



ロードマップでわかる!当世プロセッサー事情 第682回
Meteor Lakeの性能向上に大きく貢献した3D積層技術Foverosの正体 インテル CPUロードマップ
2022年08月29日 12時00分更新

Meteor LakeがFoverosを利用する理由は
バイパスコンデンサーが必要だったから
タイルの中身はともかく、ここで謎なのがベースタイルの意味合いである。Meteor Lakeでは個々の機能はすべて4つ(CPU/GPU/SoC/IOE)のトップタイルに実装されているから、ベースタイルは単にこの4つのタイルをつなげるだけの意味合いでしかない。であれば、そもそもFoverosではなくEMIBでも良かったのでは? と思うのだが、Meteor Lakeがベースタイルを入れてFoverosを利用することにはちゃんとした理由があった。それが下の画像である。
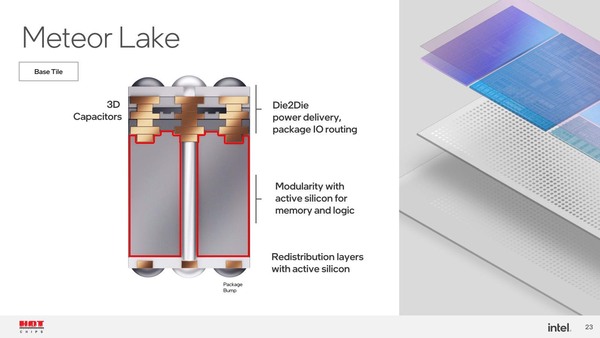
赤枠は筆者が追加している。なぜMeteor LakeがEMIBでなくFoverosを利用したのか? の解がやっとクリアに得られたので個人的には満足である
Meteor Lakeのベースタイルの役割は以下の3つに分けられる。
- トップタイル同士の接続(“Die2Die Power delivery, package I/O routing”の部分)
- パッケージ外(つまりCPUパッケージから基板に接続する部分)への配線(“Redistribution layers with active silicon”の部分)
- 3Dキャパシター
このうち最初の2つは理解は簡単だろう。トップタイル同士の接続はベースタイルで行なうしかない。それと外部への接続も当然必要だ。ただ、これだけなら先に書いたようにEMIBでもほぼ同じことができる。EMIBでなくFoverosを利用した理由は、この3番目である。上の画像の赤枠部分を丸ごと3D構造のコンデンサーにしており、これはトップタイルの電源供給ピンへのパスコン(バイパスコンデンサー)として動作することになる。
パスコンが最新のプロセッサーでなぜ重要になるか? という話は連載658回のGraphCore BOW IPUの解説の中で説明した。BOW IPUはTSMCのSoIC-WoWを利用して、コンデンサーとなるダイをIPUのダイに張り付けることで3割強の性能改善を果たしたわけだが、インテルはMeteor Lakeでベースタイルにこのコンデンサーの役割を担わせたわけである。これがEMIBではなくFoverosが必要になった、最大の理由である。
この効果は顕著で、実際Intel 7、つまりAlder Lakeの世代ではパスコンの密度が193FF(Femto Farad:pFの1000分の1)/μm2に過ぎなかったのが、Foverosを併用することで500FF/μm2と、2.5倍に向上することになったとしている。
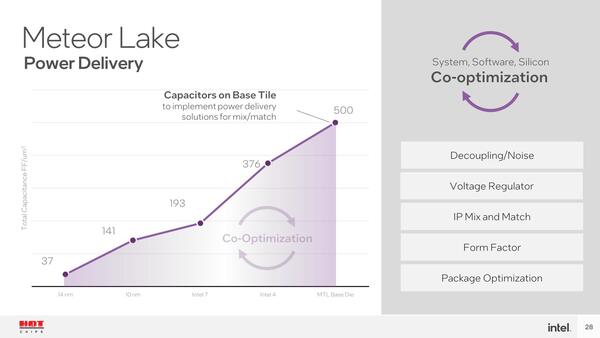
縦軸は“Total Capacitance”、つまりパッケージ内の容量とパッケージ外部に積層するパスコンの両方の合計である。14nm世代まではパッケージ内のコンデンサーはないに等しく、外部のパスコンのみだったのが、ここからどんどん容量を上げていった格好だ
全体に話を戻すと、Meteor Lakeではバンプのピッチが36μmとなっており、これは続くArrow Lakeでも変わらない。したがって、Foveros OmniではなくFoverosでの実装となっている。
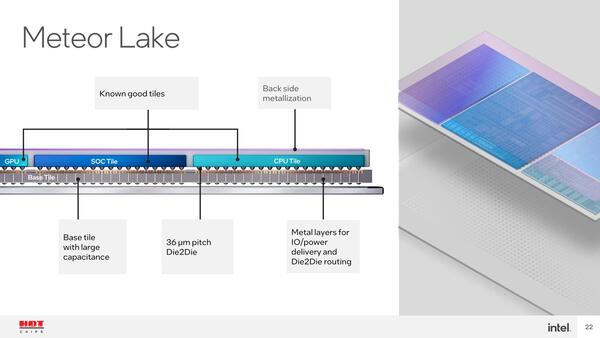
Meteor Lakeのバンプピッチは36μm。ちなみにMeteor Lakeのベースタイルのプロセスは未公表。GraphcoreのBOW IPUの場合は40nmプロセスで製造したらしいが、ベースタイルはどうだろう? 14nmでもまだおつりが来る感じで、ひょっとするとこちらもTSMCの40nmあたりでの製造なのかもしれない
ここでダイ同士の接続であるが、これはFDI(Foveros Die Interconnect)という独自のインターコネクトが採用されている。
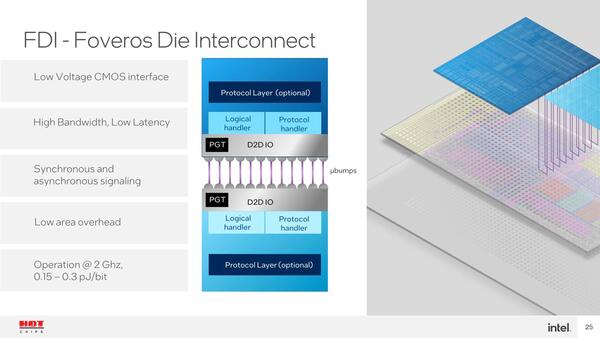
ダイ同士はFDIという独自のインターコネクトで接続されている。ちなみにZen 3のInfinityFabricでは、確か2~3pJ/bitである。あちらは距離が長いし、通常のパッケージ上の配線なので同列に比較するのは間違っているのだが……
FDIに関してインテルに説明を投げたところ、以下の返事が返ってきた。
- FDIは3D積層向けの独自のインターコネクトで、現時点ではLakefield、Ponte Vecchio、それとMeteor Lakeで採用されている。
- FDIはあくまで物理的な規格であり、上位で任意のプロトコルを通せる。必要ならUCIeを通すことも可能。
- 現在の配線密度は1K信号/mm2だが、Hybrid Bondingでは10K信号/mm2、今後さらにバンプのピッチが縮まれば、100K信号/mm2も可能。
要するにFDIは単なる物理層の規格であって、上位のプロトコル層はなんでも構わないという話である。実際Meteor Lakeは以下の3種類のプロトコルを使い分けている。
- SoC Tile⇔CPU Tile:IDI
- SoC Tile⇔GPU Tile:iCXL
- SoC Tile⇔IOE Tile:IOSF+DisplayPort
このうちIDI(In-Die Interface)はSilvermont世代から利用されている、SoC内部でCPUコア同士を接続するためのプロトコルである。一方IOSF(Intel On-chip System Fabric)は、連載231回で名前が出てきたが、チップセット内部での接続に利用されるプロトコルである。今回の場合、PCIeのRoot ComplexそのものはSoCタイル内にあり、PHYがIOEタイルにあると思われ、このRoot ComplexとPHYの接続にIOSFを利用しているのだろう。
それはともかくiCXLって何? という話で質問が殺到したが、インテルの回答は「Meteor LakeはCXLはサポートしないが、CXLの規格そのものはインテルもサポートしており、将来のXeアーキテクチャーベースのコンピュート・アクセラレーターでCXLをサポート予定である。iCXLは、CXLの規格からPHY部分を除いて実装した内部的なもので、Die2Die I/Fをサポートする」という返事が返ってきた。
要するに、「GPUを接続するのにキャッシュコヒーレンシーやアクセラレーターサポートなどがいろいろあるからCXLのほうが都合が良かった一方、現在のCXLはPCIeを前提に構築されているので、そのままでは互換性がない。なのでCXLをFDI向けにカスタマイズしたのがiCXLで、結果としてCXLそのものとは互換性がないよ」ということだそうだ。
それにしてもそれぞれの接続本数は1000本とか2000本になっているわけで、なかなかの帯域である。実際にはデファレンシャル・シグナルで、しかも双方向接続だろうから、SoCタイル⇔CPUタイルは実際には512bit分。これを2つのIDIで利用するから1つあたり256bit幅になるが、仮に信号速度が2GHzだとすると帯域は64GB/秒ほど。メモリーが仮にDDR5-6400だとしてちょうど1ch分にマッチする格好だ。おそらくメモリーも2chだろうから、IDI×2でちょうどいい具合になるわけだ。
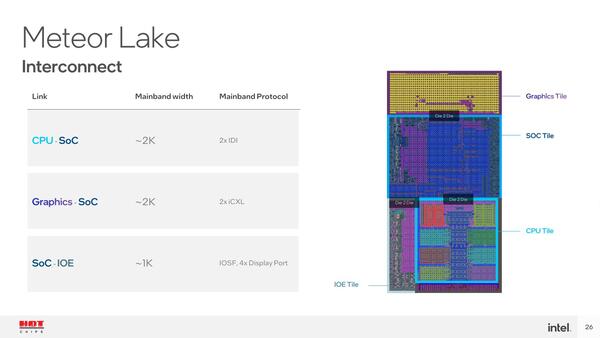
この図を見るとCPUタイルはP-Core×6+E-Core×8(4コアのクラスター×2)に見える
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ














で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






































