



ロードマップでわかる!当世プロセッサー事情 第629回
Intel Architecture Day 2021で発表された11のテーマ インテル CPUロードマップ
2021年08月23日 12時00分更新

Xe HPC&Ponte Vecchio
まずPonte Vecchioの設計目標が下の画像だ。FP64性能、AI性能、メモリー帯域のいずれも、これまでインテルが提供してきた性能(青線)は、業界標準(緑線)に追いついてこなかったが、ここで一気に追いつきたいわけだ。
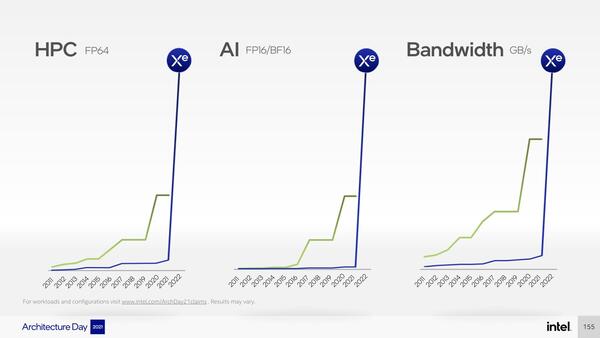
Ponte Vecchioの設計目標。インテルが業界標準に追いつかなかったのはKnights Landingをキャンセルしたからでは? という突っ込みを入れたくなる
さて、これを実現するためのコアであるが、Vector Engine/Matrix Engine共に、Coreあたりの数は8つに減っている。ただし、Vector Engineは512bit、Matrix Engineは4096bitと2倍/4倍に増えている。Xe HPGに比べて、より演算性能を引き上げた格好だ。

エンジンの数を8つに減らしたのは粒度を上げるためだろうか?

Matrix EngineはXe HPG同様、主にAI処理向けと考えられる
この結果、Coreあたりのベクトル演算性能はFP32/64で256 Ops/サイクル、Matrix演算性能はInt 8だと最大8192 Ops/サイクル、FP16/BF16でも4096 Ops/サイクルである。このXe Coreを16個まとめたものをスライスと呼び、さらにスライスを4つ(つまりXe Coreを64個)集積したものがスタックである。

ちなみに、なぜかレイトレーシングユニットまでXe Coreごとに搭載されている理由が良くわからない。汎用サーバー向けのXe HPはまだわかるのだが、HPC向けにレイトレーシングは本当に必要なのだろうか?
Ponte Vecchioは、このスタックを2つ搭載した格好になる。それぞれのスタックには最大8本までリンクが出るXe Linkという、要するにルーターが搭載されており、これで最大8つまでのスタックが密結合で動作する格好になる。

Ponte Vecchioは、スタックを2つ搭載する。物理的にこの2つのスタックは別々のダイ(スライスごとに別ダイ)であり、間はXe Linkで接続される格好になる
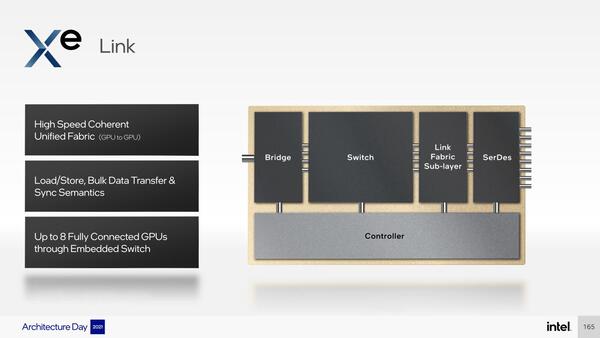
それぞれのスタックにXe Linkを搭載する。この構造そのものは珍しくないし、8本のリンクも他に例がないわけではない。現時点ではリンクの速度や帯域、レイテンシーなどは不明だ

8つのスライスの相互接続ならリンクはスライスあたり7本で十分であり、残る1本の用途が不明である。将来の拡張用だろうか?
さて、Ponte Vecchioの物理実装が下の画像だ。連載627回の最後の写真でも触れたが、合計47タイルからなる。

Ponte Vecchioの物理実装。Compute TileとRambo Cache、Base TileはFoverosで接続され、HBM2やXe LinkはBase TileとEMIBでつながる格好になる
内訳は以下の通り。
- Compute Tile×16
- Rambo Cache×8
- Xe Base Tile×2
- EMIB×11
- Xe Link×2
- HBM2e×8
1スタックあたりに換算すると以下の通り。
- Compute Tile×8
- Rambo Cache×4
- Xe Base Tile×1
- EMIB×5(おそらくHBM2e用×4+Xe Link用×1)
- Xe Link×1
- HBM2e×4
これとは別にスタック同士の接続にEMIB×1が使われる。このPonte Vecchioは1つ(=2スタック)でFP32が45TFlopsとされる。2 Stack=8 Slice=128 Xe Coreだから、処理性能は32768 FP32 Ops/サイクルになる。トータル45TFlops以上、ということは動作周波数はおおよそ1.4GHz程度と推定されることになる。競合製品との違いは、FP32/FP64が同じ性能なことだ。

1.4GHz駆動では実際の処理性能は45.87TFlopsほどになる。ちなみにNVIDIA A100がFP64 9.7TFlops/FP32 19.5TFlopsだから、FP32比で2.4倍弱、FP64だと4.7倍ほど高速という計算になる
ちなみにこれは2スタックでの構成だが、実際のCompute Bladeはこれを4つ組み合わせ、3つ前の画像の構成を取った物が基本ということになる。実際にAuroraに納入予定のモジュールも示された。

Xe LinkはあくまでこのSubsystem上のOAM同士の接続に使われる

Auroraに納入予定のモジュールは、Ponte Vecchio x4 Subsystem+2S Sapphire Rapidsの構成そのままだが、水冷配管がなされている
ということで、これでも随分省いて説明したにも関わらずこの文量である。もう少し深い話を次回以降、順次お届けしたい。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























