




2015年にBostanをサンプル出荷
Bostanコアの詳細が下の画像だ。ALU×2、MAU(MAC Unit)×1、LSU(Load Store Unit)×1、コプロセッサーの5命令の同時実行が可能な構成で、パイプラインは最大7ステージである。分岐は3サイクル程度で処理できる。
Bostanの場合、データパスは原則32bitで、64bitデータは32bitレジスター×2をペアにして格納する形になっている。ALUは当然整数演算なので、浮動小数点演算はMAUを使って処理する格好だ。このALUが一番パイプラインが長く、実行に4サイクルかかっている。とはいえスループットそのものは1なので、けっこうな処理速度ということになる。
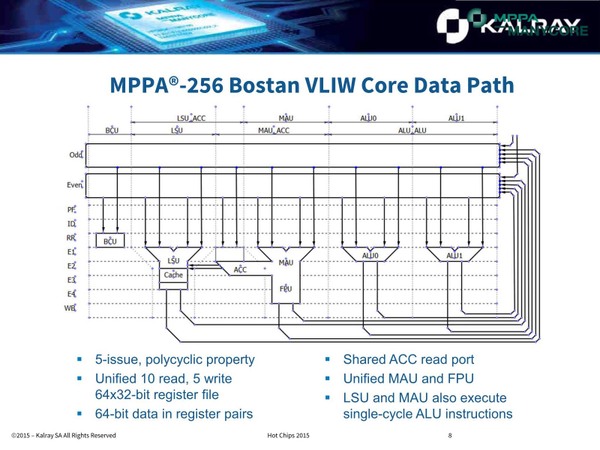
図がわかり難いのだが、例えばMAUの場合Odd BankとEven Bankからそれぞれ3本づつのパスが伸びている。Y=AXB+Cを計算する際に必要となるA・B・CがこのEven/Odd Bankから供給されるわけで、つまり1つのMAUでは同時に2つのMAC演算が可能になる仕組みだ。これはALUも同じで、要するに1サイクルあたり4つの32bit演算(あるいは2つの64bit演算)が可能である
結果として、600MHz駆動のコアであればMAC演算を1サイクルあたり2つということで2.4GFlopsという計算になる。ちなみにBostanではコプロセッサー命令は暗号化/復号化やCRCなどの命令に割り当てられている。
さて、KalrayではこのBostanを2014年にテープアウト、2015年にサンプル出荷を開始している。製造はTSMCの28nm HPで、600MHz動作で634GFlopsを25Wで実現する。ちなみに256コアだと634GFlopsではなく614GFlopsになるはずなので、634GFlopsというのは計算用ではなくマネジメント用の16コアのうち半分の8コアも計算にまわした264コア構成での数字のようだ。
1Wあたりの処理能力は25.36GFlopsになり、これは例えばインテルのXeon Phi(2147GFlops/300Wで7.16GFlops/W)やNVIDIAのTegra 4(75GFlops/8Wで9.38GFlops/W)などと比べてもおそろしく性能消費電力比が高い数字となっている。
実はこのBostanに先立ち、2013年にテープアウト、2014年に量産を開始したAndeyという第1世代のMPPAチップがあった。
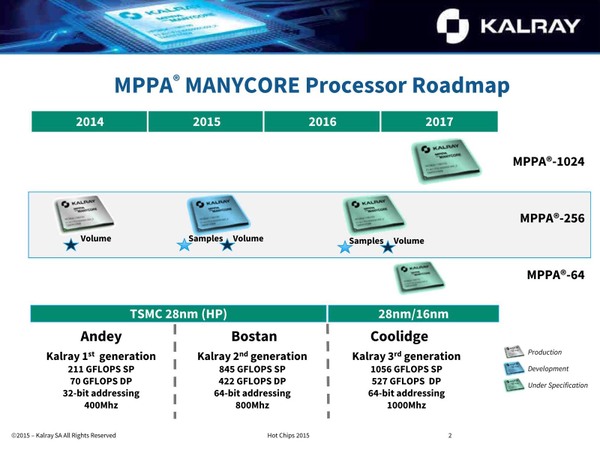
2015年当時の製品ロードマップ
こちらは32bitアドレスだし、コアの数は同じながら1サイクルあたりの処理性能はBostanの半分程度だったようだ。BostanはこのAndeyをベースに規模を倍増させ、動作周波数を引き上げたモデルということになる。これに続き、第3世代のCoolidgeの設計に入っている、というのが2015年における状況だった。
多くのサードパーティーがソフトウェアを提供
MPPAのもう1つの特徴がソフトウェアのサポートである。2015年の時点でNode OSという独自のOSとSMP Linux、サードパーティーのRTOSが提供されたほか、GNU C/C++とデバッガー/トレーサー、さらにOpenCLでのプログラミング用ライブラリーと、必要に応じてDSPスタイルのLow Level Programming Language(要するにアセンブラ+α)が提供されている。
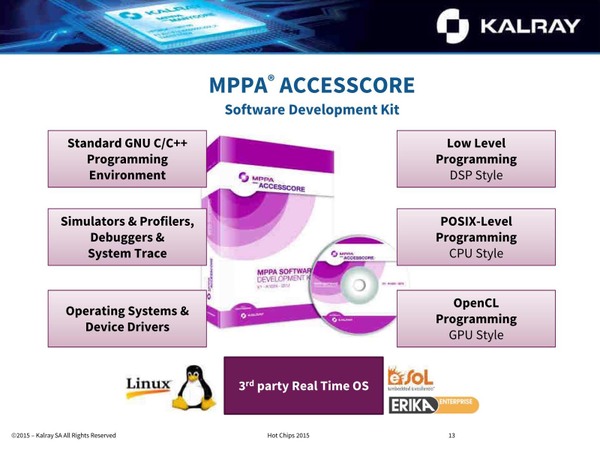
サードパーティーのRTOSとしては、日本のイーソルがeMCOSというOSを提供したほか、ERIKA Enterpriseという車載システム向けのRTOSが移植されている
ちなみにSMP Linuxは、下の画像で言えば、全体の四隅にある“Quad core”と書かれた制御用の4コアのどれか1つで動作し、I2CやSPI、GPIO制御用のドライバーなども提供される。残りの3つのQuad coreは、メインの計算用CPUクラスターの制御に利用される格好だ。
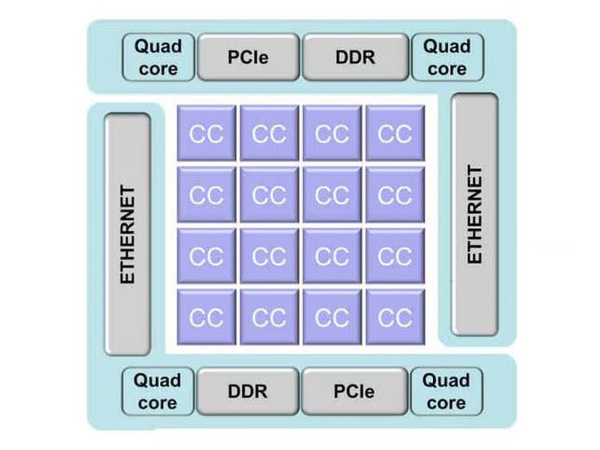
前掲のBostanの概要画像から、一番左側の図を抜き出したもの。SMP Linuxは、全体の四隅にある“Quad core”と書かれた制御用の4コアのどれか1つで動作する
そのメインの計算用CPUクラスター(というより各々のコア)上では独自のNode OSが動く格好だが、これはPOSIXのThreadをサポートし、GCCベースのOpenMPを利用してのコア間の同期なども取れる。なお、1コアあたり1スレッドでの動作となっている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ














ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")
















