




ダイ同士をワイヤーでつなぎ
独自のコネクターでパッケージング
ところでこのコア同士をどうつなぐか、であるがこれは2Dメッシュである。ただ、WSLは84個(12×7)のダイに分かれている。これはマスクがこの1個分として作られているので、同じマスクを84回移動しながら露光して製造するわけだが、通常はこれを切り落とすことになる。
したがって2Dメッシュも個々のダイの中は問題なく接続できるが、ダイの間は通常切り落とされることになるため、ここに配線を通せない。そこで後工程でダイの間にワイヤーを通すという荒業で対策している。
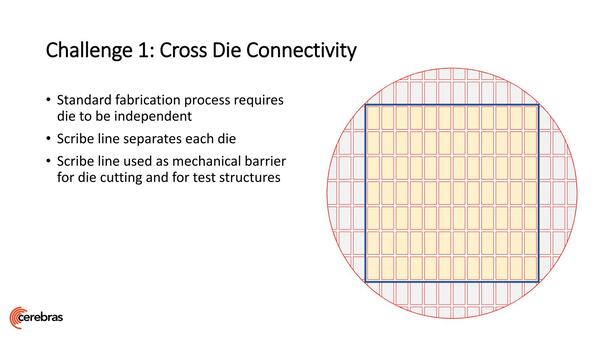
ダイとダイの間は切り落とす。この切り落としの領域(要するに切り代)のことをScribe lineと呼ぶ。ここは露光のはざまになるので、トランジスタも配線も実装できない
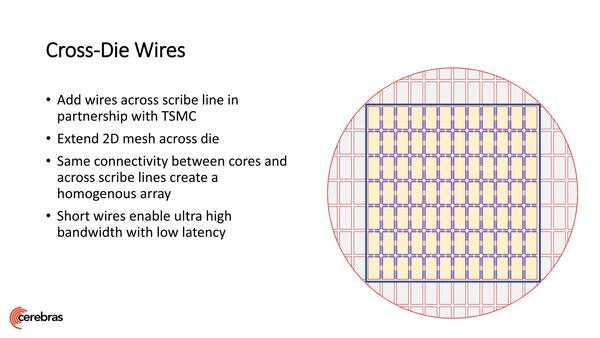
ダイの間にワイヤーを通すことでコア同士をつないでいる。ここをどうやって作ったかに関して今のところ詳細な説明はない(そのうちどこかでTSMCが発表しそうな気もするが)
また当然Defect(欠陥)も問題になる。これに関しては、冗長コアと冗長配線を用意、欠陥箇所を迂回する形で利用できるとした。

TSMCの16FF+はかなり熟成されたプロセスなので、欠陥はそう多くはないとは思うが、だからといって欠陥0にはならない
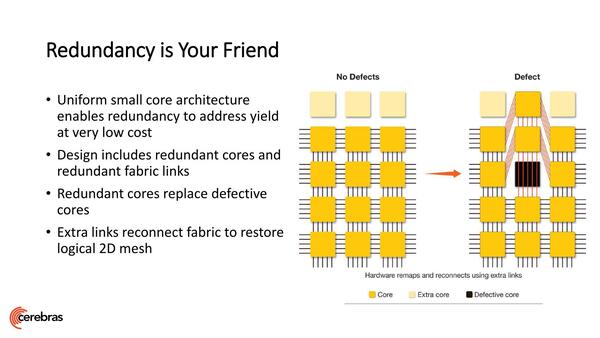
上一列が冗長コアである。同様にコア間のリンクに関しても冗長リンクが用意されるとしている
パッケージも独特である。まずFlip Chipの形でプリント基板に装着するわけだが、その際に中間的な熱膨張率を持ち、両者の差を吸収できる独自のコネクターを開発したそうだ。

Flip Chipの形でプリント基板に装着する。そもそもシリコンとプリント基板では熱膨張率が違う上、これだけダイが大きいと相当寸法に狂いが出そうである
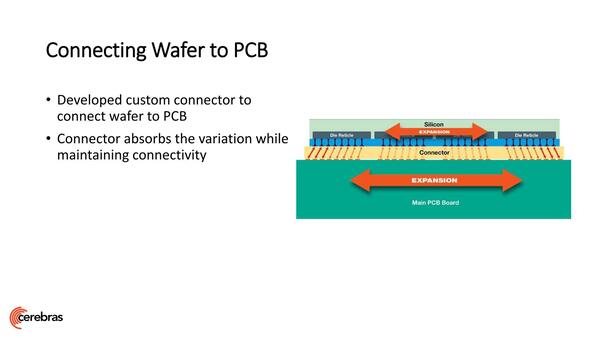
独自のコネクター。もう少しダイサイズが小さければCoWoS(高密度パッケージ技術)などでも良かったのだろうが、これだけ大きいとCoWoSをそのまま使うわけには行かないだろう
ちなみにソフトウェア的には当然既存のフレームワークを変換して利用する形になる。これだけコアがあると小規模なネットワークであればまるごと全部をオンダイ(オンウェハーというべきか)に載せることも可能とされる。
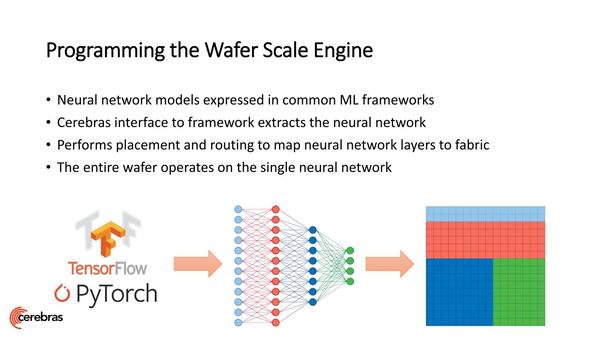
ソフトウェアは既存のフレームワークを変換して利用する。逆にここに載せきれない場合は、ウエイトを入れ替えながら動かすような形になるので、若干効率は落ちるはずだ。今のところ、どんなネットワークならまるごと載るかといった情報は出てきていない
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ


















&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")











ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












