




XCCは大幅に性能が改善したように見えるが
MCC/EE LCCコアではどこまで性能が伸びるか怪しい
コア数に絡む性能の話を考えたい。記事冒頭の画像でも平均21%の性能向上とされており、また別のスライドでも似たような話が出ている。
ただSapphire RapidsはGolden Cove、Emerald RapidsはRaptor Coveであるが、もともとSapphire Rapids向けのGolden CoveはEmerald Cove同様に2次キャッシュが2MBだったのでここでの変化はなく、パイプラインの若干の改良に留まっているためIPCそのものはほとんど変わらない。
コア数も60コア→64コアだから6.7%程度の向上である。プロセスそのものは改良したIntel 7という言い方をしているので、Raptor Lakeと同じIntel 7+を利用して製造されているとは思うが、動作周波数そのもので言えば例えばSapphire Rapids世代のXeon Platinum 8490HがBase 1.90GHz/Max Turbo 3.50GHz、対してEmerald Rapids世代のXeon Platinum 8593QがBase 2.2GHz/Max Turbo 3.9GHzだから、Max Turbo同士の比較では11.4%ほどの改善である。
ただコア数×動作周波数で考えると1.067×1.114≒1.189で18.9%ほどの向上でしかないので、記事冒頭の画像にある“Average Performance Gain”が21%になるとは考えにくい。
実のところ、性能改善はそれ以外の部分で行われているように思われる。1つはタイル数減少によるレイテンシー削減である。
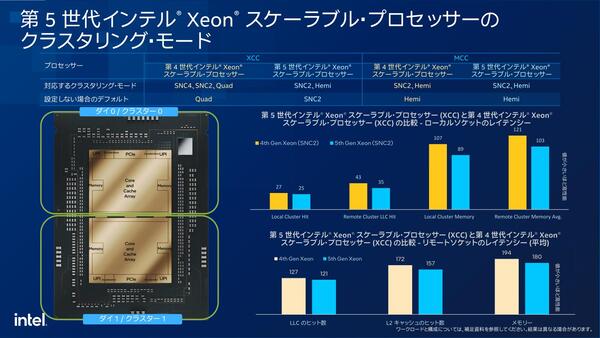
個々の数字そのものは非常に小さな改善であるが、なにしろ多数のコアが同時に動作するわけだから、当然この影響は大きい
Sapphire RapidsのXCCでは縦方向と横方向のRing Busが全部EMIB経由で隣りのタイルに接続されており、つまり縦方向/横方向どちらに通信する場合でもEMIB部分のPHYを介する分、余分なレイテンシーが発生する。
ところがEmerald Rapidsでは横方向は同一タイル内であり、縦方向の通信だけ余分なレイテンシーが発生することになる。どちらがオーバーヘッドが大きいかは明白だろう。
もう1つは、プロセス変更の効果だ。Raptor LakeはAlder Lakeと比べると同一周波数なら電圧を下げられるし、同一電圧ならより動作周波数を上げられるようになったという話を連載686回で説明したとおりである。
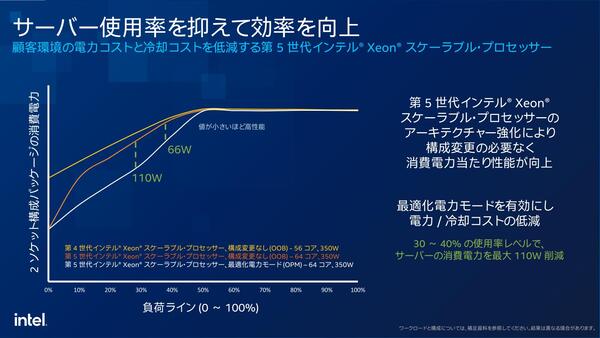
これは、Emerald Rapidsで新しく追加されたOPM(Optimized Power Mode)の説明である。UEFI Setupで設定するものだが、負荷が軽い時の消費電力を大幅に引き下げる。もっともその分若干性能にもインパクトがありそうだ
Emerald Rapidsが同じくIntel 7+であれば、同じ消費電力ならより平均的な動作周波数を引き上げられる。上の画像で、50%以下の負荷の場合はOPMを設定しなくてもEmerald Rapidsの方が消費電力が低いというあたりがこれを物語っている。
さらに、前頁の表にもあるがXCCではHigh Priority CoreとLow Priority Coreが設定されており、特にシングルスレッド性能を必要とするような負荷の高い処理はHigh Priority Coreに割り振られる=より高めの動作周波数で稼働するようになる、というあたりが実際の性能差につながっていると考えられる。
要するに記事冒頭の画像で性能/消費電力比を36%改善したとしているが、その性能/消費電力比をそのまま平均的な動作周波数向上に振った結果が今回の性能改善につながっていると考えられる。
もちろんここには、例えばLLCの大容量化による効果や、メモリーアクセスそのものの高速化(DDR5-5600のサポート)なども含まれるだろうが。
もう1つ、AVX Offsetに関しても違いがある。AVX Offsetは、特にターボが掛かっている際にAVXユニットをフルに動かすと電力がオーバーしてしまうため、動作周波数を下げて稼働する仕組みであるが、Emerald Rapidsではこれを5段階に変更している。
AVX512にしてもAMXにしても、フルに動かした際に負荷が重い命令と軽い命令が混在している。そこで、負荷が軽い命令に関してはオフセットの値を小さくして、より高い動作周波数で動作できる仕組みだ。これが一番顕著なのは、AIやHPC向けの処理をさせた場合であり、実際パフォーマンス向上の比較からもこれがうかがえる。
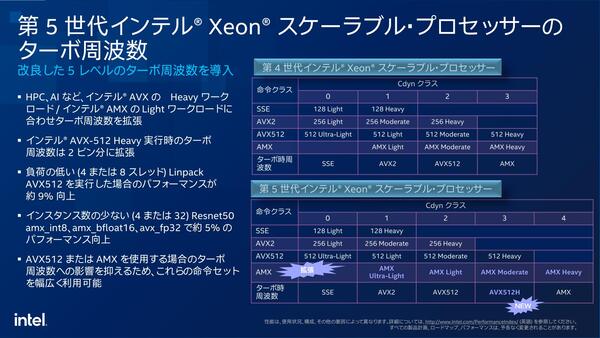
HPCやAIなどはAVX512とAMXを多用するケースが多く、こうした部分でAVX512/AMXユニットが高速で動くのは性能への寄与が大きい。ちなみにネットワーク処理はむしろアクセラレーターの範疇だが、ここはLLCの大容量化およびメモリー帯域拡大が効いていると思われる
以上のことから、確かにXCC同士で比較すれば大幅に性能が改善したように見えるEmerald Rapidsであるが、MCC/EE LCCコアを使う、つまり32コア以下のSKUではどこまで性能が伸びたのか、少し怪しい。最大の理由は先にも書いたがLLCが1.875MBに留まっていることだろう。
したがって、平均的な動作周波数の向上による性能向上は期待できるが、違いはそこだけである。加えて言えばMCCでDDR5-5600をサポートしているのは唯一Xeon Platinum 8562Y+で、他の製品はすべてDDR5-5200以下。EE LCCに至ってはDDR5-4800以下になっているあたりは、メモリー高速化の恩恵も期待できないことになる。このMCC以下の製品に関しては、性能向上はそこまで期待できないだろう。
なんというか、どうせならMCCも2タイル構成にすればこんな無理をする必要はなかったのにと思わなくもないのだが、一番下では1295ドル(Xeon Silver 4516Y+)のSKUまであることを考えると、2タイル構成は価格的に難しかったのかもしれない。
XCCとMCC/EE LCCでかなり性能ギャップがありそうな構成に仕上がってしまったのがEmerald Rapids世代のXeon Scalableというわけだ。
この連載の記事
-
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 - この連載の一覧へ



















の1台が今ならオトク!")

























")













