




初代Google TPUの2倍の性能を誇る第2世代
以下、この2つのソースをもとに解説する。まずGoogle TPU v2の基本構成が下の画像だ。1つのチップに2つのダイが搭載され、おのおののダイに8GBのHBMが装着される構成になっている。
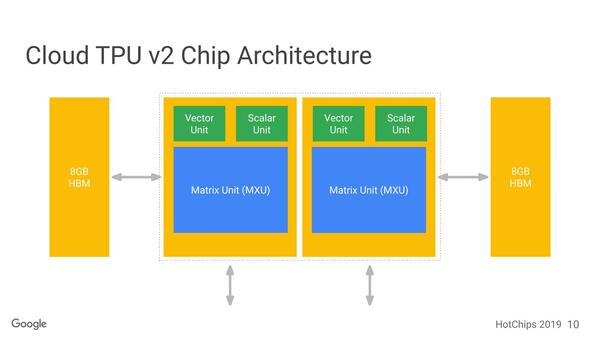
初代Google TPUの反省は外部メモリーの帯域が低すぎたことだそうで、それもあってHBMを使って大幅に高速化された
それぞれのコアの詳細は下の画像だ。MAC Unitは128×128と1/4のサイズになったが、その代わり一度に全ユニットの計算が可能になっている。
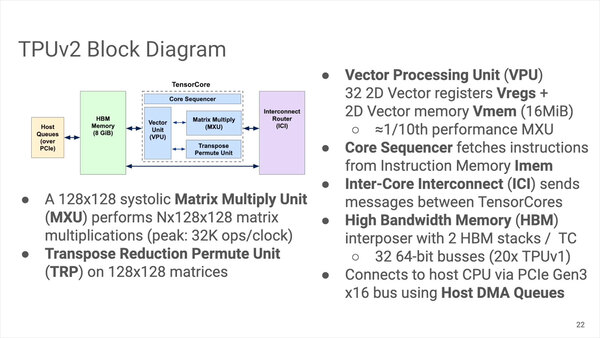
ダイあたりで言えば、PCIe Gen3 x32でホストと接続される構造となる。VPUはMXUの10分の1程度の性能とされる
また16MBのVmemも搭載されている。加えて言えば、データ型も初代のINT 8からTPU v2ではBfloat16/FP32に切り替わった。推論だけならINT 8のままでいいのだろうが、学習に向けてはやはりもう少し精度というか桁数が欲しい、というニーズに応えたものである。
ダイのフロアプランは下の画像がわかりやすい。MXUよりもVPU+Vmemの方がはるかに大きなエリアを占めているのがわかる。
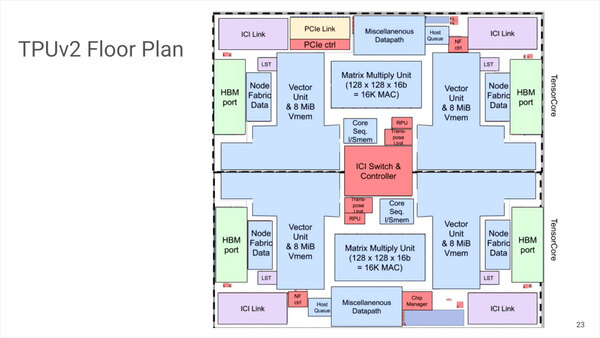
PCIe Linkそのものはダイに1ヵ所か所で、このあたりだけ対称性が崩れている。製造プロセスやダイサイズなどは未公表だが、プロセスは時期的なものから考えるとTSMCの20nmではないかとみられている。動作速度は700MHz
またこのGoogle TPU v2の設計の最中に、Bach normalizationという論文が発表されている。この仕組みを、Google TPU v2ではハードウェアとソフトウェアでサポートすることで、学習速度を最大14倍にできたとしている。

具体的にはベクトルユニットのスループットを初期デザインの8倍にしたほか、逆平方根の計算を行なうハードウェアを追加したとしている
ちなみにCloud TPU v2が64台のPodで11.5TFlopsとされているので、1台(つまり4チップ)あたり180TFlops、ダイ1個あたり45TFlopsという計算になる。

こちらはHot Chipsの論文より
Google TPU v2では先にも書いたがBfloat16/FP32で計算しているので、処理速度はチップ1つあたり45TOP/秒という計算になり、これはおおむね初代Google TPUの2倍の性能に相当する。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ











&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")




















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












