
キャッシュと帯域を増やすことで
処理の高速化を実現
次がキャッシュシステムである。新たに1次キャッシュが追加されたほか、帯域の強化やレイテンシーの削除などが主な改良点である。

正確に言えば「従来の1次キャッシュが0次キャッシュとなり、2次キャッシュとの間に新たな1次キャッシュが追加された」ということになる。GCNから見れば1.5次キャッシュが追加された、と言う方が正確かもしれない
まずキャッシュの説明の前にWGP(Work Group Processor)について定義しておく。先ほどのCUの構成であるが、RDNAでは2つのCUで共有される形でシェーダーの命令キャッシュやScalar Data Cache/Local Data Shareなどが用意される。このCU×2+共有キャッシュの塊がWGPと定義される。

ここでData Cache/Instruction Cacheの容量そのものはGCNと同じである。つまり、これに関して言えばGCN世代からむしろ半減したという見方もできる
これを念頭に、1次キャッシュの構成を示したのが下の画像である。1次キャッシュには5つのWGP(=10CU)と、RB(Render Backend)が直接接続されることになっている。

1次キャッシュの構成。この図ではRBと1次キャッシュの間の帯域が明示されていないが、当然256Bytes/サイクルより高速と思われる
実は1次キャッシュの目的は、このRBをフルに生かすための工夫ともいえる。レンダーバックエンドは描画処理の最終段階の作業を担うもので、複数のスレッドをブン回して得られた最終的な描画データを、フレームバッファにピクセル単位で出力する作業を担うことになる。
普通であれば、RBはそのまま2次キャッシュ経由でメモリーに書き出すのが効率が良いわけだが、あえてここに1次キャッシュを挟んだ理由は、Deferred Rendering(遅延レンダリング)の技法が多用されるようになってきたことに起因する。
たとえばLightingを例に取れば、従来型のレンダリング(Forward Rendering)ではオブジェクトに対してLightingの計算を行ない、その結果をラスタライズして出力を得るのに対し、Deferred Renderingでは先にラスタライズを済ませてしまい、その後でラスタライズしたデータに対して必要な箇所だけLightingを施す、という手順になる。
この方式はシェーダーの負荷が軽くなるというメリットがある半面、いったんメモリーに書き出したデータを読み出して処理し、改めて書き戻すことになるので、メモリー帯域に大きな負荷がかかる。
GCNの場合はいったんラスタライズされたデータが2次キャッシュに格納され、RBは2次キャッシュから読み出して処理し、2次キャッシュに書き戻しをし……、という形で煩雑に2次キャッシュアクセスが発生していたが、メモリーより高速とは言え2次キャッシュもそれほど高速ではない。
そこでRDNAではWGP/RBと2次キャッシュの間に1次キャッシュを挟み、RBは1次キャッシュとの間で読み出し/書き戻しを行わせることで処理の高速化を実現した形になる。
それだけでなく、1次キャッシュは0次キャッシュとも広帯域で接続することで、LDS(Local Data Share)の帯域を従来比2倍に増やしたとしており、RB関連以外の処理の高速化にも貢献している。
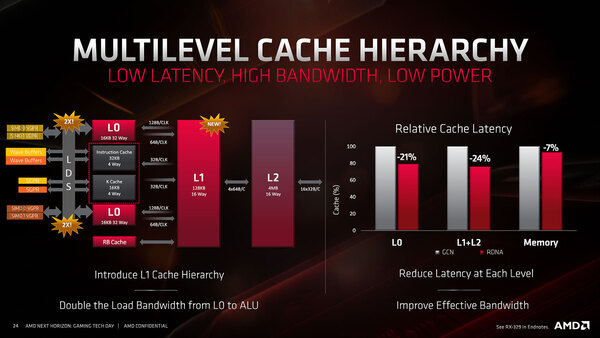
1次キャッシュはRB関連以外の処理の高速化にも貢献する。帯域増加だけでなくレイテンシーの短縮も同時に実現しているとする
また、RB⇔1次キャッシュ⇔2次キャッシュ⇔メモリーのデータ転送に関してはデータ圧縮をかけており、これにより効率的に帯域を利用できるとする。

データ圧縮技法そのものは以前から搭載されているし、Radeonが唯一というわけでもない。ごく一般的としても良い。ただ従来よりも適用範囲を広げるとともに、効率を改善したとする
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ












