ロードマップでわかる!当世プロセッサー事情 第674回
Zen 5に搭載するAIエンジンのベースとなったXilinxの「Everest」 AIプロセッサーの昨今
2022年07月04日 12時00分更新

今回取り上げるのは、旧Xilinxが2018年に発表した、Versal ACAPに搭載されているAI Engineである。連載671回で説明したように、Xilinxを買収したAMDは、このAI EngineをXDNAというブランドでZen 5世代のCPUにも搭載すると発表したことで、このAI Engine(とその発展型)がAMDにおけるAIプロセッサーの基本となることが決まった格好だ。

汎用プロセッサーと専用アクセラレーターの良いとこ取りをした
XilinxのVersal ACAP
AI Engineの説明に入る前にまずVersal ACAPについて話したい。Versalは製品のブランド名、一方ACAPとはXilinxの造語でAdaptive Compute Acceleration Platformの略である。いわゆるFPGAとなにが違うのか? というと、ものすごく雑な言い方をすれば「FPGA+汎用プロセッサー+特定分野向けアクセラレーター=ACAP」ということになる。FPGAについては、ごく簡単に連載349回で触れたが、端的に言えば以下のような特徴がある。
- 自由にプログラミングできるハードウェアだが、そのプログラミングの敷居は超高い。
- 自由にプログラミングできる代償として、トランジスタ効率が猛烈に悪い(が、汎用プロセッサーよりはずっとマシ)
うまく使えば自身のアルゴリズムを実装して高速で動かすことが非常に簡単にできる。ただ、ある意味定型となった処理に関しては、専用アクセラレーターと比較して効率が悪い(その処理を実装するのに必要なトランジスタの数が1~2桁増えるし、またアクセラレーターよりも性能/消費電力比が悪い)という構成上やむを得ない特徴がある。ちなみに汎用プロセッサーだと以下のようになる。
- 自由にプログラミング可能で、FPGAに比べればプログラミングの敷居は超低い。
- 性能/トランジスタ比とか性能/消費電力比は非常に悪い。なので、性能が必要な用途には向かない一方、非常に複雑なロジックとか込み入った処理には向いている。
専用アクセラレーターなら以下のようになる。
- 特定の処理だけは超高速にできるが、それ以外のことはできない。
- 性能/トランジスタ比や性能/消費電力比は最高。
したがってACAPでは「これを全部入れてしまえ一番柔軟にできるのでは?」という、ある意味力づくのアプローチである。
さてそのACAPのアクセラレーター用に開発されたものがAI Engineである。もっとも2018年にVersalがEverestというコード名で初めて発表されたときは、まだAI Engineという名前ではなく、Software Programmable Engine(SW PE)という名称であった。
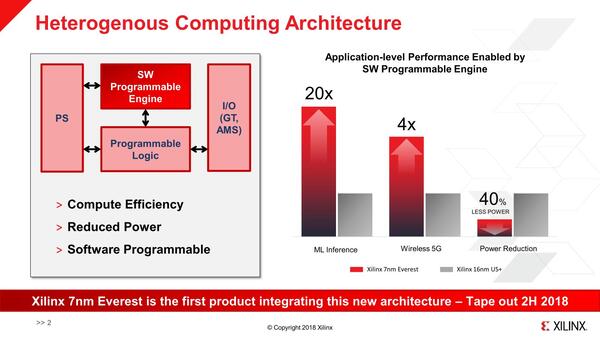
AI Engineの前身となるSW PE。専用アクセラレーターなのにソフトウェアプログラマブル? という話はまた後で。PSがCortex-AとCortex-Rを組み合わせた汎用プロセッサー、Programmable LogicがFPGAの本体で、I/Oが外部入出力となる
で、これを使うとなにができるのか? という話であるが、畳み込みニューラルネットワークの推論を実行する場合の例が下の画像である。
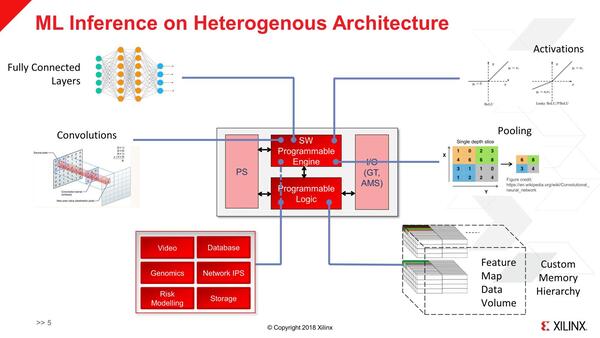
推論を実行する場合の例。PSはこの場合全体の制御だけをやる格好になる。これは、ネットワーク周りすらFPGAが分担するためだ
良くあるパターンで言えば、例えばカメラから画像を取り込んで、それに対して推論処理をかける形になるが、そうした場合の画像処理やストレージの管理、場合によってはネットワークの処理(監視カメラの場合、ネットワーク接続というのは珍しくない)などはFPGAで行なう。
一方で、さまざまなFeature Mapなどは外部メモリーに格納するが、これもFPGA経由で行なう(FPGA側にはDDRやHBMのI/Fが搭載されているため)。その一方で全結合や畳み込み、プーリングといった処理は、SW PEで行なうという形を想定している。畳み込みにしても全結合にしても、処理自体は非常にシンプルで単に乗加算だから、これをFPGAのLUTを費やして処理させるのは効率が悪すぎる。SW PEはこうした処理を効果的に行なうように設計されているわけだ。
この連載の記事
-
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 - この連載の一覧へ













