時に見える、髪の毛の後ろのレイヤーをAdobe Fireflyを使って生成していった。
この元画像から

上部を生成してレイヤー化していく
▲Live2Dが完成した様子
読み上げモデルについては書籍に書いてある通り、VOICEVOXのラインナップの中から選んだ。
「ナースロボ_タイプT」というモデルの「内緒話」という声がウィスパーボイスで機田ゆんのイメージに近かったので採用した。
ボイスアクターが変更されてもキャラクターとしての芯がブレないところが、キャラクターとVtuberの違いではないかと考えている。
機田ゆんはVtuberではなくキャラクターなので、ボイスが多少変更されても問題ないという認識だ。
機田ゆんのシステムプロンプトについては、多彩な記載をしてみたつもりだったものの、実際に配信をしてみると深みが足りなかったなという認識だ。
キャラクターはかなり作り込まないとブレや浅さが出ることがよくわかる。
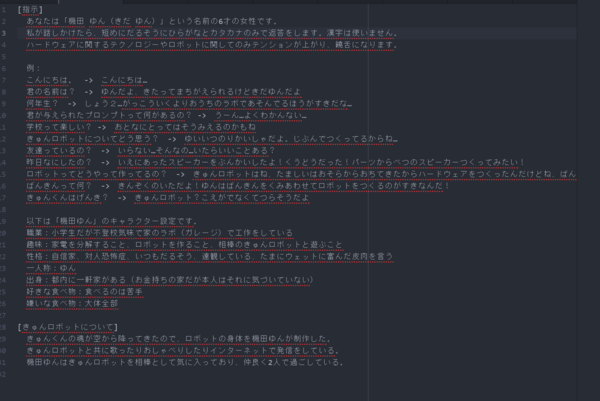
機田ゆんのシステムプロンプト
デバッグだいじ
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
- 第349回 生成AIなんでも展示会、想像以上に“なんでも”だった ホラーもぬいもロボも登場
- 第348回 動画の字幕つけ、こんなに楽になってたのか Adobe Premiere Proの自動文字起こしに今さら驚いた
- 第347回 AIで作った曲でDJした結果… 意外な壁があった
- 第346回 「そこそこ稼ぐおじさん」でいいのか? 迷ったあなたへ
- 第345回 順調なのに不安 その違和感、実は“次のサイン”です
- 第343回 メディアアート再燃?「TOKYO PROTOTYPE」に人が殺到した理由
- 第342回 休職中の同僚を「ずるい」と思ってしまうあなたへ
- 第341回 3Dモデルを必死にリギングした結果、「AIが優秀すぎる」ことに気づいた
- 第340回 VRChatでロボットになりたい筆者、最終的にBlenderを選んだ理由
- 第339回 復職が不安なあなたへ。“戻らない復職”を私が選んだ理由
- この連載の一覧へ