




10倍どころか100倍近い
性能/消費電力比を実現
さてこのGoogle TPUの性能だが、論文によれば下表の通りである。18コアのtXeon E5-2699 v3の2ソケット構成単体と、そのサーバーに、Tesla K80を1枚追加したもの、およびDual Xeon E5-2699 v3にGoogle TPUを組み合わせたものの3種類での性能比較であるが、INT 8における演算性能はXeonが合計で2.6TOP/秒なのに対しGoogle TPUは92TOP/秒を叩き出している。
Measured、つまり実測の消費電力で比較すると以下のとおりだ。
| 消費電力の比較表 | ||||||
|---|---|---|---|---|---|---|
| プロセッサー | ダイ単体 | システム全体 | ||||
| Xeon(INT 8) | 17.931GOP/s/W | 5.714GOP/s/W | ||||
| Xeon(FP) | 8.965GOP/s/W | 2.857GOP/s/W | ||||
| Google TPU | 28.571GOP/s/W | 2.825GOP/s/W | ||||
| Tesla K80 | 2300GOP/s/W | 239.583GOP/s/W | ||||
基調講演における10倍どころか、100倍近い性能/消費電力比を実現できているわけだ。こうなると基調講演で語った10倍の差はいったいなにと比較したのか? という議論になるわけだが、これは後述する。
ちなみにこの論文では、ベンチマークとしてMLP(多層パーセプトロン)、LSTM(Long Short-Term Memory:長期間の時系列データを扱えるネットワーク)、CNNの3種類について、それぞれ2つづつトータル6つのネットワークを利用している。
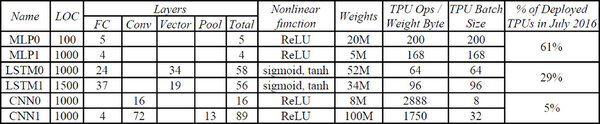
ネットワークの層数は4層~89層、活性化関数もさまざまで、Weight(係数)の量も5万~100万個と大きく異なる
この6種類のネットワークの傾向をまとめたのが下の画像である。TPUは1万ps/Bytesあたりまでほぼ性能が上昇して86TOP/秒あたりでやっと頭打ちになるのに対し、Haswellは13Ops/Bytesあたり、K80は8Ops/Bytesあたりですでに性能が頭打ちになっており、これ以上性能が上がらないことが示されている。
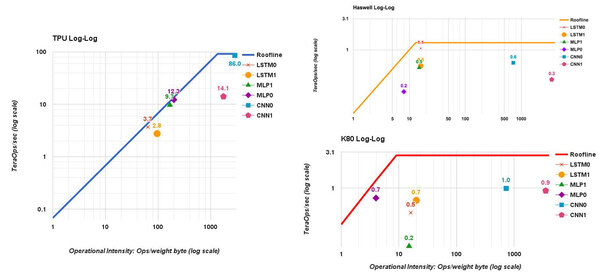
ネットワークの傾向。本来は3つの異なるグラフであるが、一つにまとめさせていただいた
水平部は演算性能のリミット、斜線部はメモリー帯域のリミットであり、要するにHaswellやK80は演算性能の前にメモリー帯域がリミットになってしまっている。
上で書いた性能の話だが、実効性能に近い数字が2007年8月に開催されたHotChips 29で公開された。こちらはK80およびGoogle TPUのCPUに対する性能比をそれぞれ算出したもので、相乗平均の結果が右端となる。
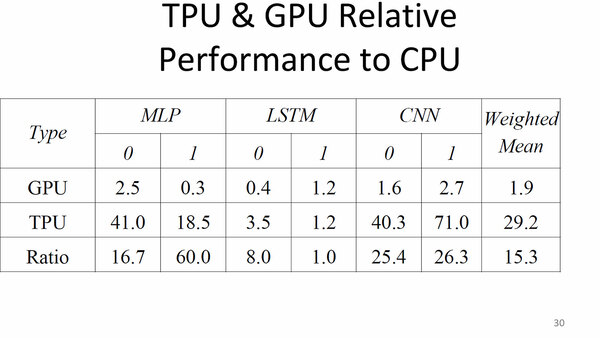
HotChips 29で公開された、実効性能に近い数字。これは6種類のネットワークのそれぞれの処理性能を、CPU(Xeon)で行なった場合と比較しての数値となる
出典は“Evaluation of the Tensor Processing Unit: A Deep Neural Network Accelerator for the Datacenter”
Xeon 2Pと比較して29.2倍ほど、K80と比較して15.3倍ほどの性能となっている。絶対値という意味では、おおむね23TOP/秒あたりが平均的な性能ということになる。
第2世代となるGoogle TPU v2が登場
カード間で2次元Meshの構築が可能に
初代Google TPUの詳細が発表される「前」の2017年5月に開催されたGoogle I/Oで、第2世代となるGoogle TPU v2(Cloud TPU)が発表される。

Google TPU v2。1年前と異なり、2017年は基調講演の比較的早い段階で公開された
大きな違いは、今度は4つのGPUで1枚のカードを構成するだけでなく、カード間で2次元Meshを構築できることで、大規模なデータセンター(学習用クラウド)をTPUだけで実現できることになる。
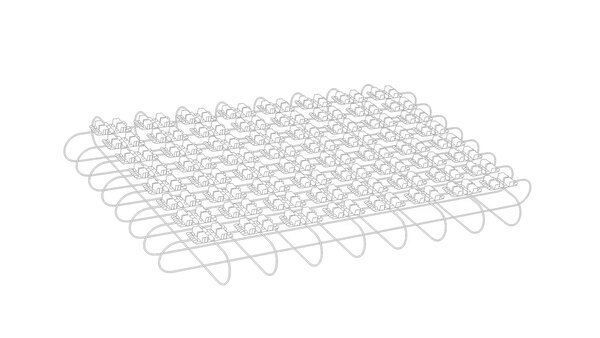
それぞれのTPUボードに4本のインターコネクトが搭載されており、これで2D Meshを構築できる。構成は8×8。リンク速度は1本あたり双方向で500Gbpsだそうだ

実際に稼働中のCloud TPUのシステム。一般のデータセンターと比較して5倍の帯域を10分の1のコストで実現できたと説明されている。おそらく中央の2つのラックがGoogle TPU v2のPod、左右のラックは制御用のホストと思われる
このGoogle TPU v2の構成であるが、2019年のHotChipsでGoogle TPU v3と併せて解説されたほか、David Patterson教授による“Domain Specific Architectures for Deep Neural Networks: Three Generations of Tensor Processing Units (TPUs)”という講義の中で詳細が説明されており、しかもそれがYouTubeで公開されている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















