



ロードマップでわかる!当世プロセッサー事情 第736回
第6世代XeonのGranite Rapidsでは大容量L3を搭載しMCR-DIMMにも対応 インテル CPUロードマップ
2023年09月11日 12時00分更新

前回に引き続き、Hot Chips 2023での発表について説明しよう。今回のHot ChipsでインテルはXeon関連で2つ発表をしている。1つは今回紹介する“Architecting for Flexibility and Value with future Intel Xeon processors”、もう1つは次回紹介する“Intel Energy Efficiency Architecture”である。ということでまずはその将来のXeonプロセッサーについてだ。

Sierra Forest/Granite Rapids以降の世代では
AMDと同様のチップレット構成になる
基本的なアイディアは、データセンターにおけるワークロードのニーズが次第に拡大し、クラウドサービスに代表されるサーバー台数の増強(スケールアウト)の方向と、HPCやAIなどの処理能力を高める(スケールアップ)の方向の2つに大きく分かれつつあることからスタートしている。
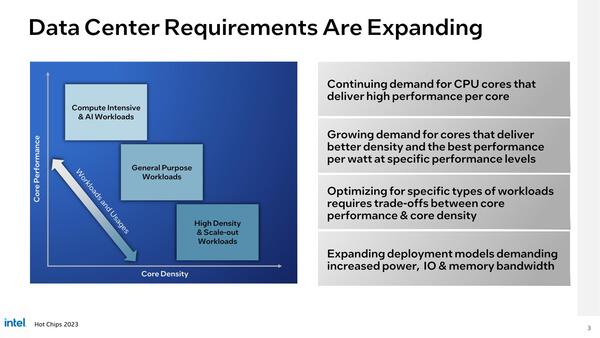
データセンターの要件が拡大している。なにを今さら、という話でもあるのだが……
そこで、PコアとEコアをそれぞれの用途向けに利用するのが現在の方向である。現行のXeon Scalableは基本Pコアのみで構成されているが、来年にはEコアベースのSierra Forestが投入される(これにIntel 3プロセスが利用される)のはすでに発表済み。この2つの製品ラインが今後も継承されることが再確認できたのが下の画像となる。
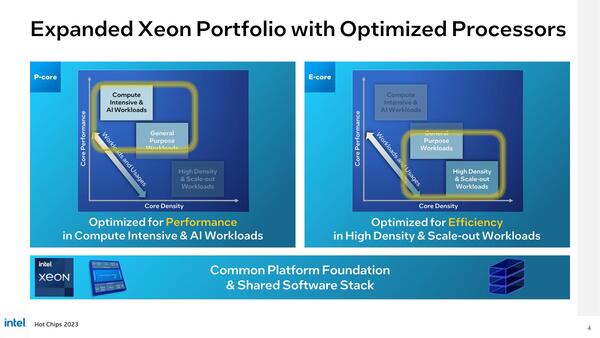
Xeon Scalableは2つの製品ラインが継承される。Eコアのラインが本当に一般的用途向けに十分な性能なのか? というのはまだ検証が済んでいない
現在出荷中の第4世代Xeon Scalable、つまりSapphire Rapidsと、年末までに発表される予定のEmerald Rapidsは、どちらもPコアベースなので上の画像の左にある“Optimized for Performance”に属する製品であるが、すでにマルチタイルによるモジュラー構成である。Sapphire Rapidsの説明はもう不要だろうし、Emerald Rapidsもサンプルの写真を見る限りはマルチタイル構成である。

Emerald Rapidsのサンプルの写真
逆に“Optimized for Efficiency”に分類されるSierra Forestの方はまだ構成が不明であるが、今さらモノリシックな巨大なダイを作るとは思えない。AMDのEPYCはいち早くチップレット構成を取っており、しかもコンピュートタイル(CCD)とI/Oタイル(IOD)を分離する形で実装していた。
これに比べるとインテルの方はコンピュートとI/Oを混在したタイル同士を接続する方法をSapphire Rapidsでは取っており、おそらくEmerald Rapidsもこれを踏襲しているものと思われる。次々世代、つまりSierra Forest/Granite Rapids以降の世代ではAMD同様の構成になることが今回明らかにされた。
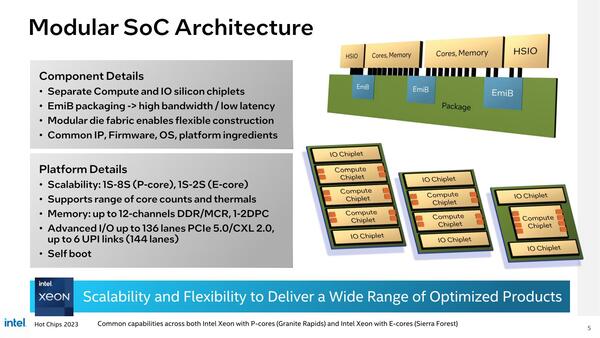
コンピュートタイルが明らかに2種類あるあたりが謎。左と中央がPコアタイル、右がEコアタイルなのだろうか? それはともかくEMIBの表記が“EmiB”になっているのは、どういうことなのだろう?
昨今の先端プロセスでは、大容量の3次キャッシュやPHY、I/Oなどの機能を先端プロセスで作ると無駄が多いことはこれまで何度か説明してきた。先端プロセスで作った場合と古いプロセスで作った場合で、ほとんど面積が変わらない。だとすると、先端プロセスで作っても機能が変わらずにコストだけが上昇するからだ。
これを明確に示しているのがAMDのNavi 31/32であり、メモリーコントローラーとインフィニティ・キャッシュはTSMCのN6で、GPUコアそのものはTSMCのN5で製造されている。EPYCシリーズもMilan世代からはメモリーコントローラーやI/Oなどは全部TSMC N12で製造されるIODに集約される格好だ。今回のインテルの発表は、この構図に「一歩近づいた」形になる。
ただし、その実装方法はけっこう異なる。下の画像がその内部構造だが、メモリーコントローラーは各コンピュート・チップレットに分散配置される形になる。またコンピュート・チップレット内部のメッシュを延長するような形で相互接続されるというのはSapphire Rapidsの時と同じだ。
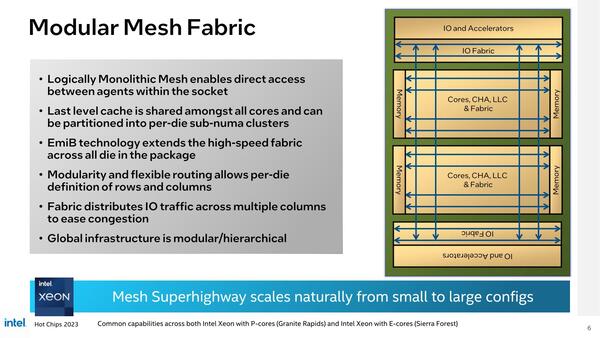
Emerald Rapidsの内部構造。アクセラレーターはIOファブリックの外側に置かれているのが興味深い。ここは別にしたわけだ。この方式では、コンピュート・チップレットの数でメモリーI/Fの数が決まってしまうのだが、そのあたりをどうするつもりなのだろうか
Sapphire Rapidsの場合、4つのタイルを鏡対称で接続する関係で、2種類のタイルを用意する必要があり、これが明らかにコストアップの要因になっていた。Emerald Rapidsでは巨大なタイル×2にしたのは、この方式では同一のタイルを180度回転させて接続するだけで済むため、タイルを一種類で済ませられる。
上の画像の次世代Xeonの場合はこの方式を踏襲し、メッシュの横方向は1つのチップレット内で完結させ、縦方向を相互接続する形に変更したようだ。このやり方では、チップレット数が増えると縦方向が長くなりすぎる可能性があるが、おそらくはチップレット内では縦方向の接続を最小限とし、横方向を長めに取る形でバランスを取っているのだろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























