




重要な役割を果たすバイパスコンデンサー
ここで基本的な回路の話をしておこう。パスコン、いわゆるバイパスコンデンサーというものはものすごく広く利用されており、特に昨今のCPUやGPUなど大電流を要求するチップでは欠かせないコンポーネントである。このバイパスコンデンサー、役目としては2つある。
1つは供給電源ラインに混在した高周波ノイズの除去。回路は当然直流電流が来ることを想定して組まれているが、ここに高周波ノイズが混入することがあり得る。そこで回路の手前にコンデンサーを入れてやることで、高周波分をGND側に流し、回路に安定した電圧を供給するというものだ。
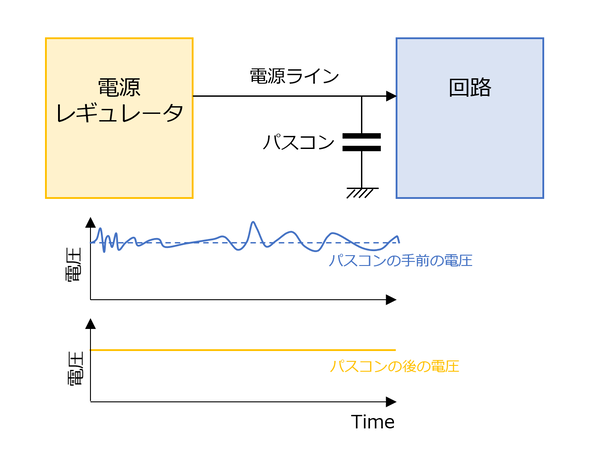
回路の手前にコンデンサーを入れて、電源ラインに混在した高周波ノイズをGND側に流すのが、バイパスコンデンサーの仕事だ
この際、パスコンと回路の間で改めてノイズが混入することを防ぐために、パスコンはなるべく回路に近いところに入れるのが原則である。
もう1つが不足する電流供給を補うというものだ。例えば回路がフルに動き始めると、必要になる電流が増えることになる。この場合、電源回路に対して供給電圧を増やすように要求し、これを受けて電源側が供給電力を増やすことになるのだが、どうしてもリクエストをだしてから実際に電流が増えるまでの間にタイムラグが生じる。
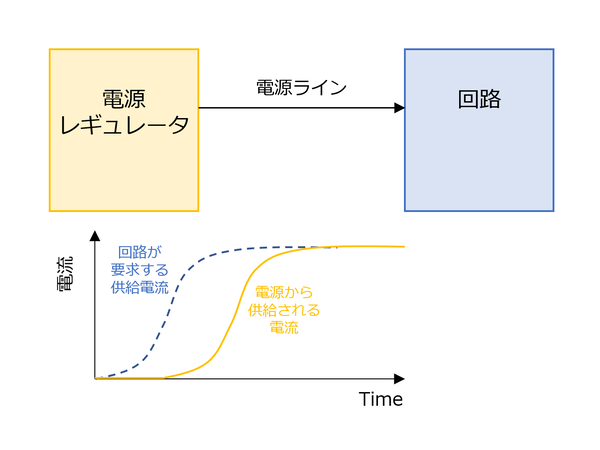
電流供給の遅れは、特に高速動作する回路では致命的になりかねない
このタイムラグの間、つまり実際に供給電流が増えるまでの間は、回路はフルに動かせない。ところが電源と回路の間にパスコンを挟んだ場合、仮に電流が足りない間はパスコンから不足分の電流を一時的に供給できる。この結果、電源からの分とパスコンからの分の合計で、回路にはかなり要求に近い電流が供給されることになり、回路はそれほど待ちがないままにフル稼働できるようになる、というものだ。
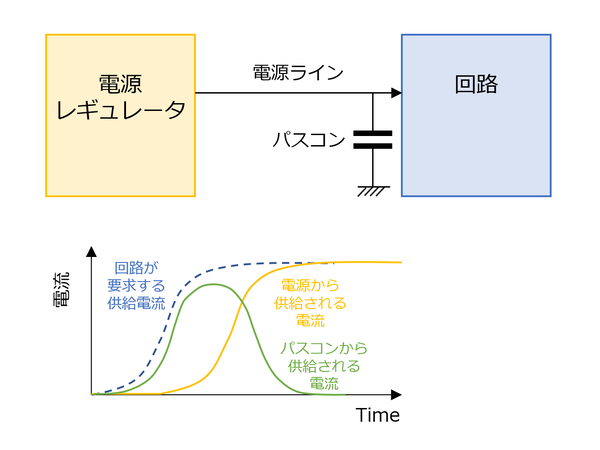
電流供給を補うのもパスコンの仕事である
ちなみにコンデンサーなので、一度放電すると次は蓄電のモードに入るわけだが、放電しきったころにはすでに電源回路から十分な電流が供給されているので、これを利用して次の放電に備えた蓄電ができるわけである。
ちなみに上図では電流の変化として説明したが、通常電流が増えるのは電圧を増やした場合である。つまり、回路が必要とする電圧と、実際に供給される電圧が一致していない間はパスコンから回路に電流が流れ、電源回路の側が電圧を上げていくにつれパスコンからの供給は減っていき、パスコン自身の蓄えた電圧より電源からの電圧が高くなったらパスコンは蓄電に切り替わるという仕組みになっている。
こういう性質のものだから、CPUのように高速な回路にパスコンは欠かせない。連載398回でRyzenのMIMCapを説明したが、なるべく回路に近いところになるべく大きなパスコンを配せば、それだけ高速動作がやりやすくなることになる。
ということで話をBOWに戻す。前のページのBOW模式図をもう少しわかりやすくしたのが下図である。
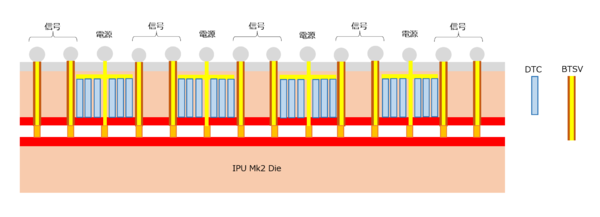
電源ピンは、BTSV経由でC4 Bumpにつながるが、ウェハー内に構築されたDTCベースのパスコンと接続されている
IPU Mk2 Dieから出て来た信号ピンは、そのままBTSV経由でC4 Bumpに接続される。一方で電源ピンに関しては、もちろんTSV経由でC4 Bumpにつながるのだが、その途中にウェハー内に構築されたDTCベースのパスコンと接続されている構成だ。
これにより、回路の非常にそばに、ほぼIPU Mk2と同じ容積を持つパスコンが接続されているということになる。もともとIPU Mk2は823mm2と巨大なダイであり、周囲にパスコンを配しているとは言え、ダイ中央付近の電源ピンに関してはどうしてもパスコンからの距離が長くなるから、効率は悪い(それもあってパッケージ中央にBallを置かず、ここにパスコンを配する例もいくつか存在する)。
ところがBOWの方式だとすべての電源ピンに対して結構な大容量のパスコンを配することができるので、動作周波数をより引き上げても電力不足に陥ることがなくなる、というわけだ。
この方式のメリットは、追加するウェハーの方は先端プロセスである必要がまったくないことだ。つまりBTSVとDTCを構築するだけなので、28nmである必要すらなく、40nmや55nmあたりでも十分お釣りがくる(ひょっとすると90nmあたりかもしれない)。
ウェハーの製造コストは40nmだと7nmの1/4、65nmだと1/5、90nmだと1/6程度に収まっている。もちろんSoIC WoWで重ね合わせをするのに追加のコストは必要になるが、そもそも配線ピッチがC4 Ballと同じなので、AMDの3D V-Cacheに比べると精度的にはるかに緩いわけで、追加コストはそう多くない。
今回Graphcoreが、BOWは追加コストなしで提供すると発表したのも、この方式なら非常に安価に実装できるからということの裏返しと考えていい。ついでに言えば、これによりIPU Mk2と比較して10%前後の性能/消費電力改善が実現したというのもメリットの1つである。
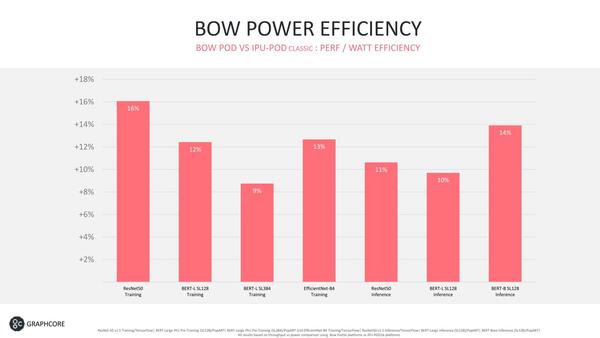
電力供給が改善したことで、電圧を無理に上げなくても動作周波数を上げやすくなったことがこの効率向上につながったと考えられる
ちなみにパッケージとしては上図が上下逆になった形で実装されるので、ヒートシンクの真裏に回路層が来るわけで、ここは以前と同じである。また基板に逃げる熱についても、BTSV経由で放熱できるので、特に悪化はしていないと考えられる。この技法、Graphcore以外にも採用されそうな感じだ(特許をGraphcoreとTSMCのどちらが持っているか次第だが)。
このBOWは、従来と同じように4チップを収めた1Uのブレードサーバーの形で提供されるが、最小構成のBOW POD 16(16チップ)~BOW POD 1024(1024チップ/16ラック)までが用意され、同日から出荷開始とされている。

BOW-2000というのは1Uブレードサーバーの商品名。1つのBOW-2000に4つのBOW IPUが搭載されている
前回の記事の最後で、5nm世代に移行するだろうと予測したが、いろいろな意味で予測が裏切られた格好だ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ











、バッテリー駆動時間は13時間超え。もう欲しくなる要素しか見つからないッ!")








ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")
















