




優れたAIを作り出すには
膨大な学習が必要
AI、あるいはCNN/DNN(Deep Neural Network:層数の深いNeural Network)といった話題が一般にも出てき始めたのが、まさにこの2015年前後である。NVIDIAがGTCの基調講演で最初に機械学習に触れたのは2014年だったと思うが、この時点でAIに舵を切ったことを大々的に発表したのはNVIDIAが最初だったはずだ。
そのAIへの傾倒ぶりは、当時としては少し異様にすら映ったが、結果として現在Trainingの市場をほぼ独占していることを考えると、間違いではなかったと思う。
CNNのもう少し細かい動作や内部構造の話は次回解説するが、その前にTraining(学習)とInference(推論)について触れておく。人間であってもそうだが、そもそも「これは何」ということを知らなければ、分類することはできない。
ILSVRCの場合、スタンフォード大が立ち上げたImageNetと呼ばれる、巨大な画像ライブラリーを利用して学習させることになっている。
現時点ではここに1419万7112枚の画像が格納されているが、ILSVRC 2012の時点では128万1157枚の画像が学習用に提供されていた。このうち54万4546枚には注釈が付いている。この注釈というのは、要するにその画像がどんなものか、という説明である。
もともとImageNetでは、ボランティアで手作業で細かく画像の分類がなされている。これを利用して、あらかじめ学習という作業をするわけだが、これをどうやるか。一番ポピュラーな方法が、Back Propagation(誤差逆伝播法)という方法である。

mammal(哺乳類)→Placental(胎生)→Carnivore(肉食動物)→Canine(イヌ科)→dog(犬)→working dog(作業犬)→Husky(ハスキー)という具合に、細かく分類されている

こちらは説明の必要もないだろう
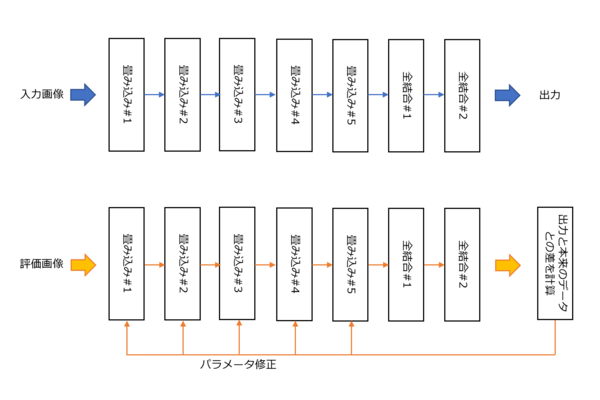
学習方法
上図はAlexNetを例にとったが、推論という処理は上段で、入力画像をまず入れてやると、ネットワークを通って最終的にその画像がなにか? というタグが出力される。学習は下段で、同じようにまず画像を入れるのだが、こちらはあらかじめ正解(例えば“犬”など)がわかっている画像である。
これをネットワークに通した結果、結果が“猫”だったら、これを“犬”と見なすように、各段のパラメータを細かく修正していくことになる。ただこれを1枚でやってたら全然収束しないので、大量(ILSVRC 2012なら128万枚)の画像を流し、トータルとして一番誤差が少なくなるように調整するわけだ。またその際に、まず畳み込み#5、次いで畳み込み#4、#3...というように逆順でパラメーターの調整をする形になる。
パラメーターの調整そのものは、人手でやれるような規模ではないので自動で行なわれるが、一般論として「大量に学習させるほど賢いネットワークになる」ため、とにかく大量の計算処理がここで発生することになる。
AlexNetの場合はNVIDIAのGPUカード2枚で2週間ほどかかったとしているが、5層ですらこれなので、ResNetなど猛烈な計算を必要としたというのは想像に難しくない。
今回はAIの概略の解説にとどめたので、次回はもう少し細かな説明をする予定だ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 - この連載の一覧へ











とBTO PCならではの特注PCパーツに大興奮")
























ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












