



ロードマップでわかる!当世プロセッサー事情 第673回
インテルがAIプロセッサーに関する論文でIntel 4の開発が順調であることを強調 AIプロセッサーの昨今
2022年06月27日 12時00分更新

今年6月13日から開催されたVLSI Symposium 2022はいろいろ話題が多く、例えばインテルはIntel 4の詳細を公開していたりする。この話はまた改めてきちんと説明するが、インテルは今回全部で15もの発表を行なっている。もっともこの中にはShort Course(技術講座)の分も含まれているので、論文そのもので言えば12本となっている。
論文の中に、“[C08-1] An 8-core RISC-V Processor with Compute near Last Level Cache in Intel 4 CMOS”と呼ばれるものがある。これだけ見ると「Intel 4プロセスを使ったRISC-Vコア?」ということでちょっとびっくりしたのだが、中を見ると「そりゃRISC-V使った方が楽だよね?」という、分類としてはAIプロセッサーに属するものだった。
これはあくまで研究レベルの話で、そのまま製品になることはなく、将来のx86プロセッサーに応用される「かもしれない」レベルの話であるが、なかなかおもしろかったので解説したい。
Intel 4プロセスのAIプロセッサー
さてこの論文であるが、タイトルの中で重要なのは“An 8-core RISC-V Processor”でも“in Intel 4 CMOS”でもなく、“with Compute near Last Level Cache”である。要するに分類としては、連載668回でも触れたPIM(Processor In Memory)の延長にある。
ただPIMはメモリベンダーには容易なソリューションなのだが、そうでないとまずメモリーを構築するところから始まるので大変である。これに対して、Last Level Cacheは、インテルで言えば3次キャッシュに演算ユニットを突っ込むのはそれほど大変なことではない。
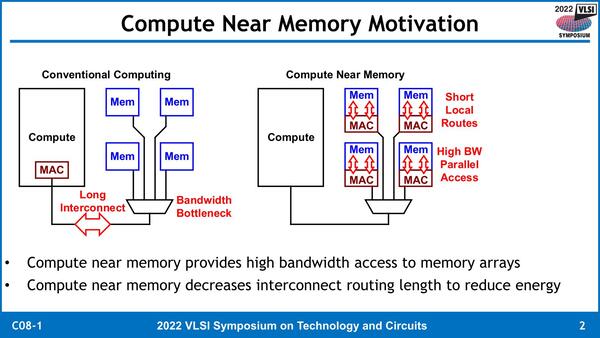
左は現在のインテルのプロセッサーの構成で、右が今回提案する方式である
さて、もうすこし厳密にCompute Unitをどこに入れるか? を検討したのが下の画像だ。CPUコア内に置くのが一番悪手というのはわかるとして、アクセラレーター/LLC/DRAMのどこで置くのがベターか? というのはエネルギー効率、容量、帯域の観点でトレードオフの関係になる、としている。
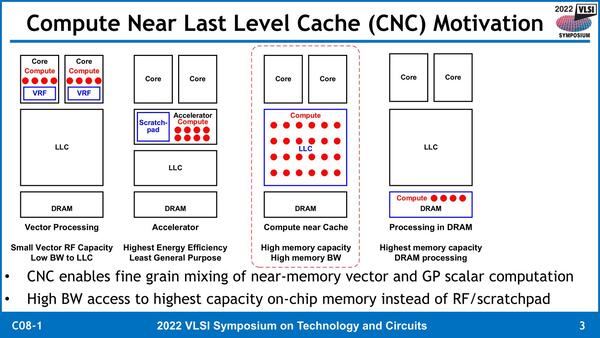
アクセラレーター方式が一番汎用性が低い、というのはやや怪しい気はする。ただエネルギー効率は(ScratchPadを使って処理を行なう限りは)一番効率が高いだろう
インテルは今回、LLCの中にCompute Unit(CNC)を実装することで、それなりに高い演算性能とメモリー帯域・容量をバランスよく利用できるようにする選択肢を選んだ格好だ。
この効果を試すためのプラットフォームとしてインテルはRISC-Vコアを選んだ。この構図はCoreアーキテクチャーのRing Busを彷彿させるが、厳密にはRing Busではなく2D Meshの構成になっている。8つの64bit RISC-Vコアに、それぞれ64KBのSRAMとCNCを組み合わせて配する格好で、2次キャシュ(今回の構成はRISC-VはL1 I/D-Cacheのみ搭載されている)の合計は512KBになる。なんというか非常に小規模なコアである。

x86ではL3にCNCを入れる格好になるだろうから、CNCの効果を確かめるのはやや面倒くさいのは事実だ。あとx86に手を入れるのそのものが超面倒くさい、という話もある
ここに搭載されるCNCであるが、256bit幅の比較的単純なSIMDで、演算も可能なのはMAC演算のみである。命令も演算(MACCNC)以外にLLCからのロードとLLCへのストアー(Load/Store)、CNC用のRF(Register File)への書き込みと読み出し(RDCNC/WRCNC)の5種類のみとなっている。
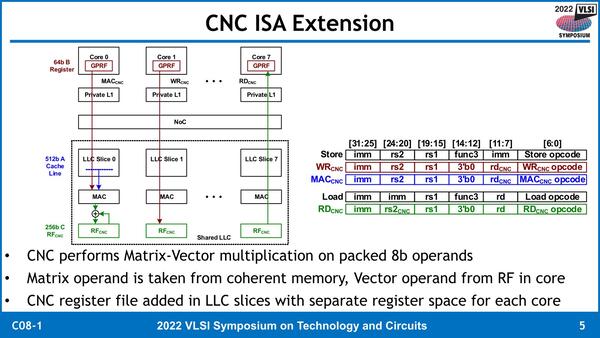
PIMに比べると、メモリーアクセスのコマンドパケットにあれこれ細工しなくても直接リクエストを出せるようにできるという意味では実装は楽だっただろう
もちろん演算そのものはCNCに隣接したLLCとの間でしか行なわれない形になっている。
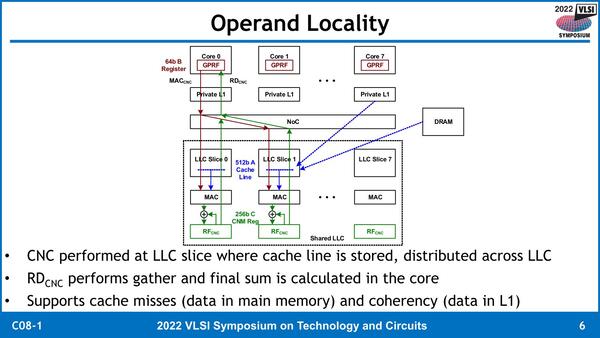
MAC演算を行なった後の総和は、RDCNC命令の中で取ることになっているというのがおもしろい。逆に言えば、総和を取るような演算しか想定していないということだろう
演算の詳細そのものはこちらのスライドでは明記されていないが、論文の方を読むと“CNC multiplies an 8×8 INT8 Matrix by an 8×1 INT8 Vector and accumulates the INT32 result in RFCNC”とあるので、INT8の8×8の行列と8×1行列の乗算を行ない、その結果をINT32としてCPUコアの側の汎用レジスターに送り出す、という処理をするとしている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ











、バッテリー駆動時間は13時間超え。もう欲しくなる要素しか見つからないッ!")








ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")
















