ロードマップでわかる!当世プロセッサー事情 第653回
RDNA 3は最大10240SPでRadeon RX 6900 XTを遥かに超える性能 AMD GPUロードマップ
2022年02月07日 12時00分更新

RDNA 3は最大10240SPとなり
Radeon RX 6900 XTを遥かに超える性能を確保
シェーダー・アレイを2つまとめたのがシェーダー・エンジンとされる。2560SP構成だが、ラインナップとしてはこの2560SP構成が「当面は」最小構成になるものと思われる。下図の構成が、当面ディスクリートの最小構成になるであろう。

図1。最小構成のシェーダー・エンジン
将来的には、シェーダー・アレイが1つという可能性もあり得るが、単にWGP数を減らした2シェーダー・アレイになるのかもしれない。
この上位モデルが、シェーダー・エンジン×2である。ここまではモノリシックなダイでの構成だろう。ちなみにこの2シェーダー・エンジンの構成だと5120SPとなり、Navi 21の最大構成(Radeon RX 6900 XT)と等しいことになる。
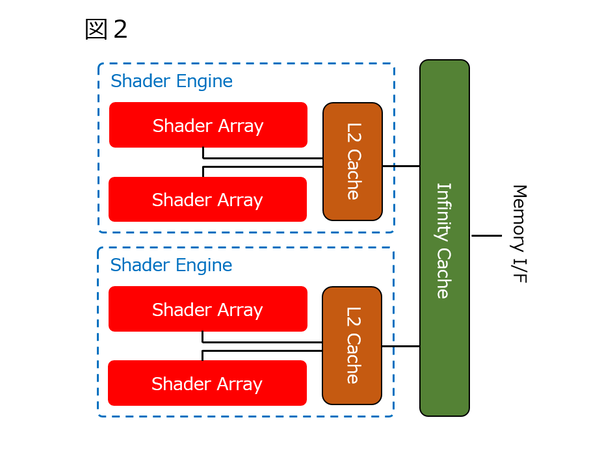
図2。シェーダー・エンジン×2の構成
この上位に位置すると思われるのが、3ダイ構成で4シェーダー・エンジン構成である。端的に言えば、上図の構成からインフィニティー・ファブリックを抜いて(抜かない、という可能性もあるのだがやや構造的に難がありすぎるので省いた)、それで1つのGPUダイを構成する格好になる。

図3。3ダイ構成で4シェーダー・エンジンの構成
この構成だと最大10240SPとなり、現在のRadeon RX 6900 XTを遥かに超える性能を確保できることになる。つまり、図1・2はモノリシックダイでの提供になり、図3はマルチダイ構成になると想定している。
| GPU | SP数 | |
|---|---|---|
| 図1 | Navi 33 | 2560SP |
| 図2 | Navi 32 | 5120SP |
| 図3 | Navi 31 | 1万240SP |
1万240SPというのは、NVIDIAのGA102の最大構成(84SM/10752 CUDAコア)にやや劣る程度の規模感になるが、ベンチマークの結果で言えばRadeon RX 6800 XT(4608 SM)とGeForce RTX 3080(8704 CUDAコア)が良い勝負ということを考えた場合、(動作周波数の違いを無視して言えば)1万240SP構成だとAmpereで言えば20000 CUDAコア弱の性能に相当する計算になる。普通に考えれば十分という気もする。
RDNA 3の製造プロセスは
TSMCのN5かN6
ちなみに別な情報もあり、図1に相当するコアは存在せず、図2がNavi 33、図3がNavi 32になり、Navi 31は図3に近い構成だがダイあたり3シェーダー・エンジン(7680SP)、トータル1万5360SPになるという話だ。個人的にはこの案はないだろうと思う。
理由は、利用するプロセスに依存する。RDNA 3世代に関してAMDは現時点で利用するプロセスを明確にしていない(“Advanced Node”という言い方をしており、5nmとは言っていない)。マルチチップ構成を取ることは確実で、その場合は3チップになるのも間違いではないと思うのだが、その製造プロセスが以下の2つがあり得る状況である。
GPU N5/Cache N6
GPU N6/Cache N7
仮にGPU N5/キャッシュ N6だとすれば、確かに3シェーダー・エンジンのダイを作るのは不可能ではない。連載605回でも触れたが5120SP構成のNavi 21のダイサイズは519.8mm2と発表されている。
内部の構造を変更してもそれで大きくダイサイズが変わるとは考えられない(SPの数がどうしても支配的だからだ)ことを考えると、仮に6nmに移行させたところでダイサイズはほぼ変わらないだろう。
N7とN6は、N6がEUV(極端紫外線)を利用するという違いはあるが、設計そのものには互換性があるからで、逆に言えばダイサイズは大きくは変わらない(TSMCの説明では18%の縮小)からだ。ということは、N6で5120SPのGPUダイを作ると、430mm2前後。これを7680SPにすると640mm2近くに達する。
巨大なダイを躊躇なく投入するNVIDIAと異なり、マルチチップ化によりダイサイズを減らす方向に舵を切っているAMDとしては、これは許容範囲から外れるだろう。ただこれがN5で製造できるとなると、TSMCの発表ではロジック密度が83%向上するとしていたから、430mm2近くまでダイサイズを縮小できることになる。
ただしN5の製造コストはN7の1.5倍近くまで跳ね上がるという話であり、ダイのコストそのものはあまり下がらない(むしろ上がってる)ことや、ダイあたり7680SPをフルに動かすためにはインフィニティー・キャッシュを相当積まないと、メモリーがボトルネックになりそうというあたりを考えると、やや無理があるのではないかと思う。
図1がNavi 33、図2がNavi 32、図3がNavi 31という構成の場合、2シェーダー・エンジンのダイサイズはTSMC N6の場合430mm2程度、N5に移行できれば300mm2を切る程度に収まる。N6だとしてもハイエンド向けに許容できる(なにしろすでにもっと大きなダイサイズのNavi 21を量産している)値だし、N5ならかなり競争力がありそうだ。
このあたりがはっきりしないのは、すでにTSMCのN5が激しい取り合いになっていることに起因しており、AMDとしても可能ならN5を使いたかったのだろうが、十分にキャパシティーが確保できないとすれば、N5はRyzenを優先にして、Radeonは当面N6という選択肢は十分あり得る。Radeon Instinct MI200がTSMC N6を利用したあたりもこの案の補強材料になるはずだ。
ところでマルチダイ方式を使う場合の難点がレンダー・バックエンドだという話は連載515回でも説明した通りだ。要するにDeferred Rendering(遅延レンダリング)を多用する場合、煩雑にシェーダーとメモリーの間でやり取りが発生するため、メモリーバスがボトルネックになる。
この対策としてRDNAではレンダー・バックエンドと2次キャッシュの間に1次キャッシュを挟んだ格好になっている。加えてRDNA 2では2次キャッシュとメモリーの間に大容量のインフィニティー・キャッシュを挟んだことでさらに効率が上がった格好だ。
今回伝え聞いている構造では、このインフィニティー・キャッシュが2つのダイで共有される格好になっている。おそらくGPUダイとキャッシュダイの間の接続は、Radeon Instinct MI200で採用されたElevated Fanout Bridge 2.5Dを使った格好であり、加えて言えばRadeon Instinct MI200のようにインフィニティー・ファブリックに一度変換して通信するのではなく、どちらかといえばRyzen 7 5800X3Dの3D V-Cacheに近い、直接キャッシュアクセスの信号線がそのまま引っ張り出されるものに近いと思われる。
このキャッシュダイへのアクセスのレイテンシーがオンダイのレイテンシーとそれほど変わらずに実現できれば、マルチダイであってもレンダー・バックエンドはオンダイのインフィニティー・ファブリックにアクセスするのとさして変わらない性能で処理が可能になる。
スケーラビリティーを考えればインフィニティー・ファブリック経由にする方が効果的だろうが、帯域が減ってレイテンシーが増えることを考えれば、ここはスケーラビリティーは無視していると考えるのが妥当だろう。
こちらも正確な出荷時期は不明であるが、今年中の出荷は間違いないとしている。2020年にRadeon RX 6800/6900シリーズが11月頃に投入されたことを考えると、現実問題としては今年第4四半期あたりではないかと予想する。COMPUTEXの頃までにはそのあたり、もう少し情報が出てきそうである。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ













