



ロードマップでわかる!当世プロセッサー事情 第617回
AMDとNVIDIAがPerlmutterを当初のタイムライン通りに納入 スーパーコンピューターの系譜
2021年05月31日 12時00分更新

スーパーコンピューターの系譜
Perlmutterが稼働開始

米国立エネルギー研究科学計算センター(NERSC)が導入する新しいスーパーコンピューター「Perlmutter」
ということで今週の本題は、米国立エネルギー研究科学計算センター(NERSC)のPerlmutterである。Perlmutterは連載510回でまず概略を、その後連載597回や連載608回で断片的に情報を紹介したが、こちらの運用が始まったという発表が米国時間の5月27日にあった。すでにPerlmutterのサイトも公開されている。
今回導入されたのはフェーズ1と呼ばれるCPUとGPU混載のノードである。もともとPerlmutterではCPU Only NodeとCPU+GPU Nodeの2種類があるという話は以前紹介した通りであるが、フェーズ1ではこのCPU+GPU Nodeの設置を行なう。フェーズ2は今年後半に運用開始になる予定で、こちらはCPU Only Nodeの設置となる。
ちなみに構成であるがフェーズ1では以下が設置される。
| フェーズ1で設置されるノード数 | ||||||
|---|---|---|---|---|---|---|
| GPU-accelerated compute node | 1536ノード/12キャビネット | |||||
| ログインノード | 15ノード | |||||
GPU-accelerated compute nodeはAMD EPYC 7763+NVIDIA A100×4という構成で、CPUとGPUはPCI Express Gen4で、GPU同士はNVLink 3で、外部へのNICはPCI Express Gen3で接続という構成である。メモリー容量は1ノードあたり256GBとされている。
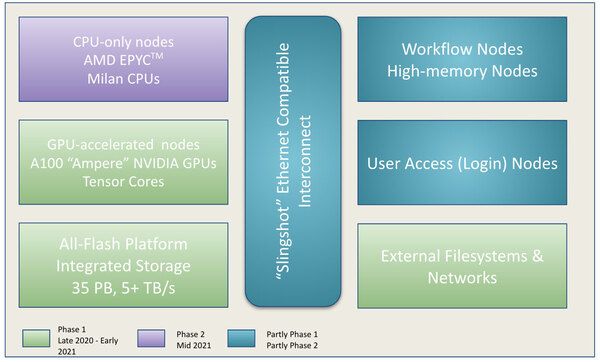
GPU-accelerated compute nodeの構成。Workflow NodeやHigh-memory Nodeの詳細は不明。CPU-only nodesにいろいろバリエーションを追加するのかもしれない
このGPU-accelerated compute nodeが2つ、1本のCompute Bladeというシャーシに収まる格好になる。1本のキャビネットは8つのセグメントに分割され、各々のセグメントには8枚のCompute Bladeと4枚のSwitch Blade(これはネットワークスイッチ)が搭載されるので、合計するとキャビネットあたり64 Compute Blade、128ノードのGPU-accelerated compute nodeが内蔵される格好になる。
フェーズ1はこれを12キャビネット並べるので、トータルすると1536ノードとなり、AMD EPYC 7763が1536個とNVIDIA A100が6144枚装着されることになる。
もっともプレスリリースを確認すると、AMDの方は「1536ノードにおのおのEPYC 7763が1つずつインストールされる」という表現でこれはいいのだが、NVIDIAの方を見ると、“6159 NVIDIA A100 Tensor Core GPUs in Perlmutter”と書いてあり、差の15枚はどこから出てきた? という謎な結果になっている。
おそらくは冗長ノードがいくつか用意されているほか、交換用にも何枚か提供された結果が15枚というあたりなのではないかとは思うが、これに関する詳細は明らかになっていない。
これと別にログインノードが15ノード用意されるが、こちらは1ノードあたり2つのEPYC 7742が搭載され、512GBメモリーと960GBのローカルストレージが搭載されている。こちらは名前の通り、利用者がログインして作業するマシンで、このログインノードからPerlmutterにジョブを投げるイメージになるかと思う。
これに続いて導入されるのがフェーズ2であるが、こちらは同じ米国立エネルギー研究科学計算センターのCoriを置き換えるシステムである。
以前も書いたが、CoriはXeon Phiをベースとしたシステムで、HaswellベースのXeon E5-2698 v3ベースが14キャビネット/2388ノードと、Knight LandingベースのXeon Phi 7250ベースが54キャビネット/9688ノード用意され、合計で32.3PFlopsの演算性能(ピーク値)を発揮するというものだった。
ところがXeon Phiの製品ラインそのものの廃止にともない、ここで動いていたアプリケーションを通常のx64ベースで稼働させる必要が出てきたため、これをフェーズ2でカバーする形となる。
フェーズ2はノードあたり2つのGen 3 EPYC(型番は不明)に512GBメモリーを組み合わせる構成で、フェーズ1と同じく1536ノード(=EPYCが3072個)となっている。もしフェーズ2も同じくAMD EPYC 7763で構成されるとすると、FP64での理論上のピーク性能は7.8PFlopsほどになる計算である。
フェーズ1の方は、FP64はCPUが3.9PFlops、GPUが59.9PFlopsで、合計60PFlops超ということで、Coriのほぼ2倍といったところ。ただXeon Phiはピーク性能を出すのが非常に困難な、ピーキーなカードだったことを考えると、実効性能で言えばアスキーの記事で触れられていた「現在NERSCで利用可能な計算能力の4倍を達成すると期待」されるのも妥当な気がする。
ちなみにフェーズ2が完成すると、合計の演算性能は71.6PFlops(FP64)で、仮に演算効率が100%だとしても昨年11月のTOP500のリストで言えば37位くらい、効率が80%程度だとすれば50~51位あたりになる計算で、絶対性能という点では大きなインパクトはない。
ただAMDのMilanベースのEPYCや、NVIDIAのA100を搭載した初のHPCマシンという意味では大きなマイルストーンである。もっと言えば、AMDとNVIDIAはこれを当初のタイムライン通りに納入したということが非常に大きなポイントである。
AMDはこれに続きオークリッジ国立研究所にFrontierの納入をやはり今年からスタートするし、来年にはEl Capitanへの納入もスタートする。
対するインテルは、同じく今年中に納入を始める予定だったAuroraが予想通り遅れており、それもあって「Ponte VecchioをNVIDIAのGPUに変えた方がいいんじゃないか」というような記事が昨年登場していたが、確かにNVIDIAの好調ぶりを見ているとそれもうなずける。
ただ、GPUだけでなくCPUのSapphire Rapidsも本当に今年中にリリースされるか疑わしいという状況では、GPUだけ交換しても意味がないという話もある。このあたり、年末あたりにはもう少しはっきり状況が見えてくるだろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ














ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")
















