



ロードマップでわかる!当世プロセッサー事情 第721回
性能ではなく効率を上げる方向に舵を切ったTensilica AI Platform AIプロセッサーの昨今
2023年05月29日 12時00分更新

意外なところで使われている
Xtensa LXシリーズ
この後Tensilicaは次々に新製品というか新IP(?)を発表していく。2000年にはXtensa III、2001年にXtensa IV、2002年にXtensa V、2004年には第6世代のXtensa LXを発表している。
このXtensa LXの延長で、現在でもXtensa LX7が発売されているし、そのXtensa LXシリーズをより高性能の方に振ったXtensa NXシリーズもある。

Xtensa LX7の内部構造。相変わらず自由度は高い
少し話が横道に逸れるが、このXtensa LXシリーズは意外なところで使われていたりする。例えばローレンス・バークレー国立研究所のNERSC(National Energy Research Scientific Computing Center)といえばPerlmutterを導入したサイトで、連載510回、連載608回、連載617回でその名前を紹介しているが、そのNERSCが2008年頃から行なっていたものにGreen Flash Projectという取り組みがある。
これはHPCシステムをいかに効率的に実装・運用するかを研究するもので、2009年3月には最初のプロトタイプが稼働したが、このシステムはVILW CPUを32コア集積したチップにDRAMを組み合わせ、これを32個集積したボードをラック当たり32枚実装、100ラック程度で10PFlopsの演算性能を実現するというものだ。
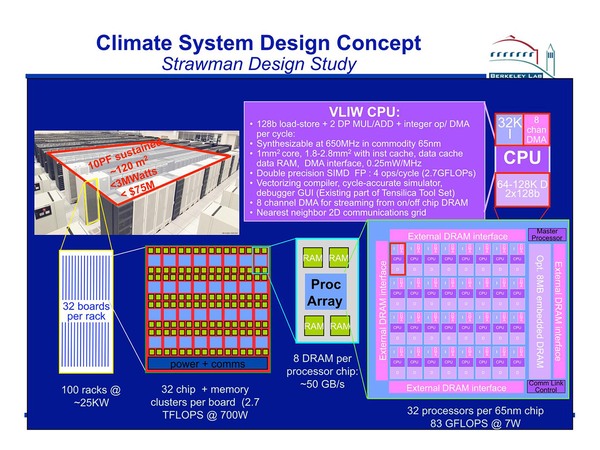
ラックの写真はおそらく適当に持ってきたもので、Green Flash Projectのものではないと思われる
このVLIW CPUというのがまさにXtensaであって、チップ1個で83GFlopsを消費電力7Wで達成している。2009年と言えば、NVIDIAならまだ40nmプロセスで製造されるFermi世代に相当し、単体性能が一番高かったM2090が40nmプロセスで666GFlops/250Wで、効率は2.67GFlops/W程度。7Wで83GFlops(=11.86GFlops/W)を65nmプロセスで実現してしまったXtensaの効率がいかに高かったかがわかる。
ちなみにNERSCにおける分析が下の画像だ。BlueGene/P(と比較してもはるかに効率が良いシステムを、しかもさらにお安く実装できることをこのプロジェクトでは実証して見せた格好だ。そしてその核がXtensaだったというわけだ。
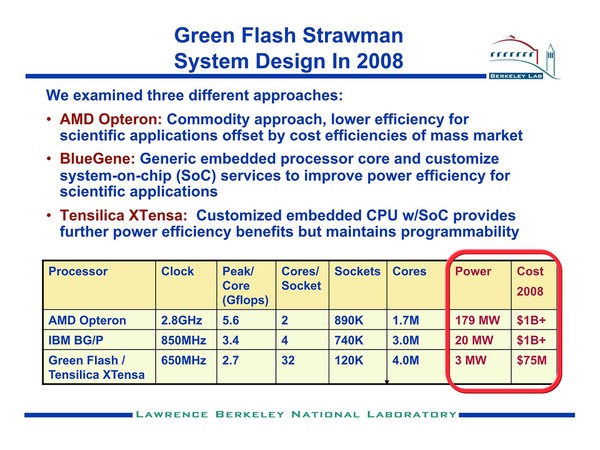
BlueGene/Pの効率は突出して良かった、というわけでもなかったので、これを追い抜くことそのものは極端に難しかったわけでもないとは思う
話を元に戻そう。XtensaはCPUであり、複雑な分岐を含む処理を高速に行なえることを特徴とするが、信号処理などの分野に関して言えば別にそこまで複雑な分岐などは発生しないし、繰り返し処理がメインになるため、CPUコアの性能はそう必要なく、むしろDSP(Digital Signal Processor)コアを強化することが好ましい。こうした用途に向けてDSPソリューションも提供し始める。
といっても、実際はXtensa LXコアにDSPという構成は変わらないのだが、DSPユニットを強化した構成である。2009年頃の製品ポートフォリオで言えば、オーディオ向けにHiFi Audio Engine(Dual 24bit MACを搭載したDSPとXtensa LX2を組み合わせたもの)や388VDOというビデオエンコード/デコードプロセッサー、超高速汎用DSPであるDiamond 545CK(3-issue VLIW DSPに8-way SIMDを組み合わせた物)などがラインナップされるようになった。
もちろんもう少し下のグレードの製品も多数用意されている。ちなみにDiamondシリーズというのはCPUというよりMCUを志向した、省電力コントローラー向けIPである。

2009年3月におけるTensilicaのDSP IPのページより
そんなTensilicaであるが、2013年にCadenceに買収される。このあたりの経緯はSynopsysに買収されたARC Internationalと大して変わらない。違いがあるとすれば、ARC InternationalはVirage Logicに買収され、それがさらにSynopsysに買収された形だが、TensilicaはCadenceに直接買収されたということくらいだろうか。
Cadence傘下になった後も、引き続きTensilicaブランドでCPU/DSP IPの提供はされており、いろいろなところで利用されている。有名なところでは、AMDのRadeon R9/R7シリーズから搭載されたTrueAudioという技術があるが、これはTensilicaのHiFi 2 EPというDSPをベースに構築されたものである。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























