




プロセスを微細化するより
ダイを大きくしたほうが経済的
なぜWafer Scaleなのか? 同社のブログによれば、要するに「AIはより高い処理性能を求めるようになりつつある。そのためには、よりたくさんのトランジスタが必要になる。通常このためにはプロセス微細化が必要になるが、プロセス微細化は生産コストを除外してもNRE(開発費)が高騰化しており、そろそろ経済的に引き合わなくなっている。
ならば、プロセスは手頃なところに抑えておいて、ダイサイズを大きくした方がトータルコストを考えれば安くなる」という、これはこれでわからなくはない理屈である。
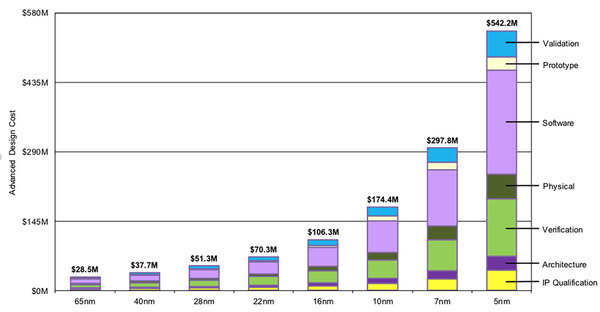
元データはExtreme Techの記事である。16nmでは設計/検証コストは合計1億ドル程度。これが7nmだと3億ドル、5nmでは5.5億ドルになるとしている
チップコストは当然跳ね上がる(ウェハーまるまる1枚なので、1枚100万円前後だろうか)が、大量生産するチップはともかく少量となると、そこに載せる開発費の償却分の方が高くつくわけで、同じ性能を実現するなら多少面積を削るよりもダイサイズを広げた方が最終的な製品価格が安くなる、という理屈には一定の説得力がある。
この議論は後でまた取り上げるとして、内部アーキテクチャーはというのがこちら。実はWSEも、内部はデータフロー・プロセッサーである。理由は後で出てくるのでそちらで説明するとして、内部の演算そのものは一般的なMAC演算を中心にしたものであるが、データ制御用命令も処理できるとしている。
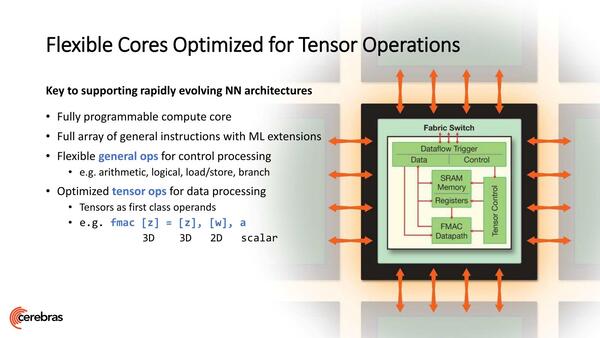
ちなみに同社はこのコアのことをSLAC(Sparse Linear Algebra Compute:疎な線形代数計算)コアと呼んでいる。WSEの最初のアプリケーションはAI向けだが、AI専門というわけではなく、科学技術計算にも利用できるような色気を見せているわけだ。ただ、それに必要なデータ型(FP32/64)をサポートしているかどうかは現状明らかにされていない。
ここからはデータフローの話だ。NVIDIAのAmpereについて語った連載563回でSparsityの話に触れたが、昨今のAIでは、ネットワークをいかに絞り込んで簡単にするかが1つのテーマになっている。
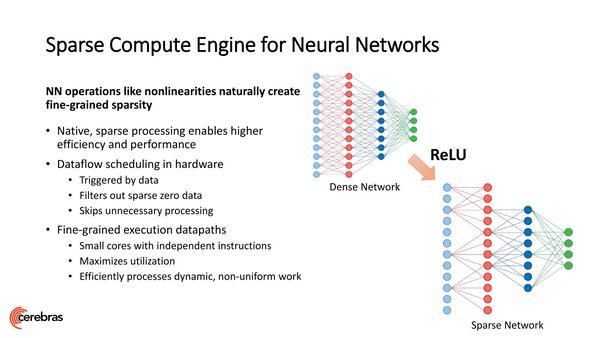
厳密に言えばAmpereの話は行列が疎の場合で、こちらはネットワークそのものが疎な場合の話であるが、使わない要素は計算しないという意味では同じことである
最初にモデルを構築するときは密なネットワークになっていても、そこから最適化して疎なネットワークにすることで、速度の向上やメモリー利用量の削減を図るわけだ。この結果、AIプロセッサーはこの疎なネットワークをうまく扱うことが求められる。
これは別にWSEに限らず一般的な話である。そしてデータフローの場合、この疎の場合の処理が非常に簡単である。疎、つまりデータが入ってこない、あるいはデータが出ていかない場合、その処理は個々のコアがそもそも動かないからだ。これは連載第568回で説明したWave ComputingのDFPと同じ発想である。
コアの周囲をSRAMで囲み広帯域を確保
次の問題はメモリーである。外部メモリーは、たとえそれがHBM2であっても遅い。そこで、WSEではコアの周囲をSRAMで囲むという荒業でこれを解決した。要するに全部SRAMである。

外部メモリーがHBM2であっても遅いというのは一般論の話である。ちなみにWSEのSLACコアは、そもそもキャッシュを持たない
もっともSLACコアは全部で40万個なので、コアあたりで言えば48KBほどになるわけだが、コア40万などになればひとつのコアは1つのウエイトだけ記憶して、後はデータを受け取って送り出すだけなので、これで十分ということだろう。
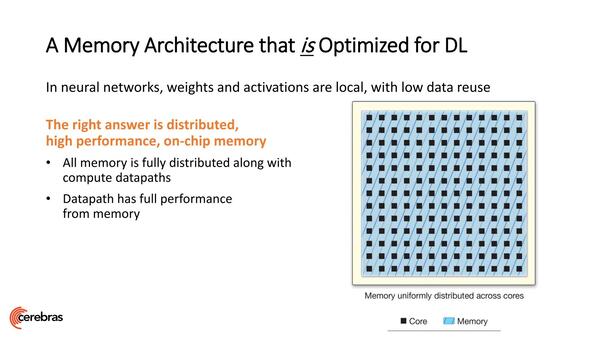
全体で18GBものSRAMを実装しており、自分の周囲のメモリーには1サイクルでアクセス可能だ。帯域が9PB/秒になるのも当然である
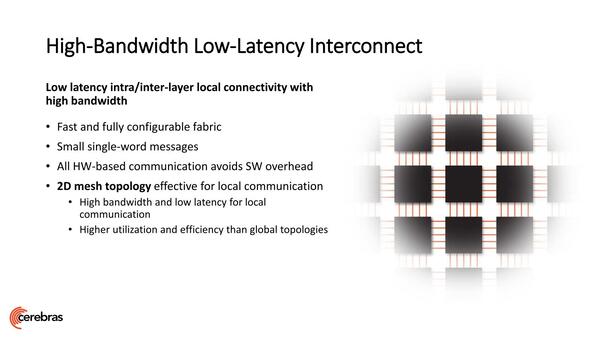
ルーティングはすべてハードウェアベースというのはよくある話である。ちなみに線が5本なのは単にイラストの問題であって、5対の信号線だけでつばがっているわけではない
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ












の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



















