




連載673回でも触れたが、インテルはようやく初のEUV(極端紫外線)露光を採用したIntel 4プロセスの詳細を、6月に開催されたVLSIシンポジウムで発表した。
まだ開催されてから時間が経っていないこともあって、IEEEのサイトには論文が掲載されていないが、今月中には公開されると思われる。今回は論文の方ではなく、実際に講演した際の資料をベースに、これを説明していく。
22年間で10ノードを開発した
インテルプロセスの歴史
まず簡単におさらい。下の画像がここ20年ほどのインテルのプロセス一覧である。2000年から2022年の22年間で10ノードなので、ノードあたり2.2年ほどという見方もできるが、10nm/10nm SuperFin/Intel 7が事実上同じノードと考えると実質8ノード、ノードあたり3年弱となる。22nmまでは2年おきに刷新されていたわけで、14nm以降が11年かけて4ノードとみるとやはりノードあたり3年と、やはり刷新のペースが落ちていることは否めない。
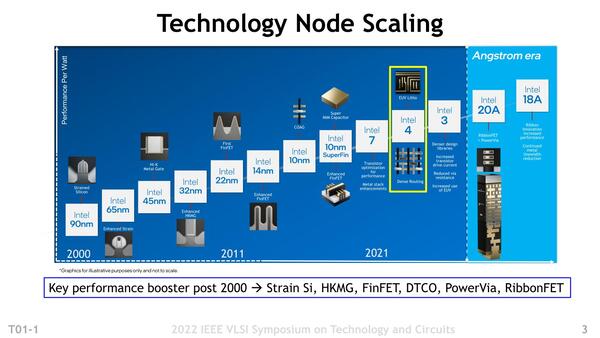
インテルのプロセス一覧
厳密に言えばインテルの14nm世代は14nm/14nm+/14nm++があった。非公式な分まで含めると、Broadwellの前に開発していた14nm-相当があったり、Comet Lakeは実は14nm+++ではないか? などいろいろ突っ込みはあるし、Intel 10nmはIce Lakeの製造のものを指すと思われるが、その前にCannon Lakeの製造に使ったIntel 10nm-が闇に葬り去られているなどもあるのだが、そうした話はおいておく。
Intel 10nm SuperFinはいわばIntel 10nm+だし、Intel 7は当初はIntel 10nm Enhanced SuperFinと呼ばれていたことを考えると、実質的には10nm++に相当する。Intel 10nmはTSMCで言えばN7プロセスに相当する格好で、10nm SuperFinはN7P相当だろうか。
ただTSMCはN7+/N6に関してはEUV露光に切り替えているので、その意味ではIntel 7はN7+/N6相当とは言いにくい。強いていうならN7P+あたりに相当する格好だろうか。対してN4は、インテルとしては初のEUV露光を採用したプロセスで、TSMCのN5が競合ということになる。次のIntel 3がN5P、あるいはN4相当というあたりになるかと思われる。
Finの数を4本から3本に減らして
小型化に成功したIntel 4
そのIntel 4の特徴は以下のとおりだ。
- ライブラリーの小型化によってトランジスタ密度を2倍に向上
- EUVをトランジスタ層+配線層5層に適用
- 同じ消費電力なら最大20%以上の動作周波数向上
- EMIB/FOVEROSを引き続き利用可能

Intel 4の特徴。ちなみにEMIBやFOVEROSとの親和性の話は今回具体的なものがなかった。これはそのうち、HotChipsかどこかで説明されるだろう
もう少しこれを細かく説明したい。まずトランジスタ層の話だ。Intel 7からIntel 4では大幅に微細化が進んだ。

ちなみに左右のセルとの間に入るDiffusion Blockは、Intel 10nmの時点でSDB(Single Diffusion Block)になっている
Contacted Poly Pitch、図で言えば縦方向の配線間隔は54nm/60nmから50nmへ、Fin Pitch、図で言えば横方向の灰色で示されるFinの間隔は34nm→30nmへ縮小された。これに加えてDiffusion Grid(後述)は2 Finから1 Finに半減したほか、トランジスタの基本構成が4 Finから3 Finに減っている。
この結果として、PMOSとNMOSの2つのトランジスタ(両方を組み合わせることでCMOSが構成される、と言う話は連載236回で説明した通り)からなる最小構成(おそらくこれはインバーターの回路)の面積は、ほぼ半減したとされる。
次がCOAG(Contact Over Active Gate)。つまりトランジスタ層の上にあたるM0層との接続箇所をどこに置くかという話である。

Active Gate、つまり回路の内部に置くことで余分な面積を削減するというものだが、これはこれで難易度が高かった
2017年のTechnology and Manufacturing Dayにおけるスライドでは10nm世代で導入するはずだったが、実際に導入したのはIntel 7、つまり10nm Enhanced SuperFin世代だったようだ。Intel 4は第2世代ということになっているが、これは新しい配線ピッチに合わせたというわけで、基本的な技法になにか変化があるわけではないようだ。
一方で先ほども触れたDiffusion Gridは、NMOSとPMOSのトランジスタの間を、これまでだと2Fin分空けていたのを1Finに詰めた、という格好である。
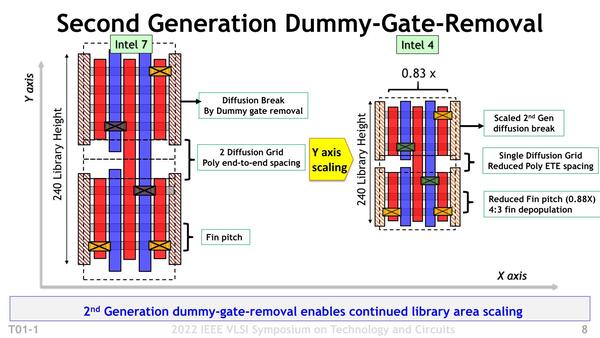
Diffusion Gridの間隔が2Fin分から1Fin分に詰まっている。ちなみにこの左側、Intel 7の方が“240 Library Height”となっているが、これは“480 Library Height”の誤りと思われる
加えて(先にも指摘したが)、Finの数を4本から3本に減らしている。Finの数を減らしても十分な駆動電力が達成できるので、その分面積を小型化できるわけだ。
これはインバーターでの話なので、どんな回路でも面積を半分にできるというわけにはいかないにしても、同じダイサイズならIntel 7からIntel 4で大幅にトランジスタ数を減らせることになる。これはMeteor Lake以降の製品で、よりCPUコアの数を増やしたりアクセラレーターを導入したりといったシーンで効果的であろう。
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ


















































")












