




CNN(畳み込みニューラルネットワーク)が実用になる、という話で2013年あたりから活発に業界がそちらに向けて動き始めたという話は過去3回でしてきたが、これに向けた専用プロセッサーの先鞭をつけたのはGoogleだった。
性能/消費電力比が競合と比べて10倍優秀
GoogleのAI向けプロセッサー「Google TPU」
2016年5月に開催されたGoogle I/Oの基調講演で、GoogleはGoogle TPUを発表。絶対性能はともかくとして、性能/消費電力比が競合と比べて10倍優れていると説明した。

AI向けプロセッサーのGoogle TPU。サーバーのSATAディスクエリアに収まる程度の小ささである。下のコネクターはPCIe Gen3 x16だが、独自のものとなっている
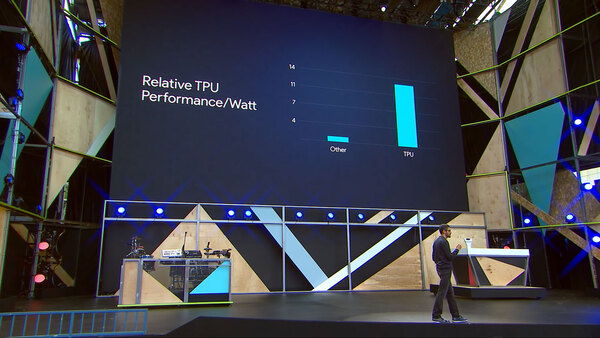
基調講演の最後でGoogle TPUの効率を示すSundar Pichai CEO
競合はおそらくNVIDIAのGPUだが、2016年5月はまだPascalが前月にリリースされたばかりなので、世代的にはMaxwellが競合となる。ただデータセンター向けのTeslaでは28nmプロセスのKeplerベースが最新であり、これとの比較とこの時点では思われた。
Google TPUもやはり同じ28nmプロセスで製造されており、アーキテクチャーを工夫することで10倍の効率を実現したというわけだ。
基調講演では、Google TPUがすでに稼働中であり、Google検索の要であるPageRankを評価するRankBrainやGoogle Street View、さらにはAlphaGoなどにも使われていることが明らかにされた。
そのGoogle TPUであるが、2017年6月に開催されたISCA(International Symposium on Computer Architecture)において“In-Datacenter Performance Analysis of a Tensor Processing Unit”という論文で詳細が明らかにされた。
下の画像がその全体像である。計算部となるのは、256×256で65536個並んだMAC演算ユニットと、そのMAC演算の後処理で加算を行なうアキュムレーターである。もっともこれ、65536個のMACユニットが同時に演算できるわけではなく、言ってみれば256サイクルかけて出力されるようなイメージである(実際はもう少し早い)。
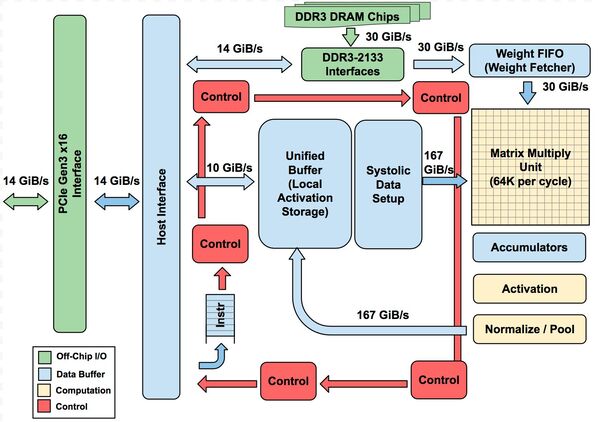
Host InterfaceとUnified Bufferの間は10GiB/秒程度とちょっと低めなのがやや不思議である
つまり256組の256 MAC演算ユニットがあるかたちだ。1サイクルあたりに出力される結果は1組分であり、パイプライン動作をしている格好だ。ただそれでも毎サイクルあたり256Bytesのデータ処理が行なわれるわけで、それに見合ったデータ転送性能が必要である。
例えば連載562回で例として掲載した図を例にとると、もともとの画像データはSystolic Data Setupと呼ばれるユニットから、フィルターのデータはWight FIFO(Weight Fetcher)と呼ばれるユニットから供給され、乗算→加算→活性化→プーリングを経てUnified Bufferに戻される。
このSystolic Data Setupと64KのMatrix Multiply Unit、およびNormalized/PoolとUnified Bufferの間は、256Bytes(=2048bit)幅のバスでつながっている。
要するに1サイクルあたり256Bytesの元データ読み込みが可能で、一方演算結果も同じく256Bytes/サイクルでUnified Bufferに書き戻せる構造になっている。ちなみにそのMAC Unitの下にあるアキュムレーターは、1サイクルで256個の演算結果の合計を計算可能になっている。
このTPUがどれだけスムーズに動作するかは、どれだけ切れ目なくデータをMACユニットに送り出し、かつ結果を受け取れるかにある。このため、Unified Bufferは24MB、アキュムレーターは4MBの容量を持っている。
チップ内部のレイアウトは下の画像の通りで、バッファがかなり大きな容積を喰っているのがわかる。ただ24MBはキャッシュとしては十分であっても、システム全体のメモリーとしては不十分である。
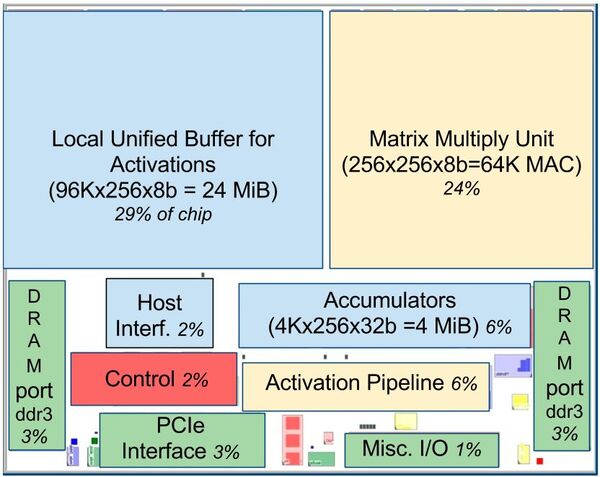
ブルーがバッファ、黄色が計算部、赤が制御系となっており、バッファが全体の37%、計算部が30%、制御が2%ほど。グリーンがI/Oで、これが10%ほどを占める
これを支えるためにDDR3-2133×2chのメモリーが合計32GB搭載され、これで足りなければPCI Express経由でホストのメモリーを利用できるかたちだ。ちなみにヒートシンクの陰に隠れていた基板が下の画像だ。

Google TPUの基板。DDR3はECC付きということで9個(72bit幅)の構成である
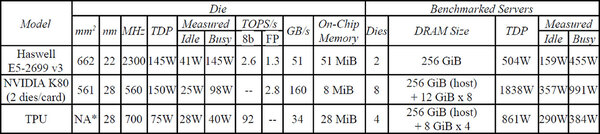
Google TPUのダイサイズは未公表だが、「Haswellの半分以下」という説明があるので、300平方mm程度と推定される。NVIDIA K80はNVIDIAのTesla K80のこと
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ











&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")




















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












