




Stable Diffusionで動画生成「AnimateDiff」に注目
いま、AIによる動画生成はホットな分野です。
ランウェイは今年2月、動画生成に関する論文を発表していますが、実はこれを受ける形でStable Diffusionでも同様の研究発表がありました。それが7月10日に登場した「AnimateDiff」。ビデオクリップで独自に訓練した「モーション・モデリング・モジュール」という仕組みによって、首尾一貫した動画を生成可能にするというものです。
花火#AnimateDiff
— Artoid XYZ (@Artoid_XYZ) July 30, 2023
AI Art / StableDiffution pic.twitter.com/9N8ZZbHTxj
AnimeteDiffの作成例
AnimateDiffは上海AIラボ、香港中文大学、スタンフォード大学の共同研究。ControlNetを作ったチャン・リュミンさんが所属していた大学が関わっていることもあり、画像生成AIでの研究人脈も感じられますね(「画像生成AIに2度目の革命を起こした『ControlNet』」参照)。
発表時には60GBものビデオメモリーが要求されるなど動作環境のハードルが非常に高く、事実上、専用の環境でなければ動作不可能なものでした。ところが発表後わずか1週間で12GBまでビデオメモリー容量を下げる方法が見つけられ、ビデオメモリー24GBの「NVIDIA GeForce RTX 3090」以上なら動作することが確認されました。
その後「Stable Diffusion web UI(AUTOMATIC1111 版)」の拡張機能として移植され、専用の独立したソフト「Vision Crafter」も登場しました。複数の画像を同時に作るという性質からビデオメモリーの要求は高く、動作環境を持つ人は限られますが、アニメ風のキャラクターであっても自然な動きを実現できる可能性が出てきています。
現在は2〜6秒程度の生成ができますが、長時間になるほど破綻する絵が出る傾向が高いようです。
AnimateDiff専用アプリ「VisionCrafter」で生成した6秒の動画サンプル。生成時間はNVIDIA GeForce RTX 4090環境で3分程度。自動生成の音楽生成機能も入っている
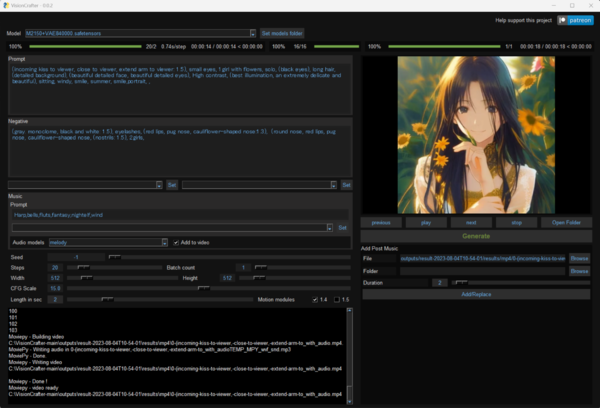
「VisionCrafter」の画面
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第150回
AI
無料でここまで? 動画生成AI「LTX-2.3」はWan2.2の牙城を崩すか -
第149回
AI
AIと8回話しただけで“性格が変わる” 研究が警告する「おべっかAI」の影響 -
第148回
AI
AIが15万字の小説を1週間で執筆──「Claude Opus 4.6」が示した創作の未来 -
第147回
AI
ゲーム開発開始から3年、AIは“必須”になった──Steam新作「Exelio」の舞台裏 -
第146回
AI
ローカル音楽生成AIの新定番? ACE-Step 1.5はSuno連携で化ける -
第145回
AI
ComfyUI、画像生成AI「Anima」共同開発 アニメ系モデルで“SDXL超え”狙う -
第144回
AI
わずか4秒の音声からクローン完成 音声生成AIの実力が想像以上だった -
第143回
AI
AIエージェントが書いた“異世界転生”、人間が書いた小説と見分けるのが難しいレベルに -
第142回
AI
数枚の画像とAI動画で“VTuber”ができる!? 「MotionPNG Tuber」という新発想 -
第141回
AI
AIエージェントにお金を払えば、誰でもゲームを作れてしまうという衝撃の事実 開発者の仕事はどうなる? -
第140回
AI
3Dモデル生成AIのレベルが上がった 画像→3Dキャラ→動画化が現実的に - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















