ロードマップでわかる!当世プロセッサー事情 第653回
RDNA 3は最大10240SPでRadeon RX 6900 XTを遥かに超える性能 AMD GPUロードマップ
2022年02月07日 12時00分更新

RDNA 3では2つのCUを1つにまとめ
CUの規模が4倍に増加
RDNAはCUを2つ束ねたものを、WGP(Workgroup Processor)として扱っている。このWGP、RDNA/RDNA 2の時点では、ハードウェア的には1つの管理単位であったが、ソフトウェアから見れば2つのCUとして見える形で、少なくとも明示的にWGPレベルでなにか管理、という話ではなかったはずだ。
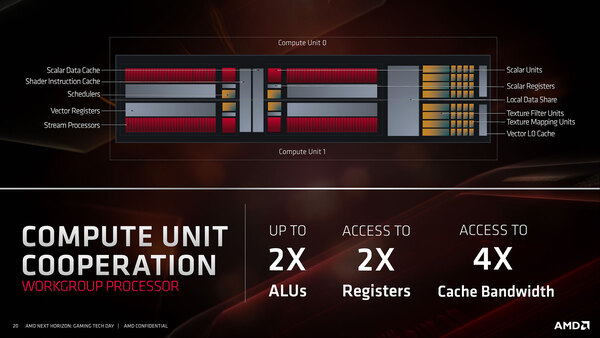
RDNAはCUを2つ束ねたものをWGPとして扱っている。当初からWGPで管理すればよかったのに、と思わなくもない
WGPには共有のローカルデータシェアやスケジューラー・データキャッシュ/スケジューラー・インストラクションキャッシュが配されていたが、5つのWGPで共有される形で128KB L1が配され、さらにその外側の外側にすべてのWGPで共有される形で4MB(256KB×16)のL2が配される形になっている。
このL2の容量はSKU(CU/WGPの数)によって変化する。RDNA 2では、このL2のさらに右側、インフィニティー・ファブリックにインフィニティー・キャッシュがL3として追加実装されているが、ここまでの基本構造は同じと考えていいだろう。

L1の総容量は当然WGPの数で変化するし、L2/L3もこれに合わせて変化すると思われる
ということで、ここでCUが廃されるというのはどういうことかと言えば、スケジューラーやベクトルキャッシュが、2つのCUで共通になるように構成された形で、しかもSP数が倍増するという構成になったと考えられる。

これはRDNAの図を基にした、RDNA 3のWGPの想像図。実際にはベクトル・レジスターの容量も倍増していそうだし、そもそもテクスチャーフィルター/マッピングユニットの数が1WGPあたり8/32個かどうかも疑問が残るところではあるが、想像図なので勘弁してほしい
要するにCUの規模が4倍になった形で、Wave 32を1サイクルあたり8つハンドリングできることになる。これをCUとして表現しなかったのは単に過去のCUとごっちゃになるのを避けたかったためだろうし、なぜ2CUを1つにまとめたかと言えば、おそらく規模を大きくするにあたり、より大きな単位で管理するようにすることでオーバーヘッドを減らしたかったのだろう。
ひょっとすると、Wave32に代わりWave64が管理単位として復活するかもしれないが、それなら32-Wide SIMD×8よりも64-Wide SIMD×4の方が合理的な気がするので、Wave32はそのまま継承されるだろう。
この、SP数が倍増したWGPが5つと、RB(Render Backend)がまとめて1つのL1を共有する、という構造そのものはRDNA 3でも変わらないようだが、RDNA 3ではこのWGP×5+RB+L1をまとめてシェーダー・アレイと呼び、これが最小単位になるらしい。つまり1280SP構成だ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ












