




3月29日、インテルはDCAI Investor Webinarを開催し、ここでXeonのロードマップと将来製品のちょっとしたプレビューを披露した。今回はこれを説明したい。このイベントは、OEMやエンドユーザーではなく、「投資家」に対してのセミナーである。
つまり投資家に対し「この通り、この先は順調に売り上げを伸ばし利益も増えていきます」ということを納得させるものである。したがって、嘘は付けない(これをやるとSECから刑事訴訟を含むペナルティを喰らう)が、逆に言えば嘘にならない範囲でギリギリ、明るい未来を見せることになる。
要するに仮に実現しなかったとしても「あの時はそういう予定だったんです」で言い逃れができる範囲で、精一杯楽観的な方向に予測を振るわけだ。もっとも別にこれはインテルだけでなくどこの企業も同じだし、ついでに言えばそのあたりは投資家もわかったうえで話を聞いてるわけで、その意味ではプレゼンテーションを文字通り鵜呑みにしている人は少ないとは思う。
2023年以降インテルの売上は伸び、2025年からはさらに伸びる
そのあたりを踏まえたうえで、まずは下の画像を見てもらいたい。水色の折れ線がコアの出荷数、縦棒が売上である。2022~2023年はSapphire Rapidsの遅延などもあって売上を落とすことになったが、2024年からは出荷数もグンと増え、これにともない売上も再び増加するという予測である。
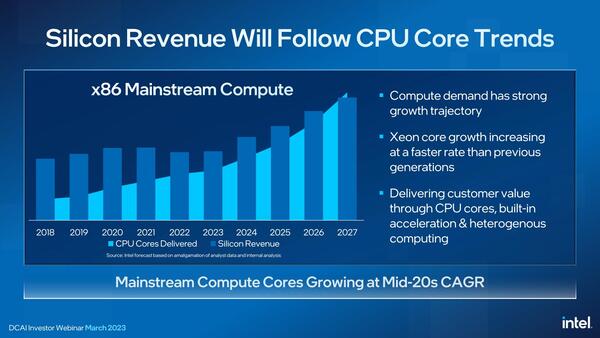
2027年までの予測で言えば、売上の成長率は平均年率20%台になる、というこれはこれで強気すぎる予測である
売上予測の方はおいておいて、もう少しわかりやすくなるようにコアの出荷数の方に赤線を追加したのが下の画像である。
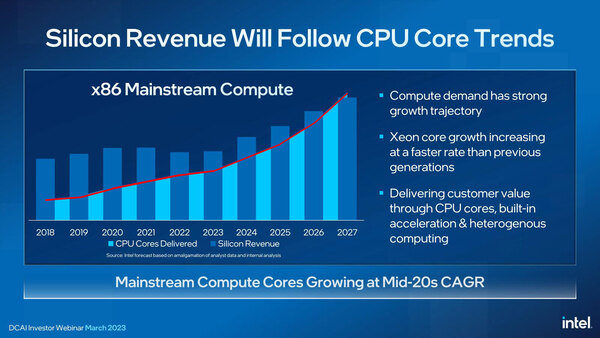
2019→2020と2020→2022では若干傾きが違う(鈍化している)。2023までのグラフは実績で、その先は予測(というか願望)となる
インテルの予測では、2023~2025年では大きく伸び、2025年からはさらに急激に伸びるとしている。これは今年中にIntel 4が立ち上がり、来年にはIntel 3も立ち上がることでこれによる生産量の上乗せがあり、さらに2025年からはIntel 20A(とその後継のIntel 18A)の分が追加になる、という皮算用である。
Emerald Rapidsは2023年第4四半期に量産開始
この皮算用の話は後でするとして、製品ロードマップの方を説明していく。まずは現在のSapphire Rapidsの後継となるEmerald Rapidsである。こちらはちょうどサンプル出荷を開始し、量産は今年第4四半期中とされる。

Emerald Rapids。プロセスやコア数などはもちろん未公開。説明によれば「サンプルのシリコンの品質はとても良い(≒歩留まりが十分に高い、あるいはきちんと動作している)」そうだ
このEmerald Rapids、シリコンのサンプルも公開された。

パッケージサイズはSapphire Rapidsと互換性があるとされている以上、78×57mmと推定される
これを回転させて歪を補正したのがこちら下の画像だ。ここから推定されるダイサイズは25.2×30.9mmで、実に778.7mm2という巨大な代物になる。

Emerald RapidsにMaxグレードがあるかどうかは不明である。個人的にはなさそうな気がするのだが
これだけあれば、Sapphire RapidsのXCCと実質的には同じだけの機能を突っ込むのも難しくないだろう。厳密に言えば若干面積は減る(Sapphire RapidsのXCCは400mm2のタイル×4で1600mm2、一方Emerald Rapidsは1557.4mm2である)が、その代わり下図でいうところの、横方向のEMIBが必要ない計算になる。

4タイルの構造推定図。推定されるダイサイズは25.2×30.9mmなので、図の横方向のEMIBが必要ない計算だ
EMIBが要らないというのは、要するにタイル間の接続のためのPHYなども要らないということだから、その分ダイサイズを節約できることなる。
ついでに言えばSapphire RapidsのXCCでは鏡対称になった2種類のタイルが必要だったが、Emerald Rapidsではその必要性はない。これなら180度回転して並べるだけで済むからだ。ただ、780mm2近くと言うのはもうReticle Limit(露光できるギリギリのサイズ)に近く、となると歩留まりは結構厳しいことになるだろう。
製造プロセスは先も言ったように公開されていない。以前流れてきた話では、Emerald RapidsはSapphire Rapidsと同じということであったが、プロセスが同じで基本のアーキテクチャーも同じだったら、コア密度を上げたり性能効率を上げたりすることはできない。
これは筆者の推定だが、おそらくEmerald RapidsはRaptor Lakeと同じIntel 7+を利用しているものと思われる。コア数はトータルで64程度だろう。そもそもIntel 7とIntel 7+では、ロジック密度そのものは変わっていない。したがって、基本的なタイル内のコアやその他の要素は大きくは変わらないだろう。
ただSapphire RapidsのXCCの場合は5×4の構成だったが、これをそのまま横方向につなげて10×4にすると、もっとタイルが細長くなりそうだ。寸法から考えると6×7という構成か? というあたりで、ここからタイルあたり以下の構成で合計10個を抜くとCore/LLC用に32個分のブロックが残る。
- DDR5×2
- UPI×2
- PCIe or CXL×2
- PCIe×4
これを組み合わせて最大64コアというのが筆者の推定だ。ただ最大でも60コアだったSapphire Rapidsよりは4コア増えることになるので、ソケットあたりのコア密度は上がる。
そして仮にIntel 7+を使ったまま、動作周波数を据え置き、あるいは微増程度に留めておけば、性能/消費電力比は向上することはすでにRaptor Lakeで実証済みである。はDCAI Investor Webinarで示されたEmerald Rapidsの特徴は、比較的確実に実現できそうである。
問題は2023年第4四半期中(ということは2023年12月まで)に出荷できるかどうか? である。Sapphire Rapidsの例を取ると、2022年5月11に開催されたIntel Vision 2022で、Sandra L. Rivera氏が「Sapphire Rapidsの最初のSKUの出荷を開始する」と宣言したが、実際に製品が出荷開始されたのは2022年1月10日だった。つまり8ヵ月ほどのラグがあることになる。

これはIntel Visionの基調講演のWebcastから。「Sapphire Rapidsの最初のSKUの出荷を開始する」と宣言している
同じ法則を当てはめると、ギリギリ2023年11月~12月には量産出荷が可能という推定が成り立つが、さてどうだろうか? Emerald Rapidsについては筆者はあまり心配していないのだが。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 - この連載の一覧へ











&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")




















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












