




SoCタイルは省電力性を最大限に生かす設計
では、そのMeteor Lakeの構造である。内部構造の推定は連載720回でお届けしたが、おおむね米国で特許出願した際の構造に近いものとなった。
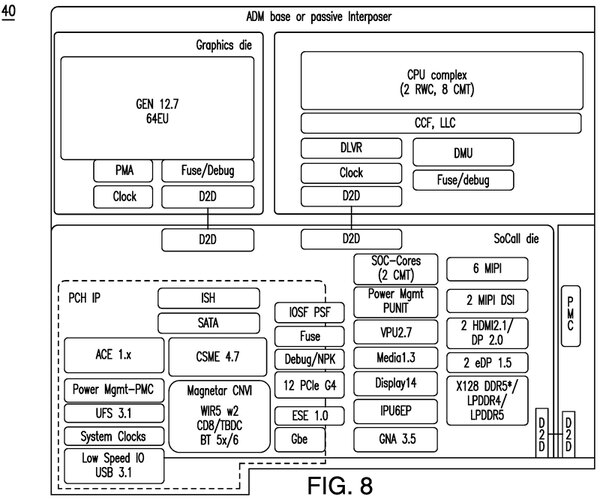
米国で特許出願した際に提出されたMeteor Lakeの内部構造
ただこの図ではコンピュート・タイルはPコア×2+Eコア×8であるが、今回説明されたものはPコア×6+Eコア×8の構成であり、またIOタイルも存在する。これはいわばSKU次第であって、ローエンド向けにはPコア×2+Eコア×8でIOタイルなしのものもあるかもしれない。
また連載720回では4次キャッシュの存在の可能性について論じたが、少なくとも現時点では4次キャッシュに関しての言及がまったくない。
ただし大きな違いはSoCタイルに搭載されている2コアのEコアである。筆者はこの2コアのEコアを「セキュリティ制御専用と言うよりは、SoC側のもろもろの処理をCPUタイル上のCPU Complexを動かすことなく行なえるようにしよう、ということのようだ。」と書いたが、間違ってはいないものの正確ではなかった。
確かにブートの際にはセキュアブートなどの処理のために利用されるのだろうが、OSの起動後はこのSoCタイルのEコアもまたOSの管理下に置かれることになる。つまりMeteor LakeのCPUコアはPコア×6+Eコア×10になる。
もっともここからがMeteor Lakeの大きな特徴である。ハードウェア的に言えばコンピュート・タイルのEコアもSoCタイルのEコアも同じCrestmontコアであるが、コンピュート・タイルの方はIntel 4プロセスで「最大のマルチスレッド性能」を発揮するように実装されているのに対し、SoCタイルの方はTSMC N6で省電力性を最大限に生かすような実装になっている。
要するに物理設計におけるPPA(Power, Performance and Area)のターゲットが、コンピュート・タイルの方はやや高性能寄りになっているのに対し、SoCタイルの方は省電力/省エリアサイズに振った形になっている。この結果として、それぞれのコアの性能は見事にばらけることになる。

SoCタイルのEコアの動作周波数は不明だが、それこそ1GHz未満(600MHzなど)の可能性もある
ではこれをどうやって制御するかであるが、スレッド・ディレクターにずいぶん手が入った。下の画像がその模式図である。基本CreateThread()やpthread_create()などで生成されたスレッドは、親スレッドと同じプロセッサーコア上で稼働しそうな気もするのだが確証はない。

スレッド・ディレクターの模式図。例えばPコアで動作中のスレッドが新たにスレッドを作った場合、それがSoC Eコアから動くのか、それともいきなりPコアで動くのか、などいくつか不明確なところは多い
Alder Lake/Raptor Lakeでは、テーブルの登録に応じてPコアないしEコアに処理が割り当てられ、その後も監視しながら負荷が低いものはEコアに、負荷が高いものはPコアに移行する形で負荷分散を図っているのが原則である。
これに対して、Meteor Lakeではまずすべての処理はSoCタイルのEコアで動かし、ここで負荷が大きい場合はコンピュート・タイルのEコアに移行させ、それでも足りなければPコアに移行する。
この結果として、例えばOSのタスク類は常にSoCタイルのEコアで動き、コンピュート・タイルのEコア/Pコアはアプリケーションの処理に割り当てられる、というのはインテルの説明である。
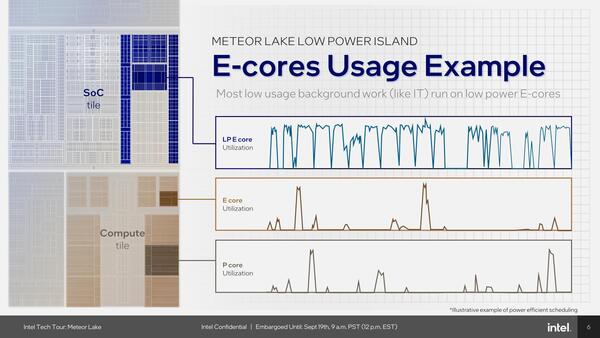
つまり一番稼働率が高いのがSoC Eコアになる
連載735回で、Meteor LakeのDVFS(Dynamic Voltage and Frequency Scaling)にはAIが利用されていると説明した。おそらくはAIを利用してタスクをIdle/Fixed QoS/Sustained/Burstyに分類、それぞれの特徴に応じて動作周波数や電圧の制御を行なうというものだが、これは単にDVFSだけでなくスレッド・ディレクターでも活用されていると考えられる。
OSのタスクはFixed QoSあたりに分類され、基本はSoC Eコアで。そしてアプリケーションの処理はSustained/Burstyに分類され、コンピュート・タイルのEコアやPコアに推移すると思われる。
思うに、まずSoCタイルのEコアで動かすのは、そのEコアでの稼働中に動作状態のサンプルを取り、そのサンプルを基にタスクの種類をAIを使って判断するためと考えられる。
ただ別の見方をすると、Alder Lakeの時に説明された「省電力のEコアとパフォーマンスのPコア」という分類は、Raptor Lakeの時点でだいぶ怪しかった(*1)が、Meteor Lakeでは省電力なのはSoCタイルのEコアのみで、コンピュート・タイルのEコアは“Efficient MT performance”を実現するあたりは、それなりに動作周波数が引きあがるものと考えられる。
もっともMeteor Lake、現在のパッケージがモバイル向けのみなので、最大でもH SKUの45~65Wで、メインはP SKUの28~35Wレンジになるだろうと考えると、どこまで動作周波数が積みあがるのかはわからない。
(*1) フル稼働時はEコアも限界までぶん回すことでマルチスレッド性能を引き上げるという実装になり、結果としてRaptor Lakeを爆熱CPUに仕立て上げた。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























